
Look, I've been woken up at 3AM too many times by MongoDB replica sets shitting the bed. Let me save you some pain and show you how to set these up so they actually work when your traffic spikes.
What Replica Sets Actually Are (Skip If You Know)
Three MongoDB servers pretending to be one. One handles writes (primary), the other two copy everything and can handle reads (secondaries). When the primary dies, the other two vote on who becomes the new primary. Takes about 10 seconds in MongoDB 8.0, used to take 15+ in older versions.

The election process is where shit usually goes wrong. Network hiccups, resource exhaustion, or bad config can cause election storms where your cluster spends more time electing leaders than serving requests.
The Config That Actually Works in Production
Three nodes, different data centers. Period.
Don't get cute with single-AZ deployments unless you enjoy explaining to your boss why the database is down. We run:
- Primary: us-east-1a (m5.2xlarge, 32GB RAM, 1TB gp3)
- Secondary 1: us-east-1b (same specs)
- Secondary 2: us-west-2a (same specs, disaster recovery)
Total monthly cost on AWS: about $800 including storage. Atlas would be $1,200+ for the same thing, but you get backups and support included.
Don't use arbiters. Seriously. I see this recommended everywhere and it's garbage advice. Arbiters save you maybe $300/month but give you one less copy of your data. When your secondary dies and you're running on primary + arbiter, you're one failure away from total data loss.
Hardware That Won't Let You Down
Memory: Your working set MUST fit in RAM. If it doesn't, MongoDB becomes dog slow. We size for 2x our current working set because growth happens fast. Check the MongoDB memory requirements guide for detailed memory planning.
Storage: NVMe SSDs or you're wasting your time. We learned this the hard way when our replica set fell 30 seconds behind during a traffic spike because we cheaped out on spinning disks. See MongoDB storage recommendations for specific storage requirements.
Network: Gigabit minimum between nodes. 10Gb if you can afford it. Network latency over 10ms between replica set members will bite you during elections. Refer to MongoDB networking requirements for detailed network specifications.
CPU: 8+ cores. MongoDB is single-threaded for writes but uses multiple threads for everything else. Check MongoDB CPU recommendations for optimal CPU configurations.
MongoDB 8.0: Actually Worth Upgrading
MongoDB 8.0 fixed some annoying shit that was paging us regularly in 7.x:
- Elections finish in 8-12 seconds instead of 15-20 seconds
- Replication lag dropped from 2-3 seconds to under 1 second for our workload
- Memory usage is more predictable (fewer OOM kills)
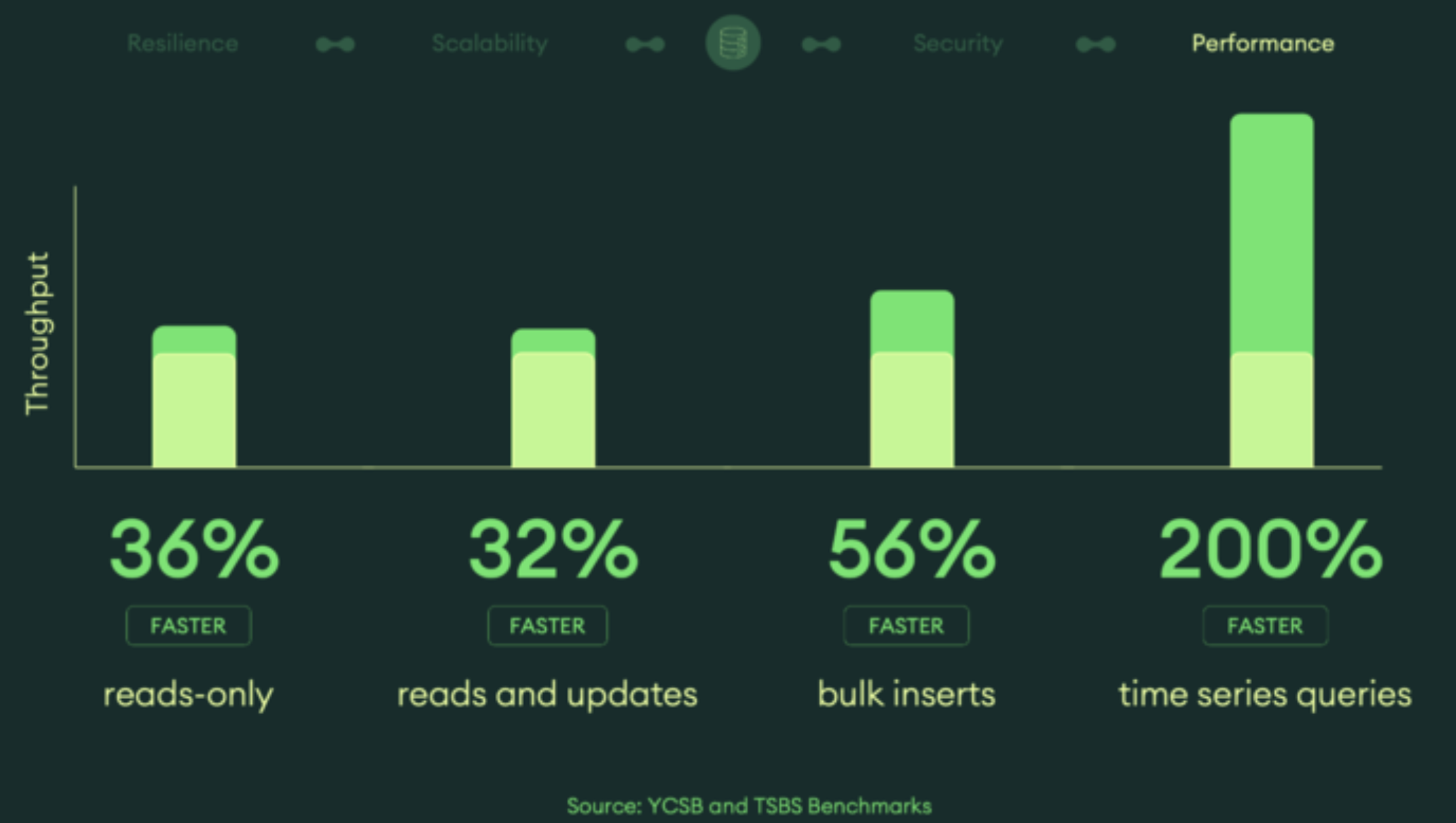
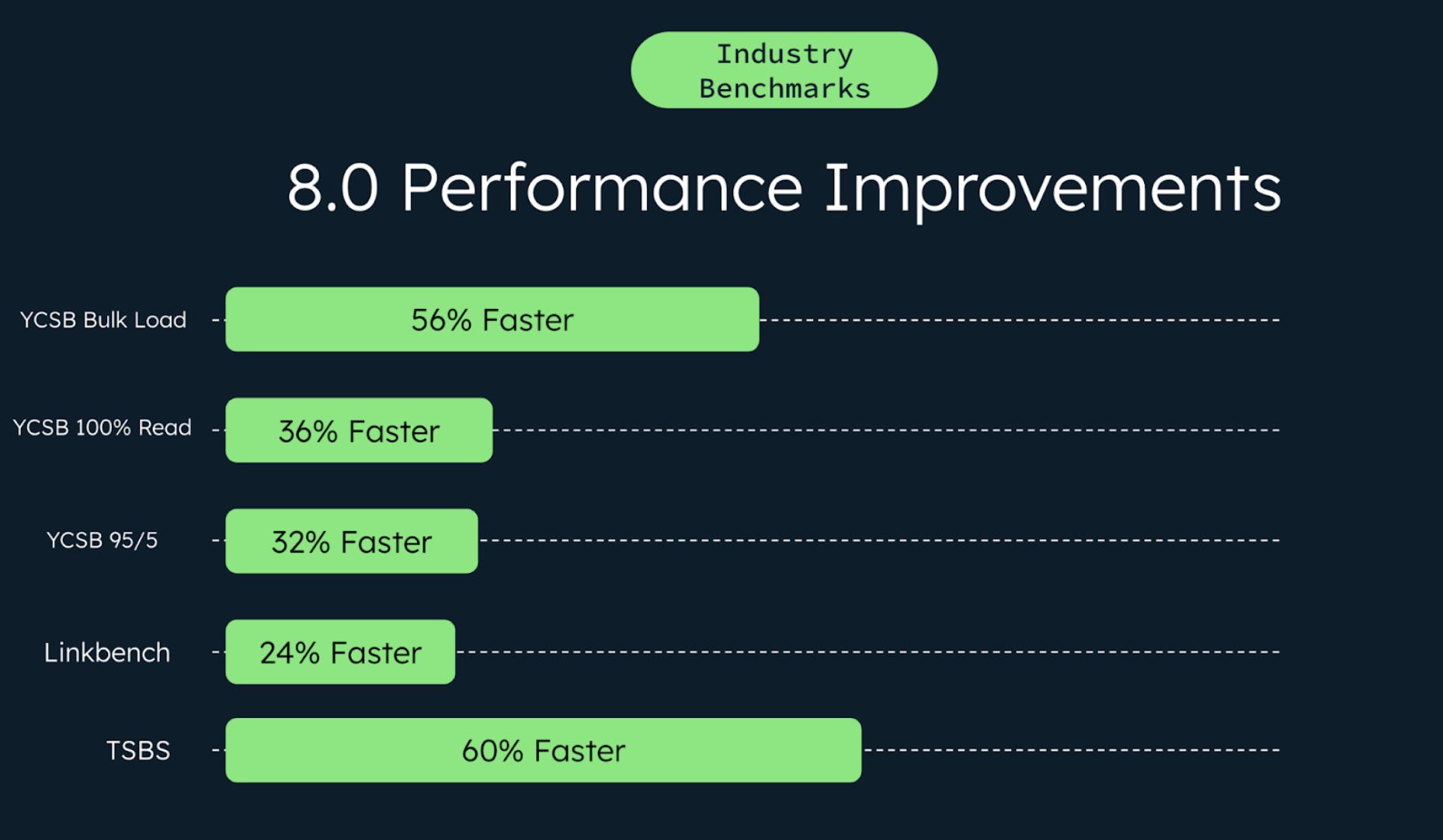
MongoDB 8.0 delivers massive performance improvements across all major workloads - 36% faster reads, 32% faster mixed workloads, and 56% faster bulk writes. These aren't marketing numbers; they're from actual benchmark tests using industry-standard YCSB and real customer workloads.
The upgrade from 7.0 to 8.0 took us a weekend with rolling restarts. Zero downtime, just had to deal with some connection pool churn during the restarts. Follow the MongoDB upgrade procedures for detailed upgrade steps. Also check the compatibility changes before upgrading.
Read Preferences That Don't Suck
primaryPreferred: Use this for most stuff. Reads go to primary unless it's overloaded, then failover to secondaries.
secondary: Only use this for analytics queries or stuff where stale data is OK. Your secondaries are usually 500ms-2 seconds behind the primary.
nearest: Sounds smart but can cause weird behavior if your app logic assumes consistent reads. Stick with primaryPreferred unless you have a specific use case.
We route all user-facing reads to primaryPreferred and analytics/reporting to secondary. Works well, just monitor replication lag or your reports will be stale as hell. Read more about MongoDB read preferences and read preference mechanisms for detailed configuration options.
Security (Or How Not to Get Pwned)
Authentication: Turn it on. Seriously. I've seen production MongoDB clusters running wide open on the internet. Don't be that guy. Follow the MongoDB authentication guide for proper auth setup.
## Generate a keyfile for internal auth
openssl rand -base64 756 > /etc/mongodb-keyfile
chmod 400 /etc/mongodb-keyfile
chown mongodb:mongodb /etc/mongodb-keyfile
TLS: Enable it between clients and MongoDB, and between replica set members if you're paranoid about network sniffing. See MongoDB TLS configuration for detailed TLS setup.
Networks: Put your MongoDB servers in a private subnet. Only allow access from your app servers. Use security groups/firewalls to lock it down. Check the network security recommendations for best practices.
Users: Create specific database users with minimal permissions. Don't give your app the admin password. Learn about MongoDB authorization and built-in roles for proper user management.
Monitoring That Actually Helps
What to monitor:
- Replication lag (alert if >2 seconds)
- Connection count (we max out around 500 concurrent)
- Memory usage (page faults = death)
- Elections (alert on any election - they should be rare)
Tools that work:
- MongoDB Compass for quick checks
- Prometheus + Grafana for historical trends
- PMM from Percona for detailed monitoring
- MongoDB Atlas built-in monitoring if you're using Atlas
- DataDog MongoDB integration for enterprise monitoring
- New Relic MongoDB quickstart for APM integration
![]()
PMM provides comprehensive MongoDB monitoring with real-time metrics, query analysis, and performance insights that actually help you debug production issues.
Don't monitor everything. We tried that and got alert fatigue. Focus on the metrics that indicate actual problems, not just "database is busy."
Key monitoring resources:
Common Fuckups and How to Avoid Them
Oplog too small: We size ours to hold 24 hours of writes. Default is 5% of disk space which might not be enough.
Mixed hardware: Don't put your primary on a beast server and secondaries on tiny instances. When failover happens, your new primary will be slow as shit.
Single AZ: Network outages happen. Don't put all your eggs in one availability zone.
No monitoring: You'll find out your replica set is having problems when your app starts timing out. Set up monitoring before you go to production.
The goal is a replica set that just works. Boring is good when it comes to databases.


