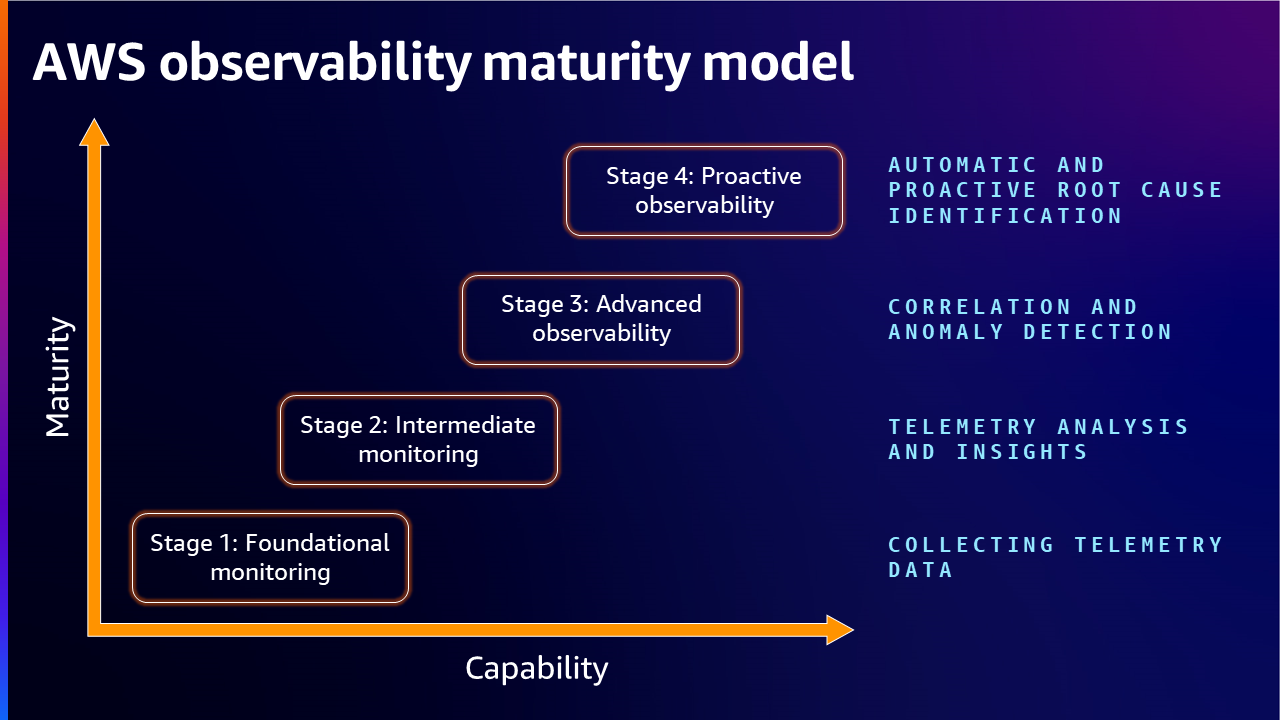
Most organizations are stuck between Stage 2 (Reactive Monitoring) and Stage 3 (Proactive Observability) of the AWS observability maturity model, creating significant enterprise readiness gaps.
Enterprise observability isn't just dashboards that look good in screenshots - here's what I've learned from watching dozens of implementations: most enterprises think they've reached Stage 3 observability maturity when they're actually stuck at Stage 2. This disconnect creates huge blind spots in security, compliance, and operational reliability. I've seen this pattern everywhere, and recent Gartner research confirms what I've been witnessing - companies have no clue where they actually stand.
The Four-Stage Enterprise Maturity Framework
I've used AWS's maturity model and CNCF frameworks to benchmark implementations across dozens of companies. Here's where organizations actually end up:
Stage 1: Tool Chaos (Where Everyone Starts)
- Multiple monitoring tools that don't talk to each other
- Alert storms that make engineers ignore everything
- Reactive fire-fighting instead of actual insight
- Reality Check: Most smaller companies are here, trying to figure their shit out
Stage 2: Integration Hell (Where Most Get Stuck)
- Dashboards exist but don't tell you what's actually wrong
- Alerts provide some context, but engineers still burn hours debugging
- Leadership thinks you're "enterprise-ready" - spoiler: you're not
- Reality Check: Most enterprises are trapped here, despite spending millions on fancy platforms
Stage 3: Actually Useful Observability
- Everything connects - logs, metrics, traces actually correlate properly
- When something breaks, you know why in minutes instead of hours
- MTTR drops to something like 15 minutes for most incidents
- Reality Check: Maybe a quarter of companies reach this level, and it requires serious work
Stage 4: The Holy Grail (Predictive Ops)
- Problems get fixed before customers notice
- Systems actually heal themselves (not vendor marketing lies)
- Engineers build features instead of debugging constantly
- Reality Check: Almost nobody reaches this - Netflix, Google, and maybe three fintech companies that threw insane money at it
Why Enterprises Get Stuck at Stage 2
1. Compliance Theater vs. Real Governance
Every vendor claims their platform is "enterprise compliance ready" - complete nonsense. SOC 2 Type II certification sounds impressive in vendor presentations until real auditors show up asking for seven years of log retention and your platform dies. NIST Cybersecurity Framework compliance looks great in slides, but try explaining to your CISO why you can't prove who accessed customer data during last week's breach investigation.
Real compliance gaps we see:
- Audit trail limitations: Many platforms can't track who modified what alert configurations and when
- Data residency violations: Logs containing PII accidentally stored in wrong geographic regions
- Access control sprawl: Over-privileged service accounts accessing sensitive telemetry data
- Retention policy conflicts: Legal teams require 7-year log retention while platforms optimize for 30-day storage
2. Vendor Lock-in Masquerading as Platform Consolidation
The "single pane of glass" promise usually becomes a single point of failure and vendor lock-in nightmare. I've seen too many enterprises regret betting everything on one vendor. OpenTelemetry offers vendor-neutral alternatives, but most enterprises avoid it because it requires real engineering work instead of just signing contracts:
- Migration complexity: Extracting 3+ years of historical observability data for vendor transitions
- Feature dependency: Custom dashboards and alerting logic tied to proprietary APIs
- Cost escalation: Predictable pricing becomes unpredictable as data volumes grow
- Innovation lag: Waiting 12-18 months for vendors to support new cloud services or frameworks
3. Security Integration Blind Spots
Traditional observability focuses on performance and availability while completely ignoring security context. Every security incident I've investigated could have been caught earlier with proper observability-security integration. Most platforms treat security as an add-on feature, not something built in. Enterprise platforms need:
- SIEM correlation: Security events correlated with performance anomalies
- Zero-trust verification: Identity context for every system access request
- Threat detection: Behavioral analysis across application and infrastructure telemetry
- Incident response automation: Automated containment based on observability signals
The Hidden Cost of Observability Immaturity
Quantifiable Impact Analysis:
FinOps cost optimization research and enterprise cloud spending analysis demonstrate that observability immaturity creates hidden financial impacts beyond incident response delays.
Organizations stuck at Stage 2 get hit with:
- MTTR that destroys team morale - production incidents take hours to fix when they should take minutes
- Alert noise that makes you ignore everything - false alarms train engineers to tune out all notifications
- Infrastructure costs that terrify CFOs - higher expenses from reactive scaling and resource waste
- Engineering teams debugging instead of building - entire teams waste days per month fighting their tools instead of shipping features
Real Enterprise Example: Financial Services Migration
Saw a major bank discover their platform was completely inadequate during cloud migration. Federal regulators needed detailed reports, PCI compliance requirements were brutal, and their existing observability couldn't handle any of it. Regulatory reporting systems failed, change tracking was non-existent, and disaster recovery testing revealed they were operating blind. The cleanup cost several million dollars and took over a year.
Enterprise-Specific Readiness Criteria

I've seen enterprise platforms collapse under organizational complexity that goes beyond standard observability capabilities. Here's what actually matters:
1. Organizational Scale Requirements
- Support for 50,000+ monitored entities across global regions
- Role-based access control for 500+ engineering team members
- Multi-tenant isolation for business units with different compliance requirements
2. Governance and Risk Management
- Automated compliance reporting for SOC 2, FedRAMP, ISO 27001, and industry-specific regulations
- Change management integration with corporate governance processes
- Risk scoring and business impact correlation for production incidents
3. Vendor Risk Assessment
- Financial stability analysis of observability platform vendors
- Roadmap alignment with enterprise cloud strategy (5+ year horizon)
- Professional services capacity for enterprise-scale implementations
- Contractual commitments for SLA, data protection, and service continuity
Here's what actually matters: objectively assess your current maturity stage and identify the specific gaps preventing enterprise-grade observability. Most organizations discover they need fundamental platform architecture changes, not just configuration improvements.
Key Enterprise Assessment Questions:
- Can you trace a customer complaint back to specific infrastructure events in under 5 minutes?
- Do your observability access controls actually work with your corporate identity management?
- Would your current platform survive a 10x increase in telemetry data without collapsing?
- Can you generate compliance reports automatically or do you still copy-paste data into spreadsheets?
These questions separate companies with actual enterprise observability from those just running fancy dashboards. Understanding your current state is only half the problem. The real challenge is figuring out which platforms can handle enterprise requirements when everything goes wrong.
Time to cut through vendor marketing and examine how major observability platforms actually perform under enterprise pressure.