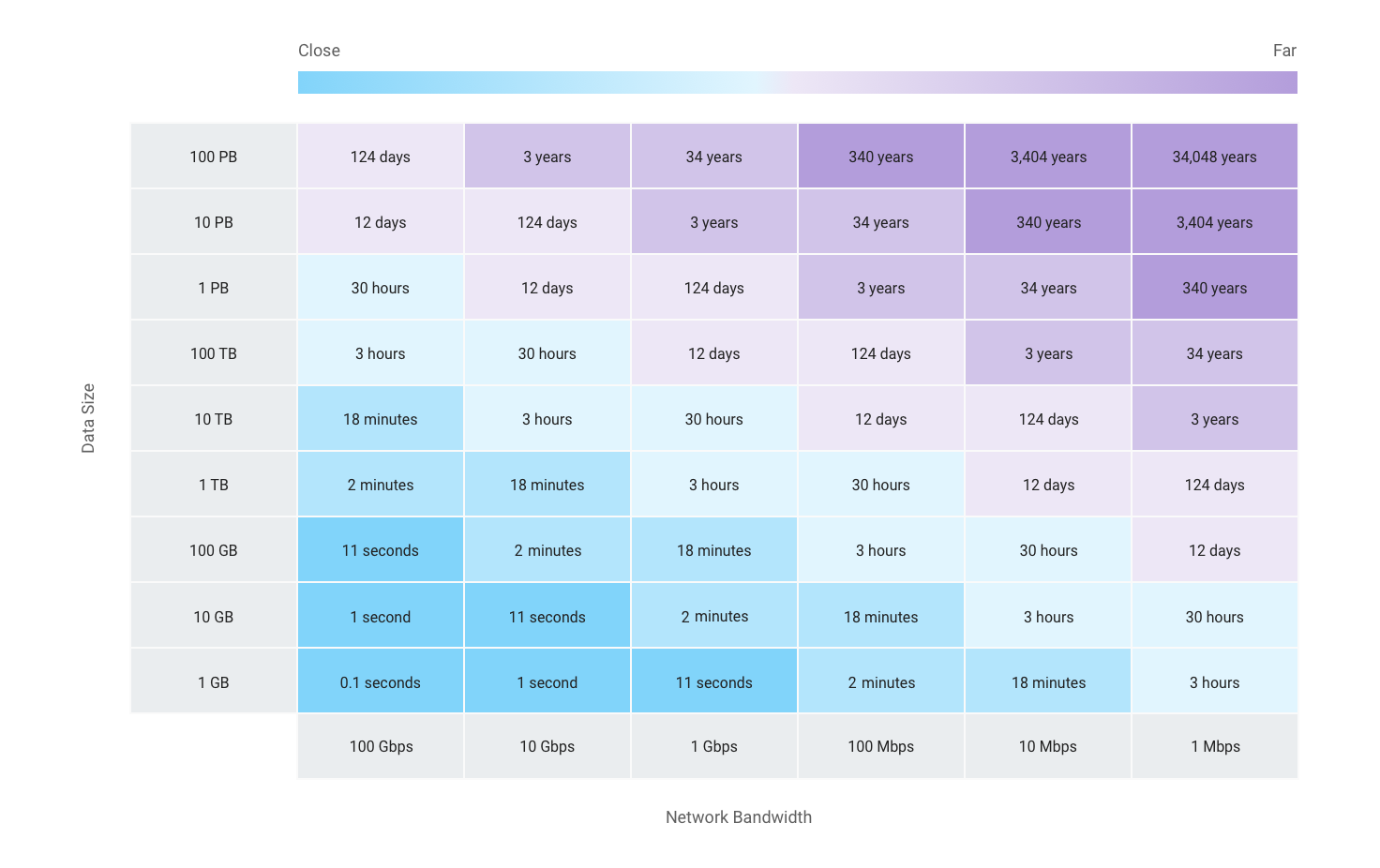
When you're staring at a 500TB migration from AWS to Google Cloud with a deadline that was set by marketing (because of course it was), you're about to learn why Storage Transfer Service documentation skips all the good parts.
Here's what Google's docs won't tell you: this thing works great until it doesn't. Every enterprise deployment hits the exact same edge cases, and Google's support team acts shocked every single time, like you're the first human to ever experience their bugs.
The Three Ways to Deploy This Thing

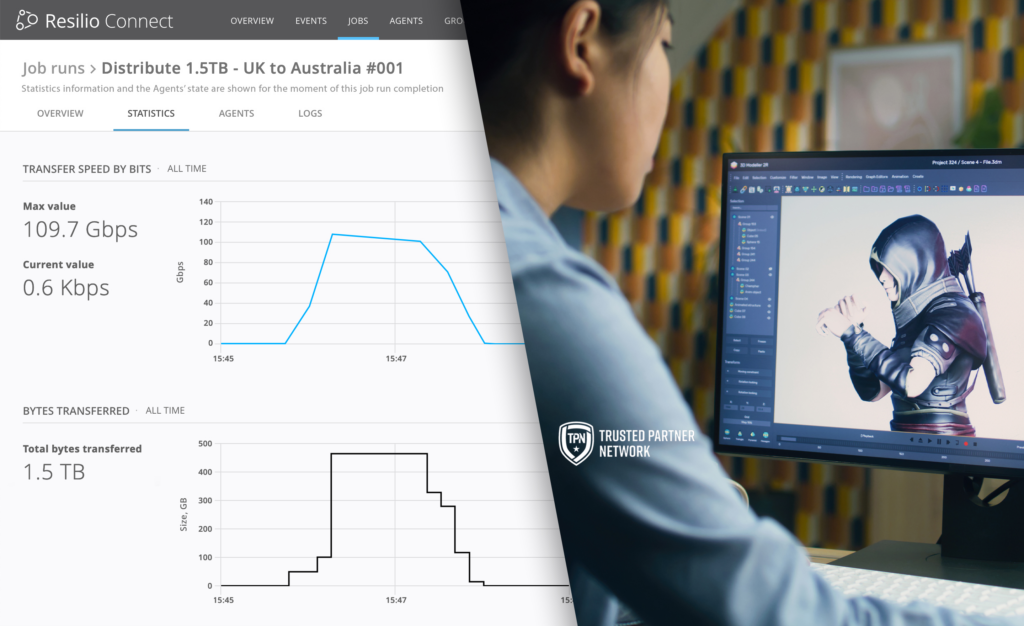
Centralized Architecture - Putting all your agent pools in one data center because "it's simpler" is like putting all your eggs in one basket, then paying someone to shake the basket. Works great until your UPS shits the bed and your 200TB transfer (I think it was 200TB? logs were fucked) starts over from zero. Took us 3 days to restart what should have been a 12-hour recovery.
Distributed Architecture - "Let's spread the failure points across multiple data centers" is management speak for "now everything can break simultaneously at 3am." Sure, it's more resilient, but good luck debugging when Dallas is throttled, Singapore is throwing SSL errors, and Frankfurt's proxy decided to reboot itself.
Multi-Cloud Compliance - This translates to "legal made us do it." Google waived egress fees for EU/UK folks as of September 2025, which helps your budget but not your sanity. Cross-cloud networking is still a nightmare where AWS blames Google, Google blames AWS, and you're stuck in the middle explaining to your boss why the migration is 3 weeks behind.
Network Configuration Challenges
Your Storage Transfer Service agents need outbound access to *.googleapis.com on ports 443 and 80. Security teams hate wildcard domains like vampires hate sunlight. They'll demand specific IPs, but Google's API endpoints change IPs more often than our intern changes his socks.
We spent 6 weeks in security review hell before they approved a DMZ with a dedicated proxy. That proxy went down more than a drunk college freshman - literally 40% uptime the first month because nobody bothered documenting how to restart the fucking thing properly.

Private Network Options - Google's managed private network option can save you $8k on that 100TB migration (AWS wants $9k to let your data escape, Google wants $800 to accept it). Only works with S3 though, so if you're on Azure you can go fuck yourself. Your network team will spend 2 weeks figuring out the routing and blame you when it doesn't work.
Bandwidth Management - Bandwidth limiting is like threading a needle while riding a motorcycle. Set it too low and your migration takes 6 months. Set it too high and your CEO's Zoom calls start cutting out, which is how you learn that executive video quality is more important than your data migration.
Security Theater and Real Problems
Secret Management - Secret Manager integration was added in June 2023, which is Google's way of saying "we knew hardcoded keys were bad but shipped it anyway." If you're on an older deployment, you've got AWS keys scattered across transfer configs like Easter eggs, and security auditors love finding those during compliance reviews.
IAM Complexity - The `roles/storagetransfer.transferAgent` role has more permissions than God. Security teams see it and shit themselves. Create custom roles and watch them break every time Google changes APIs (about monthly). Debugging IAM failures requires a PhD in Google's role hierarchy and the patience of a saint.
Audit Logging Challenges - Cloud Logging generates enough logs to clear cut a forest. Good luck finding why your transfer failed in 847GB of "file transferred successfully" messages. It's like finding a needle in a haystack, except the needle is also made of hay.
Scaling Operational Challenges
Managing agent pools across multiple data centers is like herding cats, if cats could randomly die and required VPN access to debug. Pool isolation sounds great until you're troubleshooting at 2am with SSH keys that expired, access to systems you've never seen, and agents that show "healthy" but aren't transferring shit.
Performance Considerations - Google optimizes for transfers over 1TB, which is like saying your car is optimized for highways but good luck in downtown traffic. Our 150TB migration was supposed to take 3 days. It took 2 weeks because half the files were thumbnails under 50KB. Small files make this service slower than a dial-up modem.
Monitoring Limitations - The Cloud Monitoring integration is about as useful as a chocolate teapot. It'll tell you the job is running but not why it's been stuck on the same file for 6 hours. You'll end up writing custom scripts with gcloud commands just to figure out what the hell is actually happening.
Cost Considerations and Planning
AWS charges $90/TB to let your data escape - that's $9k for 100TB compared to Google's $1,250 welcome fee. AWS basically charges you ransom money, but Google's private network option can bypass that extortion if your network team can figure out the routing without breaking production.
Scheduling Optimization - "Run it during off-peak hours" sounds smart until you realize AWS's off-peak is your peak, Google's peak overlaps with your maintenance window, and your data center's "quiet time" is when the cleaning crew unplugs random cables. Plus every other team had the same bright idea, so you're competing for bandwidth with 5 other migrations.
The Data Transfer Essentials program waives egress fees for EU/UK folks, but requires legal and technical teams to agree on something, which has about the same probability as winning the lottery twice.
Now that you understand the deployment patterns and their inevitable pain points, you're probably wondering about the specific problems you'll face. Every enterprise deployment hits the same roadblocks, and every engineer ends up asking the same desperate questions at 3am when everything breaks.
 Security teams see
Security teams see 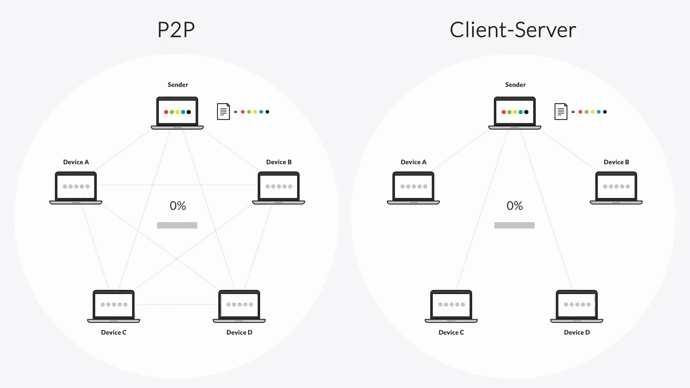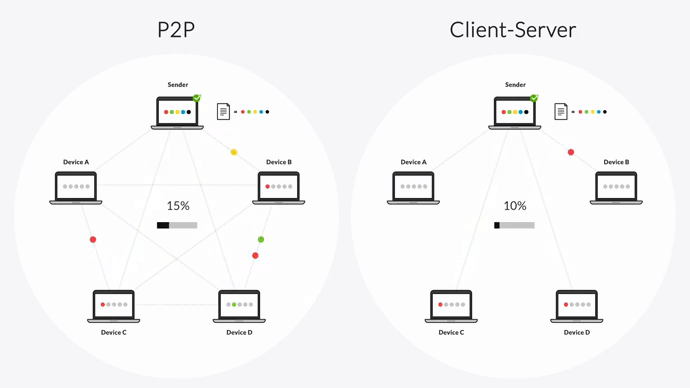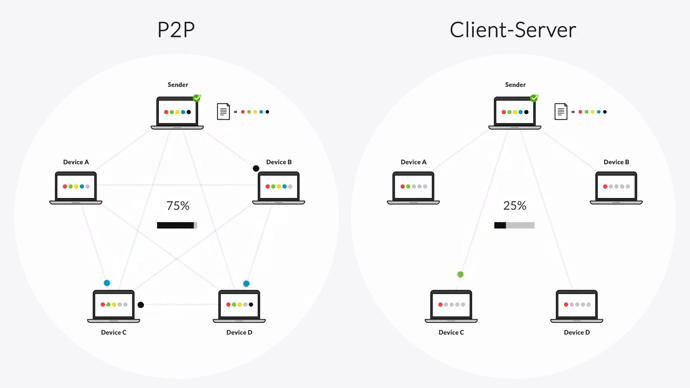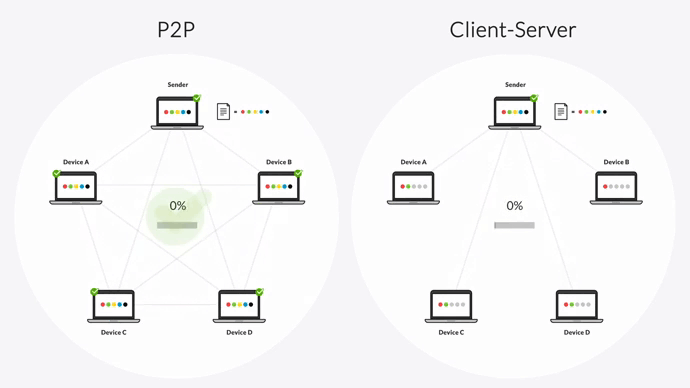 Your 200TB transfer that was 90% complete? Back to fucking zero. "Pause and resume" is marketing bullshit
Your 200TB transfer that was 90% complete? Back to fucking zero. "Pause and resume" is marketing bullshit