So you've built an amazing MERN app that works perfectly on localhost. Time to deploy, right?
Wrong. Your development environment is a lying piece of shit. Everything works perfectly in your cozy local setup with 32GB RAM and no network latency, then you deploy and suddenly everything breaks in ways that shouldn't be physically possible.
What Actually Happens When You Go Live
I've been doing this for 8 years, and I've seen the same pattern repeat itself. Developer builds amazing MERN app, works perfectly on localhost, deploys to production, then spends the next three days dealing with the same common deployment issues that hit everyone:
- MongoDB connections timing out under load (happens every fucking time)
- React builds failing because of memory limits in the CI pipeline
- Express.js apps crashing silently with no error logs
- Docker containers using 2GB of RAM when they should use 200MB
- SSL certificates that work fine until they randomly don't
- React 19's new Suspense behavior breaking existing loading states
- npm audit fatigue - everything has "critical" vulnerabilities that don't matter
Accept this now: production will break. Your job is building systems that don't completely explode when (not if) everything goes wrong at the worst possible moment.
Docker: Your Best Friend and Worst Enemy
![]()
Docker solves the "works on my machine" problem, but creates a dozen new problems. Here's what I learned the hard way:
Multi-stage builds are mandatory
Single-stage Docker builds for MERN apps will create 2GB+ images. This is stupid and slow. Multi-stage builds cut that down to 100-300MB:
## Frontend build - this will be huge temporarily
FROM node:18-alpine AS react-builder
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
RUN npm run build
## Production - just the static files
FROM nginx:alpine
COPY --from=react-builder /app/build /usr/share/nginx/html
## This nginx config is critical - default won't work with React Router
COPY nginx.prod.conf /etc/nginx/nginx.conf
The shit that always breaks:
- Node version mismatches: Development uses Node 24, production uses Node 22.8.0, something breaks. Pin exact versions:
FROM node:22.8.0-alpine(Node 22 LTS until late 2025) - Memory limits: React builds eat RAM. Set
NODE_OPTIONS="--max-old-space-size=4096"or watch your CI fail - Alpine Linux differences: Some npm packages don't work on Alpine. Switch to
node:22-slimif you hit weird errors - File permissions: Your containers run as root locally but not in production. This bites everyone eventually
MongoDB: The Database That Lies to You
![]()
MongoDB says it's web-scale. MongoDB lies. Here's what actually happens:
Connection pool exhaustion
Default Mongoose settings will fuck you over. Use this or suffer:
mongoose.connect(process.env.MONGO_URI, {
maxPoolSize: 10,
serverSelectionTimeoutMS: 5000,
socketTimeoutMS: 45000,
family: 4 // Force IPv4, IPv6 causes random timeouts
});
Memory usage explosion
MongoDB will happily use all your RAM for caching. In containers, this kills other processes. Set `wiredTigerCacheSizeGB` explicitly.
Real incident: August 2025, our MongoDB container hit the 512MB limit and started OOMKilling every 15 minutes. Took 3 hours to figure out the default cache size was 50% of system memory, not container memory. Solution: cacheSizeGB: 0.25 for a 512MB container.
Index disasters
Your 100-record dev database doesn't need indexes. Your production database with 100k+ records will crawl without them. Add indexes BEFORE you deploy, not after users complain about slow queries.
CI/CD: Automation That Sometimes Works

GitHub Actions is decent, but every MERN pipeline will hit these issues:
Random timeouts and failures
GitHub's runners sometimes just fail. Your pipeline needs retry logic:
- name: Install dependencies
run: npm ci
timeout-minutes: 10
# This will save you hours of confusion
Environment variable hell
Never put secrets in your code. Never put secrets in your Docker images. Use GitHub Secrets, but test them first - case sensitivity will bite you.
Deployment lag
Your CI says "deployment successful" but users still see the old version. CDN caches, browser caches, and load balancer health checks all add delay. Plan for 2-5 minutes between deployment and live changes.
The Monitoring You Actually Need
Forget APM tools for now. Start with basics:
- Health check endpoints:
/healththat checks database connectivity - Error logging: Winston with structured logs, not
console.log - Basic metrics: Response times, error rates, memory usage
- Alerts: When error rate > 5% or response time > 2 seconds
New Relic and DataDog are nice but overkill until you have real traffic. Start simple, then upgrade when you're actually making money.
What Works in Practice

After breaking production dozens of times, here's my current setup (updated for September 2025):
- Docker Compose for local development that mirrors production
- GitHub Actions with proper retry logic and timeout handling
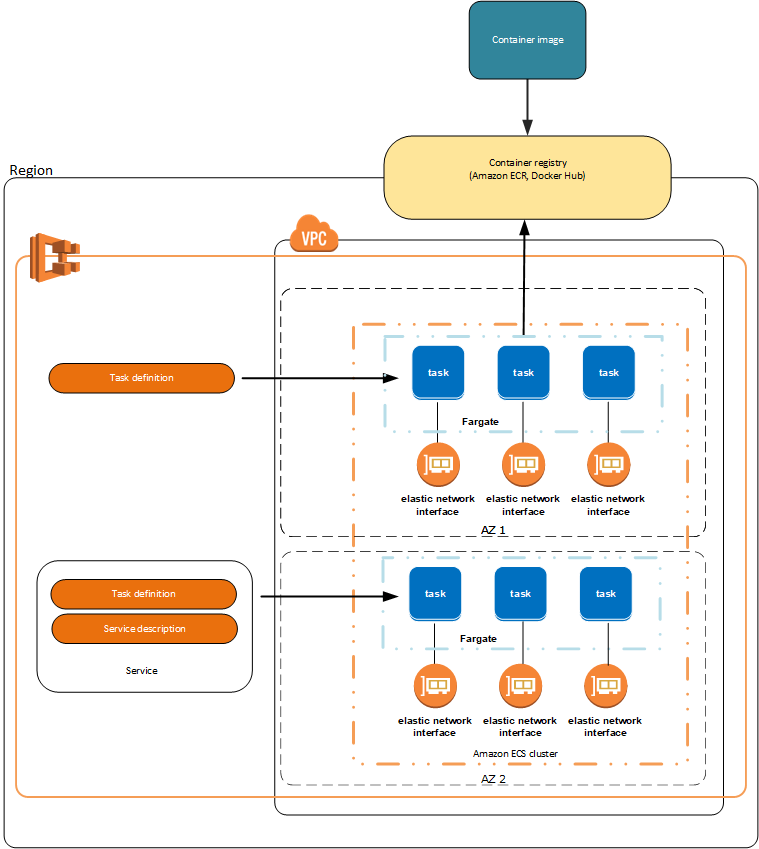
- AWS ECS because it's simpler than Kubernetes for MERN apps
- MongoDB Atlas because managing MongoDB yourself sucks
- CloudFront for React static assets
- Sentry for error tracking (it's cheap and catches frontend errors)
This setup handles 10k-100k users/month reliably. Scale up from here, don't start with Kubernetes unless you hate yourself.
Alright, you get the picture - everything's fucked. But here's the thing: once you know what breaks, you can build around it. Next section shows you exactly how to set this up so you're not the one getting paged at 3am.