
Look, I've run enough of these migrations to know what really breaks vs. what the documentation pretends will work smoothly. Most transfers work fine if you know the gotchas, but I'd say about 1 in 3 large migrations hit some weird edge case that'll ruin your weekend plans.

Before you start clicking buttons in the console, run some basic commands to understand what you're dealing with. The Google cost calculator will lie to you, so get real numbers:
## Get actual file counts and sizes - du is your friend
du -sh /your/source/path
find /your/source/path -type f | wc -l
Hidden Files Will Screw You: That .DS_Store bullshit on macOS systems, Windows thumbs.db files, and Unix hidden directories starting with . - these add up fast. I once had a transfer size double because someone synced their entire Dropbox folder that was full of cache files nobody knew about. The worst part? Transfer Service counts each .DS_Store file as a separate operation, so your bill explodes.
Special Characters Are Pure Hell: Files with unicode characters, spaces, or special symbols will cause random failures. The error messages are completely useless, but here's what it actually means - clean your filenames first or suffer later. I had a transfer fail partway through because some designer saved files with emoji in the names. Fucking emoji.
Large Files Break Differently: Anything over 5GB starts hitting weird timeout issues. The service will retry, but I've watched 20GB database backups restart from scratch 4 times before finally completing. Split large files if possible, or budget 3x the expected time and some stress medication.
Agent Version Hell: Older agent versions can have memory issues that cause crashes during large transfers. Always run the latest agent version or your weekend migration becomes a month-long nightmare.
AWS Regions Are Not Created Equal: Performance varies significantly between AWS regions when transferring to GCS. I've seen major speed differences for identical workloads depending on the source region and time of day.
Network Planning (AKA Fighting With Your Network Team)
This thing will absolutely saturate your bandwidth and make everyone in your office hate you. Here's how I've learned to deal with it:
Bandwidth Limits Are Mandatory: Don't trust the "automatic optimization" - set explicit limits or you'll take down your office internet. I learned this when I killed everyone's video calls during an all-hands meeting. Start with 50% of your available bandwidth and adjust from there.
Firewall Rules Will Ruin Your Day: Expect to spend a day fighting with firewall rules. The agent needs specific outbound access to Google's APIs, and corporate firewalls love blocking these randomly. I spent 6 hours debugging connection issues only to find out our firewall was silently dropping connections with no logs.
VPN Connections Are Unreliable: If you're running this over VPN, just don't. The connection drops will drive you insane. I watched a 10TB transfer restart 8 times because our VPN kept dropping every few hours. Set up direct internet access or you'll lose your mind.
Quota Limits Will Blindside You: Google has operation rate limits per project that they don't advertise well. Hit them and your transfer slows to a crawl with zero explanation. File a support ticket to increase quotas BEFORE starting large transfers, not after.
Regional Performance Issues: Some region pairs have intermittent performance issues that cause random pauses during transfers. If you're hitting weird slowdowns, try a different source or destination region to see if that improves things.
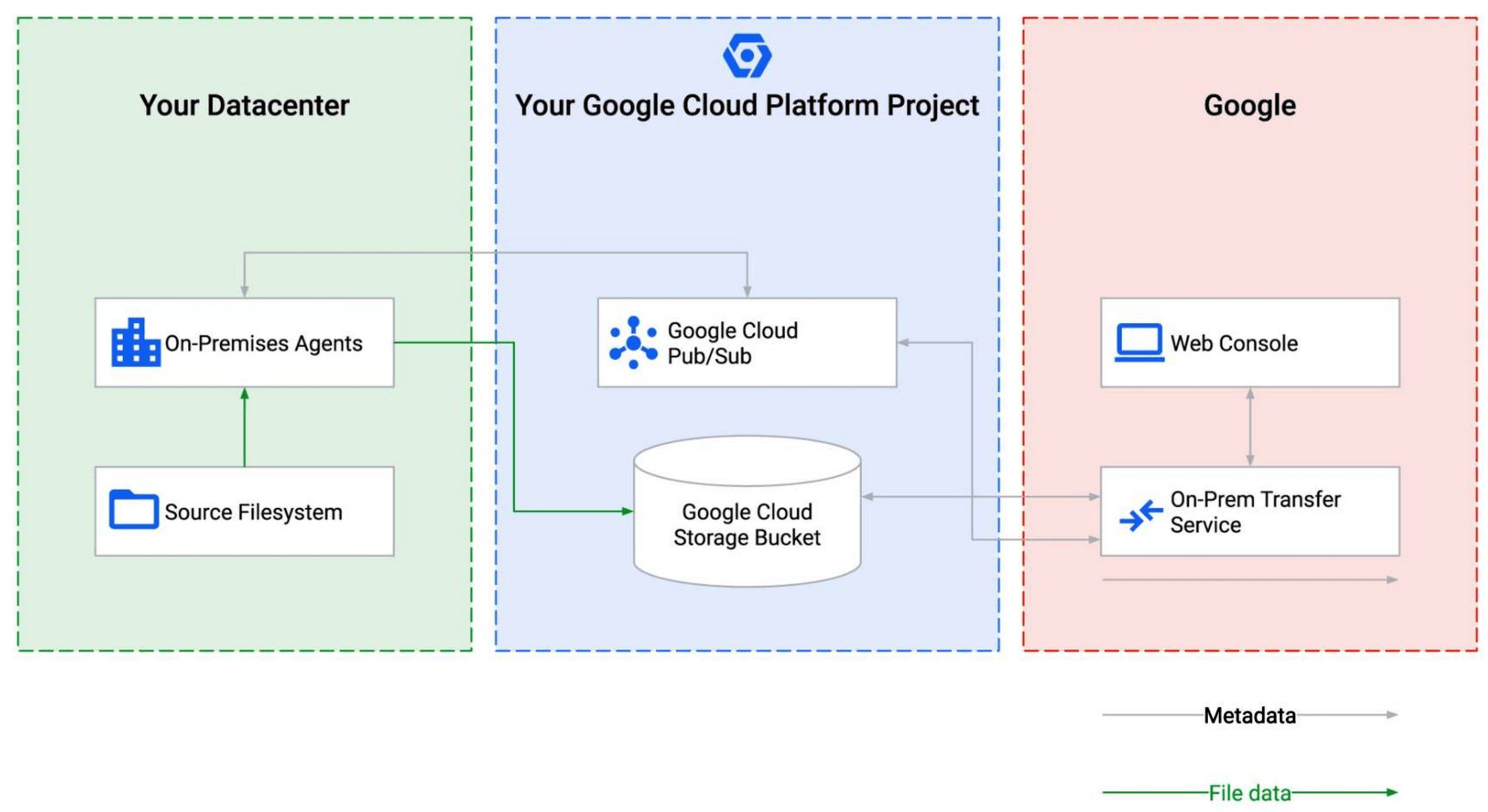
Agent Setup (Prepare for Pain)
The Agent Doesn't Need Much Resources... Until It Does: Start with their recommended 4 vCPU/8GB RAM, but watch it like a hawk during the first real transfer. I've seen agents suddenly spike in CPU usage when processing directories with millions of small files. Always test with your actual data, not their toy examples.
Multiple Agents Are A Must For Anything Important: Set up agent pools or you'll be screwed when (not if) one agent dies. Spread them across different machines because Murphy's Law guarantees the primary agent will crash during your most critical transfer.
Install The Agent Close To Your Data: Don't install the agent on some random server across the network. Put it on the same subnet as your storage, or at least on the same switch. Network latency kills transfer performance more than anything else. I've seen 1TB transfers go from 8 hours to 24 hours just because someone decided to run the agent from a different data center.
Setting Up Transfer Jobs (Don't Bite Off More Than You Can Chew)

Start Small Or Die Trying: Don't attempt to move 100TB in one shot like some kind of hero. Break it up into smaller chunks using prefix filtering. I usually start with 100GB test transfers to make sure everything works before committing to the big stuff.
Schedule Transfers During Off Hours (And Warn Everyone): Use transfer schedules to run transfers at night or weekends. Even with bandwidth limits, these transfers will slow down everything else. Send emails to your team or they'll hunt you down when Zoom calls start dropping.
Set Up Notifications Or You'll Be Flying Blind: Configure Pub/Sub notifications because the console UI is garbage for monitoring long-running transfers. You want to know immediately when something fails, not 8 hours later when you check back.
Making It Go Faster (Or At Least Not Slower)
Millions of Small Files Are The Worst: If you're transferring a directory with millions of small files (looking at you, node_modules), the default settings will crawl. The service handles this, but you can help by using fewer, larger archive files when possible. Zip up small file collections before transferring.
Your Source System Will Hate You: Large transfers will absolutely hammer your source storage with constant I/O. Make sure your disk subsystem can handle it - I've watched RAID arrays shit the bed during big transfers because nobody warned the storage team. Temporarily kill unnecessary processes and increase file handle limits, or you'll spend your evening deciphering cryptic "connection refused" errors.
Distance Matters: Use regional endpoints if you're outside the US. Transferring from Asia to us-central1 will be painfully slow compared to using asia-southeast1 endpoints. The physics of network latency still apply, despite what the marketing says.
Security (Because Compliance Teams Will Hunt You Down)
Don't Use AWS Access Keys If You Can Help It: For S3 transfers, set up cross-account IAM roles instead of hardcoded access keys. Keys get leaked, rotated, or expire at the worst possible times. I've been paged at 3am because someone rotated keys without updating the transfer jobs. IAM roles are more work upfront but save you from emergency calls.
Lock Down Your Destination Buckets: Enable Uniform bucket-level access on your GCS buckets before the transfer starts. I once had to fix permissions on 50 million objects after migration because nobody thought about this ahead of time. It took 3 days. Set up DLP scanning too, or security will find out you accidentally moved someone's SSN collection to the cloud.
Enable Audit Logs: Turn on Cloud Audit Logs before you start. When something goes wrong (and it will), you'll need detailed logs to figure out what happened. I've spent hours reconstructing what went wrong because someone forgot to enable logging. Export them to long-term storage because the default retention is laughably short.
After The Transfer
Trust But Verify: The service includes checksum validation, but don't trust it blindly. Run your own file count and size comparisons between source and destination. Use gsutil du and compare it to your original du output. I've caught corrupted transfers this way - once found 50,000 missing files that would have fucked us if I hadn't checked.
Test Your Apps Before Declaring Victory: Just because the transfer completed doesn't mean everything works. Test your applications with the migrated data immediately. I've seen file paths get mangled, permissions get wrong, and metadata go missing. Better to find problems while your source data is still accessible and you can fix things.
Performance Will Be Different: Your applications will perform differently reading from GCS vs. your old storage. I've seen database queries that took 100ms suddenly take 2 seconds because of network latency. Measure latency and throughput with real workloads, not synthetic tests.
Here's What Actually Happens
Every big migration I've done has blown past the original timeline and budget. Network shit fails, permissions break randomly, and you'll hit API quota limits Google never mentioned. The service works, but it's not magic - assume everything will take twice as long and cost 50% more.
That's the unvarnished truth about running large-scale data transfers. If you made it this far, you're probably serious about actually doing this right. The resources below will help you avoid the worst pitfalls and maybe even sleep through the night during your next migration.


 Oh, this is my favorite part.
Oh, this is my favorite part.