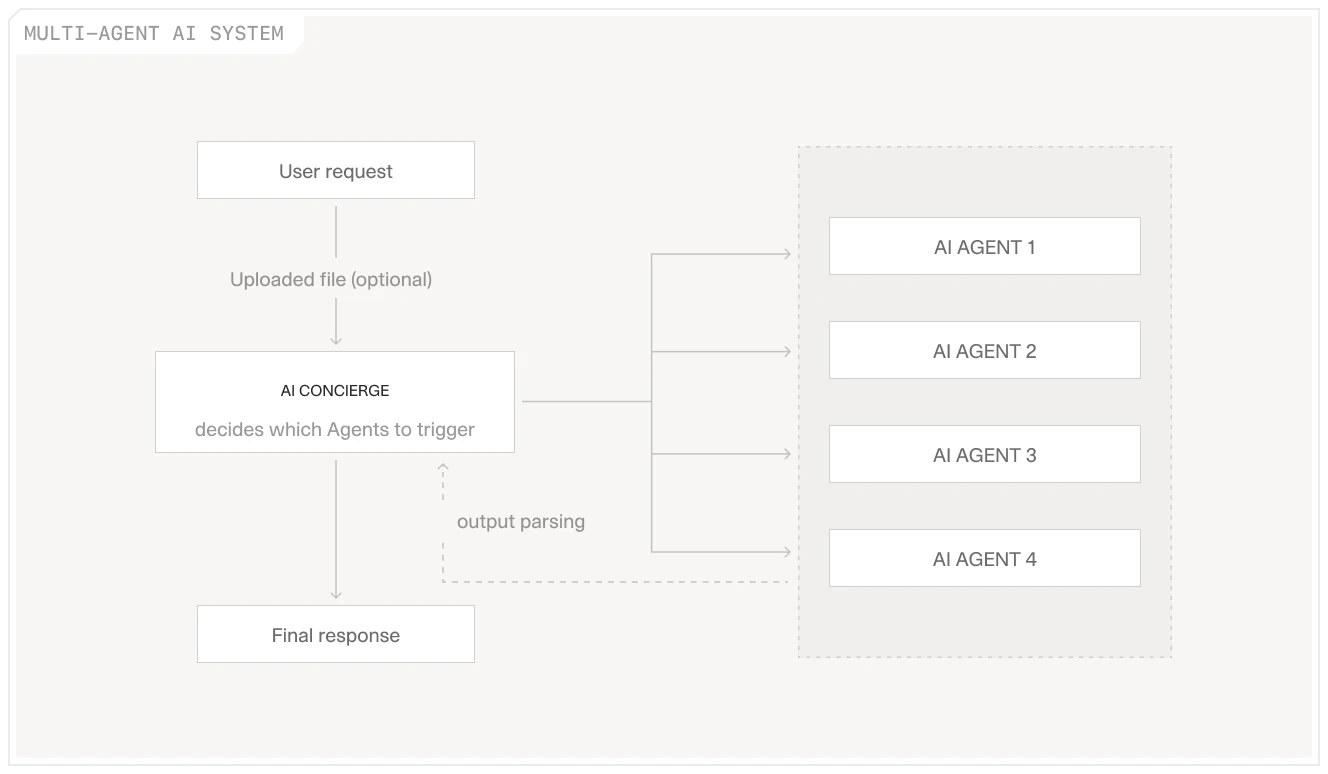
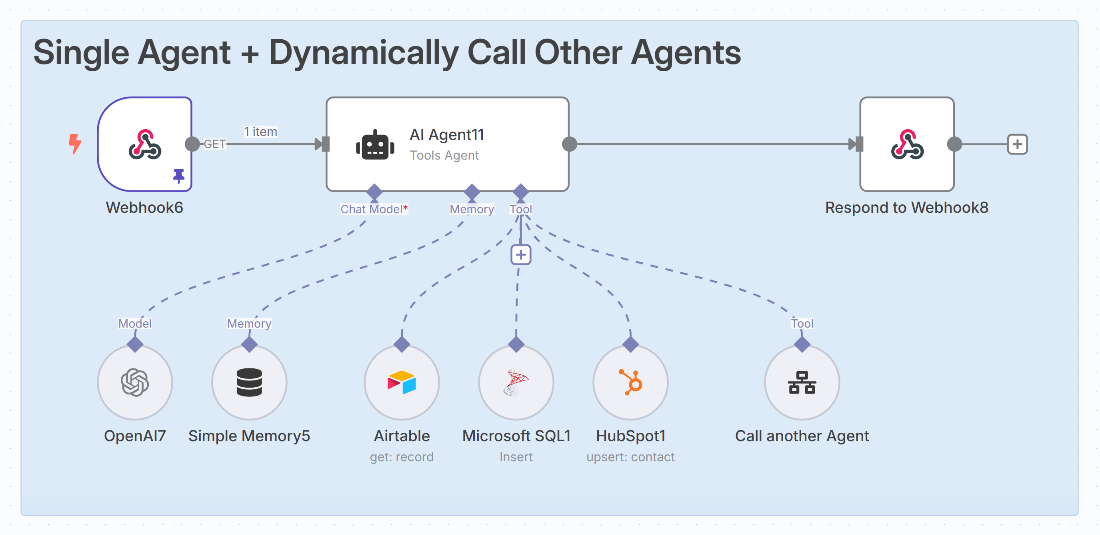
![]()
Look, using multiple AI frameworks together? Sounds brilliant until you actually try it. I thought "Hey, each one's good at something specific, this'll be the ultimate AI stack." Yeah, right. Three production disasters later, here's the shit nobody warns you about.
The Real Problem: Everyone Speaks a Different Language
LlamaIndex treats everything as a document and wants to embed it into vectors. Great for search, absolute hell for anything else. LlamaIndex 0.8.x had this fun bug where it would randomly fail to load embeddings if your document had certain Unicode characters - took me a week to figure that one out. The memory optimization docs are helpful but underestimate actual memory requirements by 50%. The 2025 production deployment guide mentions scaling challenges but doesn't cover real-world memory explosions.
LangChain thinks the world revolves around chains and agents. It's gotten better since the early days when version 0.0.150 would leak memory like crazy, but it still has this annoying habit of swallowing exceptions and giving you useless error messages like "Chain failed" with no context. The debugging documentation exists but doesn't help when your chain fails silently. Memory leak issues persist, and the production debugging reality is nothing like the official guides.
CrewAI is basically fancy function calling with a team metaphor. Don't get me wrong, it works, but the role-based approach gets weird fast when you need dynamic behavior. Plus their docs are optimistic about error handling - in reality, when one agent fails, the whole crew often just... stops.
AutoGen is the most honest about what it is: a conversation manager. But debugging multi-agent conversations is like trying to follow a drunk argument in a noisy bar. Good luck figuring out why Agent A suddenly decided to ignore Agent B.
Pattern 1: The Data Foundation Mess
Everyone says to use LlamaIndex as your "data layer." Here's what that actually looks like:
## This looks clean but will break in production
from llama_index import VectorStoreIndex, ServiceContext
from langchain.memory import ConversationBufferMemory
## LlamaIndex eats RAM for breakfast
## 1000 docs = 4GB RAM minimum, more if you're unlucky
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
## LangChain memory that forgets when you restart
memory = ConversationBufferMemory()
Real talk? LlamaIndex will fucking eat your RAM. 10,000 documents means kissing goodbye to 16GB+ of RAM, minimum. And if you're hitting OpenAI embeddings? Hope you like explaining a $3,000 API bill to your manager. The best practices guide mentions chunking but forgets to mention your server will catch fire.
Pattern 2: LangChain as the "Orchestrator"
LangChain's agent system is powerful but fragile. It works great for demos, then randomly fails in production because:
- Tool calls timeout (common with external APIs)
- Memory runs out of context window space
- Agent decides to call the same tool 47 times in a loop
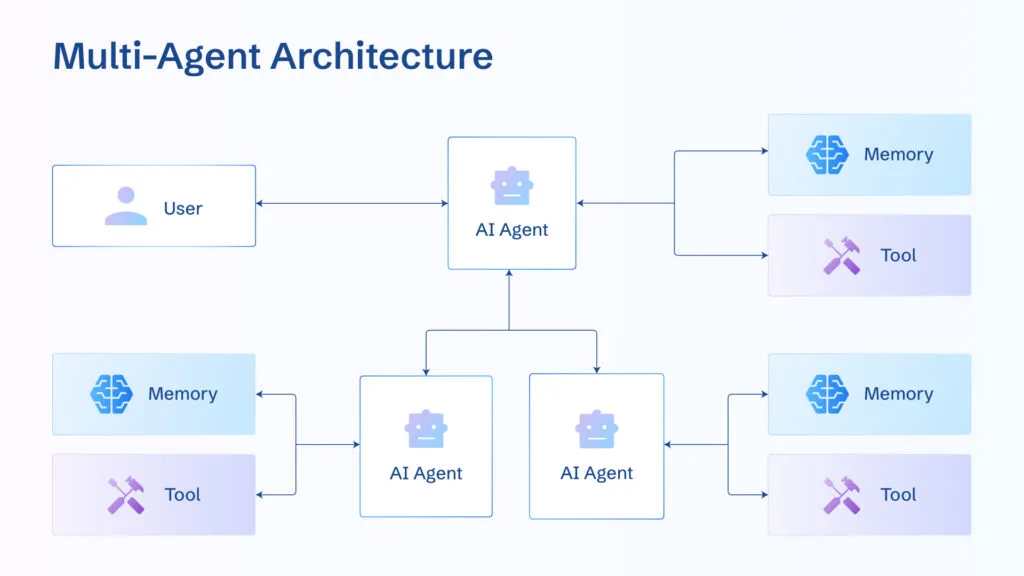
Pattern 3: Multi-Agent Chaos
CrewAI vs AutoGen is like choosing between structured chaos and unstructured chaos. CrewAI forces you into predefined roles that break when you need flexibility. AutoGen gives you flexibility that breaks when you need predictability.
The Communication Protocol Fantasy
Model Context Protocol (MCP) sounds amazing - a unified way for frameworks to talk to each other. Reality check: it's still early and most integrations are custom glue code held together with prayers. The MCP documentation is optimistic, but real-world implementations are mostly experimental. The 2025 agent stack analysis confirms MCP is more promise than reality. Current integration patterns still rely heavily on custom adapters.
State Management is Where Dreams Die
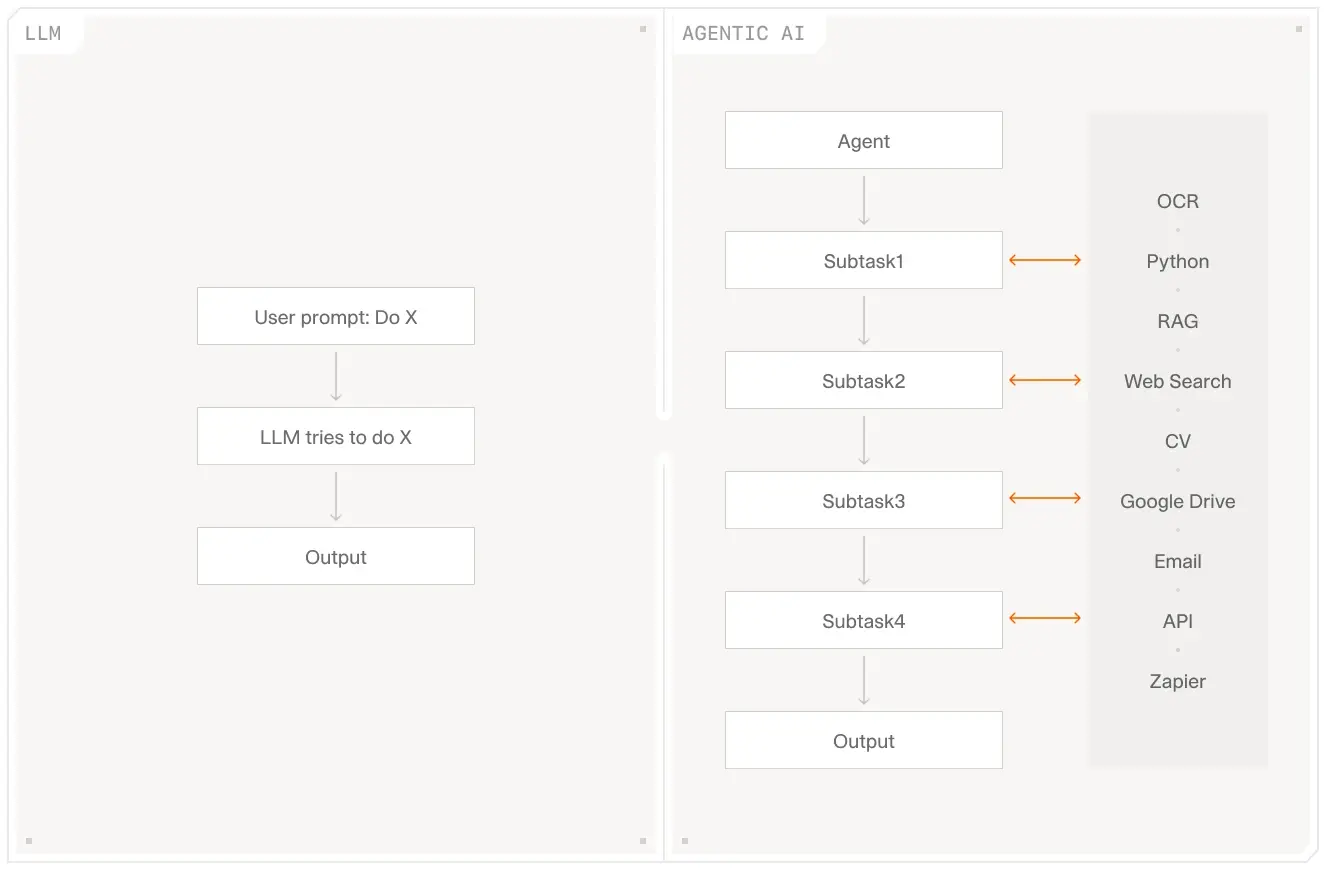
Each framework has its own idea about state:
- LlamaIndex: "State? What state? We just retrieve documents."
- LangChain: "Here's 12 different memory types, pick one and pray."
- CrewAI: "State is task completion status."
- AutoGen: "State is conversation history that might overflow."
I watched a team burn through 4 months just building state sync bullshit so these frameworks could talk to each other. Four. Fucking. Months.
Performance Reality Check
Multi-framework setups are slow. Period. Each framework adds latency:
- Network calls between services
- Serialization/deserialization overhead
- Context switching between different execution models
My production system has 200-400ms base latency just from framework orchestration, before any actual AI work happens. Vector database caching helps, but now you're managing cache invalidation across multiple systems. The performance optimization guides exist but focus on single-framework scenarios.
Truth bomb: multi-framework setups are engineering nightmares masquerading as solutions. They're not plug-and-play anything - they're custom disasters requiring dedicated DevOps, monitoring, and debugging wizards. The AI observability space is mostly vendors selling you dashboards that scream "EVERYTHING IS ON FIRE" five minutes after it's already burned down.