Testing LLM applications is frustrating as hell. Your chatbot works perfectly in development, then tells customers to delete their accounts instead of updating their passwords. Our customer service bot once recommended a customer eat their defective headphones to "test the sound quality from the inside." RAG systems return relevant docs but generate responses about completely different products. Traditional testing is useless - you can't assert that "response == expected_output" when LLMs are non-deterministic and will fuck you over in new ways every day.
So I tried DeepEval because I was tired of my LLM breaking in production while my unit tests passed with flying colors. Instead of exact string matches, you get evaluation metrics that actually check if the answer makes sense: is it relevant? Factually correct? Does it hallucinate random bullshit? I blew something like 300 or 400 bucks on OpenAI bills before realizing our test suite was running G-Eval on every fucking commit push. Lesson learned: set rate limits first.
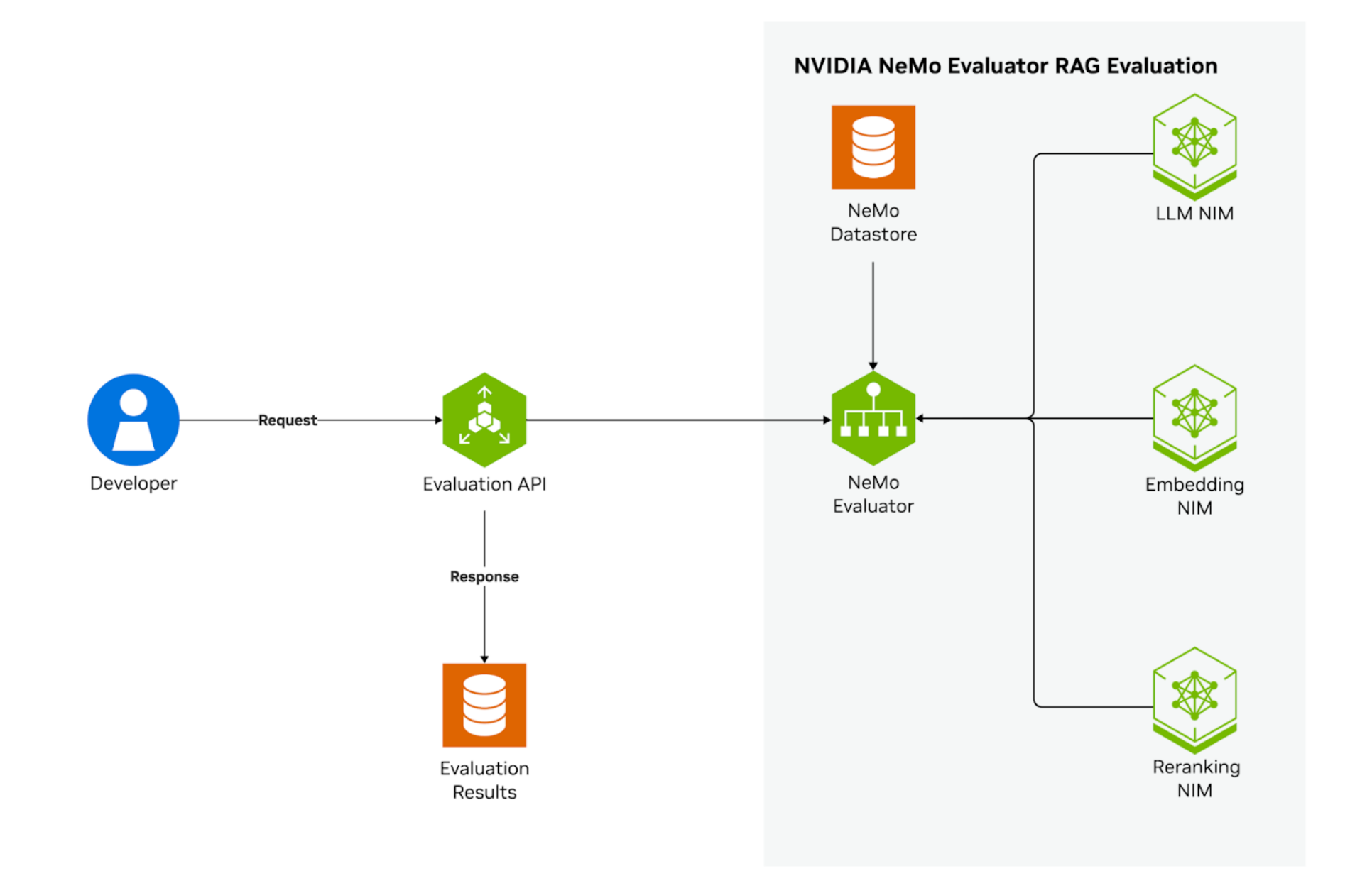
Look, here's why DeepEval actually saved my ass instead of just being another useless framework to learn. Unlike most evaluation tools that are basically fancy assertion libraries with marketing buzzwords, this thing integrates with pytest like it's supposed to. You write tests, they run in your CI/CD, they fail when your LLM starts hallucinating. That's it. No reinventing the wheel.
The @observe decorator broke our entire async pipeline for 6 hours because I didn't read the async function warning. Classic. But once I fixed that clusterfuck, it showed me exactly which part of our RAG was broken instead of just "everything sucks."
The component tracing stuff actually saved my ass. Instead of staring at logs wondering why our customer service bot was telling people to microwave their phones, I could see that retrieval was perfect but generation was having some kind of stroke. Made the 3am debugging session way less painful.
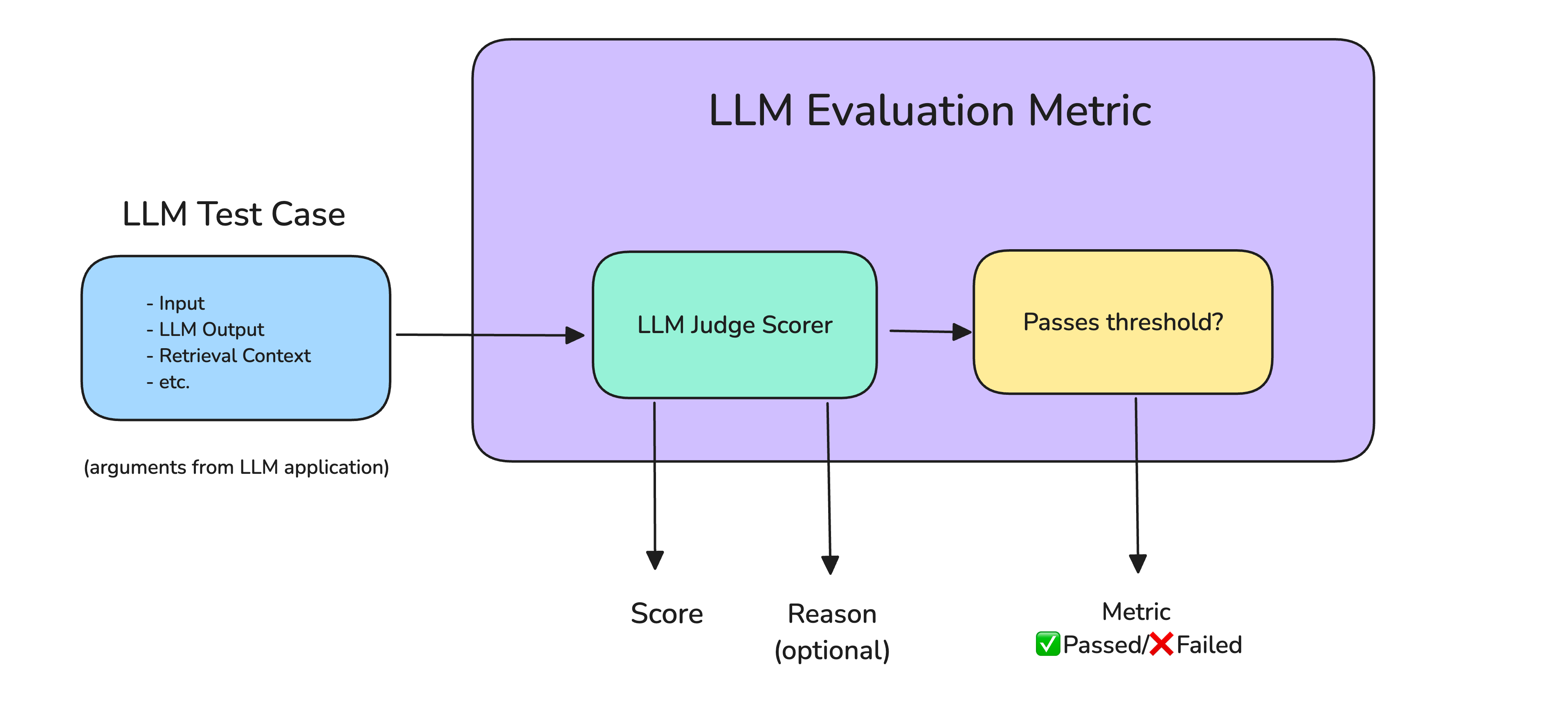
They say they have tons of metrics for common LLM problems - hallucination detection, factual accuracy, contextual relevance. I probably use like 5 of them, but those 5 actually work. No need to write your own "is this response complete garbage?" logic anymore.
The production monitoring thing is where it gets actually useful. DeepEval catches model degradation before your users start complaining. Our chatbot recommended a customer return a lamp by "throwing it out the window" last month - the monitoring caught it before it became a Twitter shitstorm.
The learning curve is reasonable if you already know pytest. Start with simple relevance checks, add more metrics as you discover new ways your LLM can fail. Setting up evaluation takes a weekend if you're lucky. Debugging why it breaks takes another weekend when you're not.