Persistent Volume Lifecycle: Available → Bound → Released → Failed (and how each state fucks you differently)
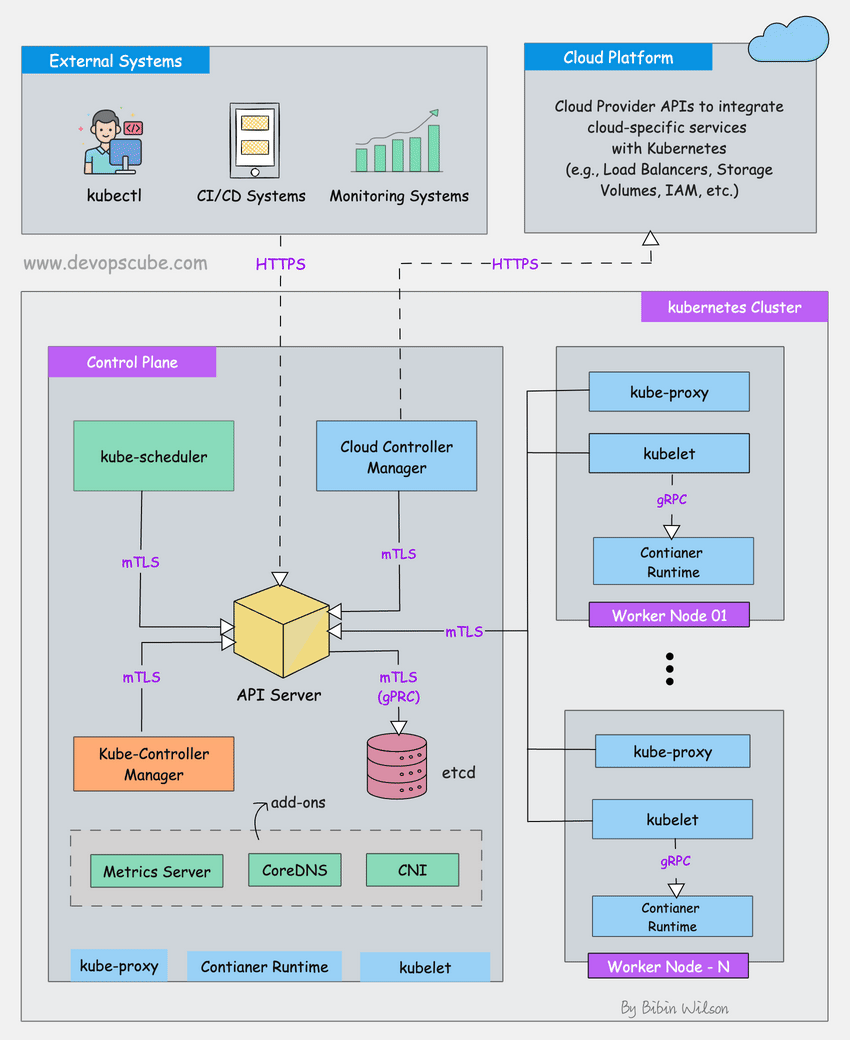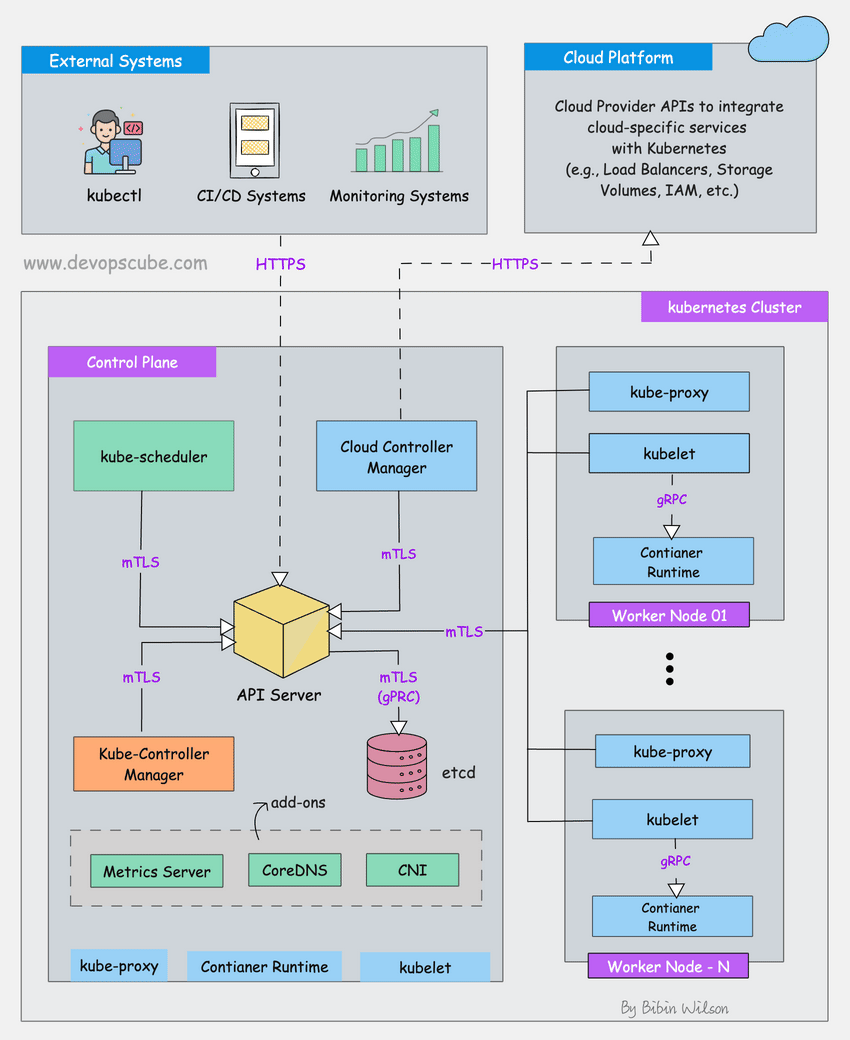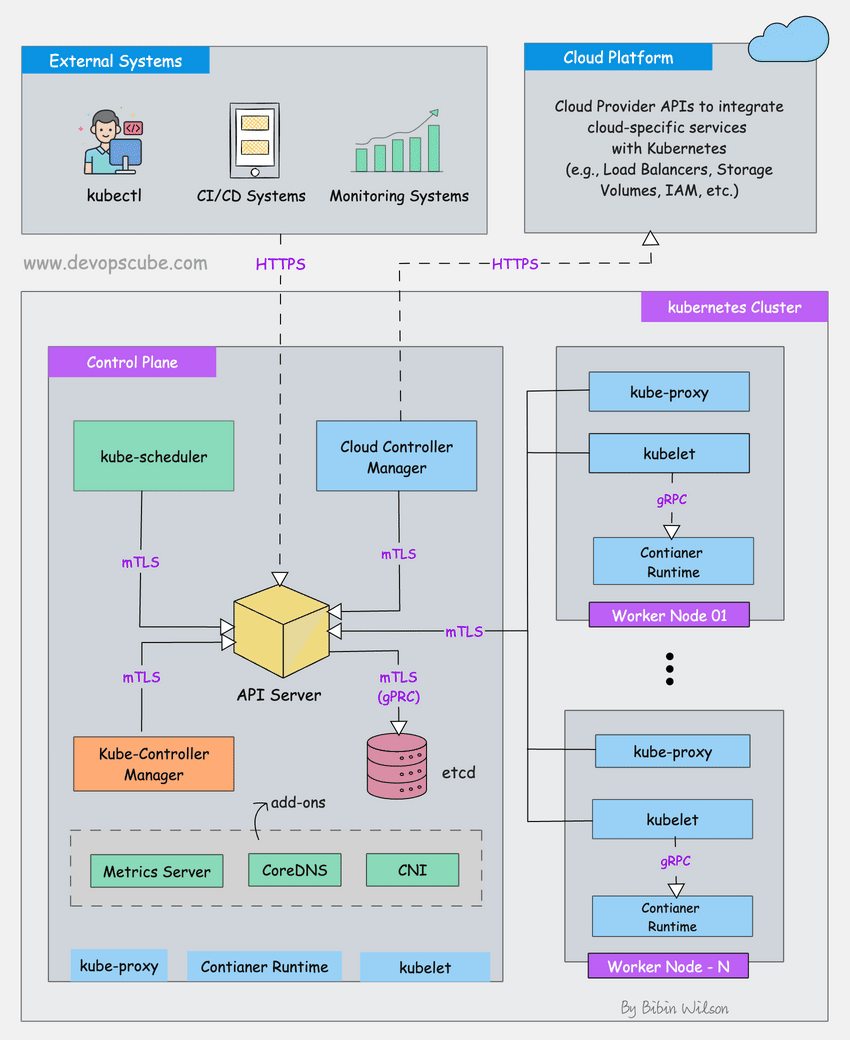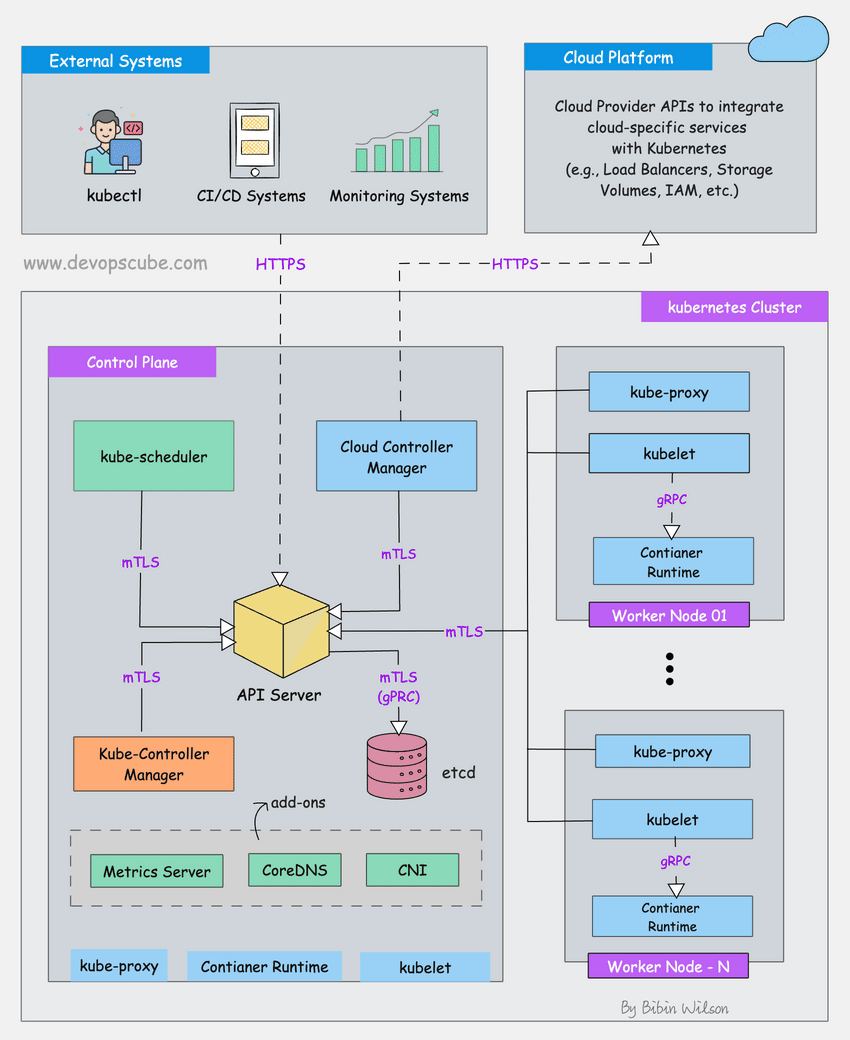
Kubernetes storage breaks for the dumbest reasons. I've been debugging this shit for 3 years, and here's what actually goes wrong and why the error messages are designed to waste your time.
The Persistent Volume Lifecycle (Where Everything Goes Wrong)
The PV lifecycle has four states: Available, Bound, Released, and Failed. The fun part? Your volumes get stuck in Released state constantly.
Here's what happens: Someone deletes a PVC but the PersistentVolume has reclaim policy: Retain. The volume goes into Released state - it keeps your data but becomes completely fucking useless for new claims. I've lost entire weekends debugging "no available volumes" errors when there's literally 500GB of storage just sitting there in Released state doing nothing.
The actual fix is simple but the error message tells you jack shit about it.
Storage Class Configuration Disasters
StorageClass → CSI Driver → Cloud Provider API → Actual Storage (and 47 ways this chain can break)
StorageClass misconfigurations will ruin your weekend. I've seen production outages caused by typos in StorageClass names. Here's the shit that actually breaks:
Invalid Provisioner Names: Typo in the provisioner field? Your PVCs will sit in pending forever. No error message. No indication why. Just pending. Forever. Like waiting for customer support to respond. Check your CSI driver names - the CNCF landscape has all the certified ones.
Parameter Screwups: AWS EBS needs type: gp3, not type: gp2 in 2025. Azure wants skuName: Premium_LRS. GCP uses type: pd-ssd. Get any of these wrong and you'll spend hours debugging cryptic provisioning errors. The AWS EBS types documentation explains which parameters work with which volume types.
RBAC Nightmare: Storage provisioners need specific cluster permissions. Missing one permission? Silent failure. The AWS EBS CSI driver needs like 15 different RBAC rules. Miss one and good luck figuring out which one because Kubernetes sure as hell won't tell you. The RBAC troubleshooting guide has debugging tips if you enjoy pain.
Production story from last month: failed to provision volume with StorageClass "fast-ssd": rpc error: code = InvalidArgument desc = invalid VolumeCapability: unknown access type UNKNOWN - turns out someone used accessModes: ["ReadWriteOnce"] instead of accessModes: ["ReadWriteOnce"]. The quotes matter in some CSI drivers.
Resource Limits That Will Bite You in the Ass
Cloud providers have limits that Kubernetes doesn't tell you about:
Node Attachment Limits: AWS EC2 instances can attach 28 EBS volumes max on Nitro instances. Hit this limit and your pods won't schedule. The error? FailedScheduling: node(s) had volume node affinity conflict. Helpful, right?
Zone Disasters: Pod scheduled in us-west-2a, volume created in us-west-2b? No mount for you. AWS won't attach cross-zone. Use volumeBindingMode: WaitForFirstConsumer or suffer. This GitHub issue has like 200 comments about it. The AWS multi-AZ guide explains cross-zone limitations in detail.
Quota Limits: AWS account quota for EBS volumes exceeded? You get failed to create volume: VolumeCreationError: Maximum number of volumes exceeded. But the AWS docs don't tell you this affects Kubernetes.
Backend Storage Full: I've seen NFS servers run out of space while Kubernetes shows "Available" StorageClass. The error: CreateVolume failed: rpc error: code = ResourceExhausted desc = Insufficient capacity. Kubernetes doesn't know your backend is toast. Set up storage monitoring to track backend capacity before it bites you.
Scheduling Conflicts (The Subtle Killers)
Pod → Scheduler → Node Selection → Volume Topology → Cross-Zone Attachment Failure (every damn time)
Pod scheduling gets complex when storage is involved. These will bite you:
Node Selector Hell: Your pod wants disktype=ssd nodes, but your PVC is bound to a volume that can only attach to disktype=nvme nodes. Deadlock. The scheduler documentation doesn't warn you about this. Use nodeAffinity rules for complex topology requirements.
Anti-Affinity Disasters: StatefulSet with podAntiAffinity can't schedule pod-1 because pod-0 is already on the only node where the volume can attach. I've seen this in production. The fix is ugly node taint juggling.
Topology Constraints: topologySpreadConstraints can force pods away from their storage. Kubernetes will choose topology compliance over storage affinity. Your pod sits in pending while its volume sits unused on the "wrong" node. The pod topology spread guide shows how to balance topology and storage requirements.
Permission Hell
Container permissions with volumes are painful:
File System Permissions: Container runs as UID 1001, volume owned by root. Result: permission denied everywhere. The fix? Add fsGroup: 1001 to your security context. Why isn't this the default? Nobody knows.
SELinux/AppArmor Nightmares: SELinux blocks your volume mounts with permission denied (audit: denied) in the logs. You need seLinuxOptions or fsGroup depending on the phase of the moon. Red Hat's docs are 47 pages long for a reason. The Pod Security Standards explain the security context requirements.
Container Runtime Chaos: Docker mounts volumes one way, containerd does it slightly differently. Migrate from Docker to containerd? Some of your volumes will break. This migration guide mentions it in passing like it's no big deal. Check the runtime comparison guide for specific differences.
Network Failures (The Invisible Killers)
CSI Controller → gRPC → Node Plugin → Kernel Mounts (when network hiccups kill everything)
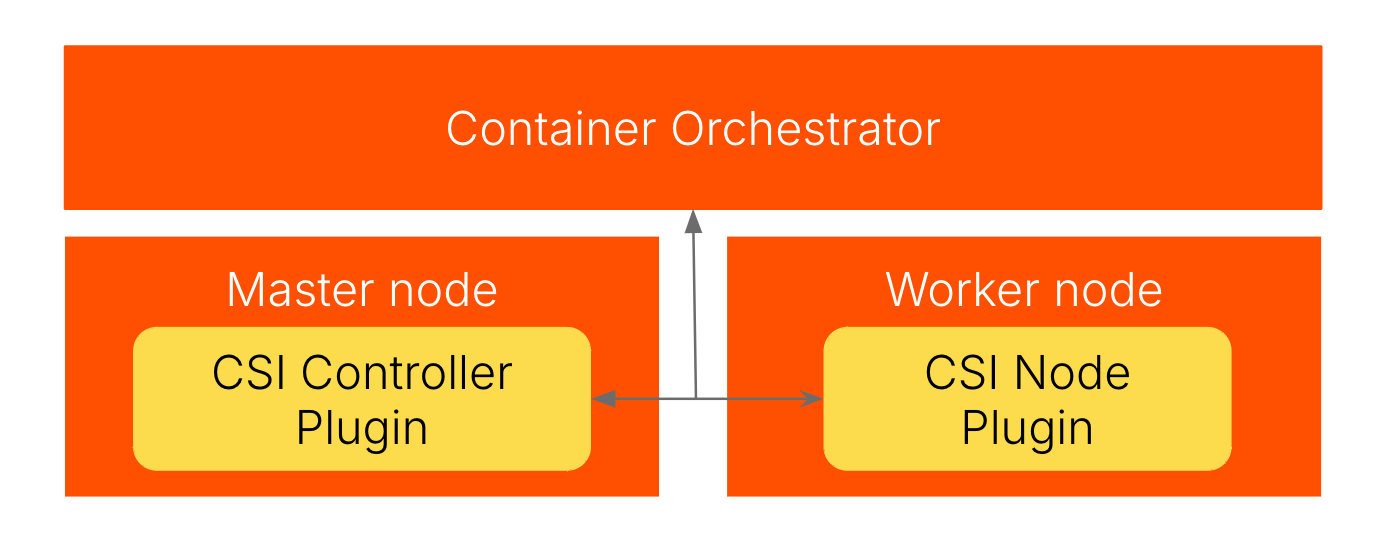
Network issues with storage are the worst to debug:
API Server Disconnects: CSI controller loses connection to API server for 30 seconds? Volumes get stuck in "Terminating" state for hours. This bug has been open since 2019. Configure API server high availability to prevent single points of failure.
Cloud API Rate Limits: AWS throttles your EBS API calls when you create 50 volumes at once. Half succeed, half fail. Now you have a split-brain clusterfuck. The AWS API docs mention rate limits but not what happens to Kubernetes. Use exponential backoff in your automation.
CSI Driver Bugs: Third-party CSI drivers are barely tested. The Longhorn driver has 500+ open issues. Half are "volume stuck in detaching state". Good luck. Check the CSI driver compatibility matrix before deployment.
This bit me in the ass when: I spent 6 hours debugging why new PVCs wouldn't provision. Turned out the CSI driver pod crashed and restarted in a different namespace, but the RBAC was namespace-scoped. No error messages. Just silent failure. I wanted to throw my laptop out the fucking window.
This isn't theoretical bullshit - these are the actual failures that will ruin your day. Like I mentioned earlier, the error messages usually lie to you, so the next section shows you how to diagnose which specific problem you're dealing with and how to fix it without losing your sanity.