The Logical Replication Reality Check
Look, I learned this the hard way: logical replication looks easy on paper, but PostgreSQL will find creative ways to make you suffer. The first time I tried this, I thought "how hard can it be?" Famous last words. Took down production for 4 hours.
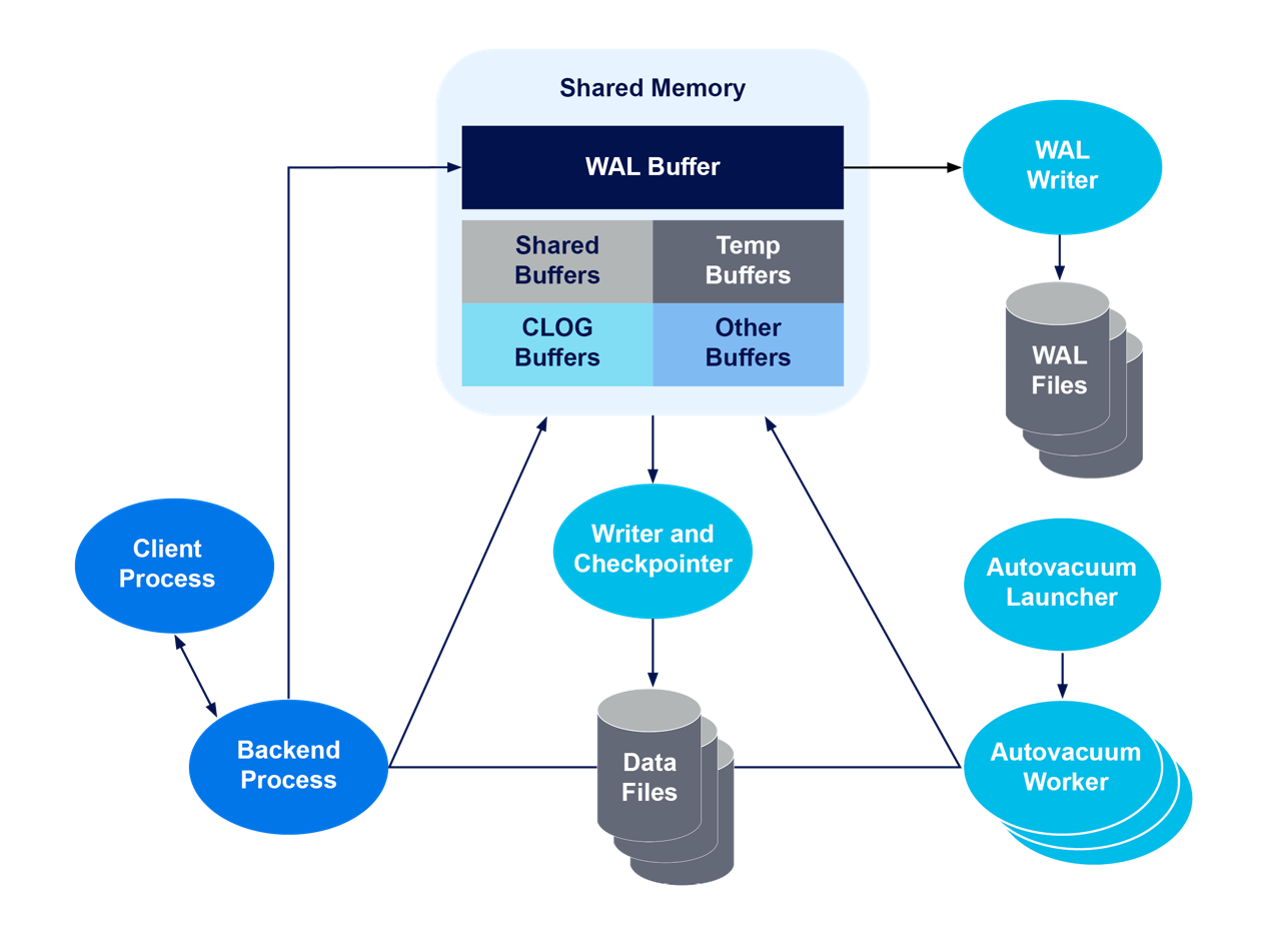
The thing is, logical replication actually works great when everything goes right. When it doesn't... well, I've had 4-hour debugging sessions that started with "this should only take 3 seconds." You'll want to understand WAL architecture before you start troubleshooting why everything's fucked. The PostgreSQL streaming replication docs also helped me understand what happens when things break.
Your Infrastructure is Probably Wrong
The Config Hell You're About to Enter
First things first - check if your PostgreSQL 16 source even has logical replication enabled. Spoiler alert: it probably doesn't.
-- Check if you're screwed
SHOW wal_level;
-- If this says 'replica' instead of 'logical', grab some coffee
-- These better not be zeros
SHOW max_replication_slots;
SHOW max_wal_senders;
SHOW max_logical_replication_workers;
If wal_level isn't logical, you're about to restart PostgreSQL. Yes, that means downtime. I forgot this step once and had to explain to the CEO why our "zero-downtime" upgrade started with 20 minutes of downtime. Fun times. The PostgreSQL configuration guide explains all these settings in excruciating detail.
## postgresql.conf - the settings that will save your ass
wal_level = logical
max_replication_slots = 10
max_wal_senders = 10
max_logical_replication_workers = 10
max_worker_processes = 20
Heads up: Changing wal_level means restarting PostgreSQL. Plan accordingly or you'll be explaining to management why the site went down.
Hardware Reality Check (You Need More Than You Think)
Here's what I learned when our migration brought down the entire cluster because I was cheap with resources:
- CPU: Double what you normally use. Logical replication chews through CPU like crazy during initial sync. The PostgreSQL performance tuning guide has good advice on CPU planning.
- Memory: Same deal - double it. WAL processing will eat all your RAM if you let it. Check the shared_buffers documentation for memory planning.
- Storage: At least 150% of your source database. Learned this when we ran out of disk space mid-migration at 2am - logs filled up to like 800GB or something crazy. The PostgreSQL storage management docs explain why this happens.
- Network: Keep it under 5ms latency or you'll hate your life. Replication lag becomes unbearable otherwise. Network tuning for PostgreSQL covers the connection settings.
- Disk I/O: Get the fastest storage you can afford. Trust me on this one. PostgreSQL I/O optimization explains the WAL settings that matter.
Setting Up Your PostgreSQL 17 Target (The Fun Part)
Spin up a new PostgreSQL 17 server. Make it beefier than your source - you're not being wasteful, you're being smart. I went with identical specs once and watched the migration crawl along like a dying snail. On my 2019 MacBook this migration took fucking forever.
## If you're on AWS (and who isn't these days) - this works on Ubuntu 22.04, your mileage may vary on CentOS
aws rds create-db-instance \
--db-instance-identifier postgres17-target \
--db-instance-class db.r5.xlarge \
--engine postgres \
--engine-version 17.0 \
--allocated-storage 500 \
--master-username postgres \
--manage-master-user-password \
--vpc-security-group-ids sg-xxxxxxxxx \
--db-subnet-group-name my-subnet-group \
--backup-retention-period 7
Schema Setup (The Part Where Things Break)
Getting Your Schema Over to the Target
Time to copy your schema. This is usually straightforward, but PostgreSQL loves to surprise you with permission errors and weird edge cases. Oh, and don't get me started on PostgreSQL's error messages - they're about as helpful as a chocolate teapot. The pg_dump documentation covers all the flags that might save you hours of debugging.
## Dump your schema (pray it works first try)
pg_dump --host=source-host \
--username=postgres \
--schema-only \
--no-privileges \
--no-owner \
source_database > schema.sql
## Apply to target (fingers crossed)
psql --host=target-host \
--username=postgres \
--dbname=target_database \
--file=schema.sql
The Primary Key Problem That Will Ruin Your Day
Here's the thing nobody tells you: logical replication freaks out if your tables don't have primary keys. It just sits there, silently hating you. The logical replication restrictions explain this limitation in detail.
-- Find the tables that will break your replication
SELECT schemaname, tablename
FROM pg_tables t
LEFT JOIN pg_constraint c ON c.conrelid = (schemaname||'.'||tablename)::regclass
AND c.contype = 'p'
WHERE c.conname IS NULL
AND schemaname NOT IN ('information_schema', 'pg_catalog');
-- Fix them (this will hurt performance but it'll work)
ALTER TABLE table_without_pk REPLICA IDENTITY FULL;
Reality check: REPLICA IDENTITY FULL means PostgreSQL replicates entire rows for every change. Your network will hate you, but at least replication won't silently fail.
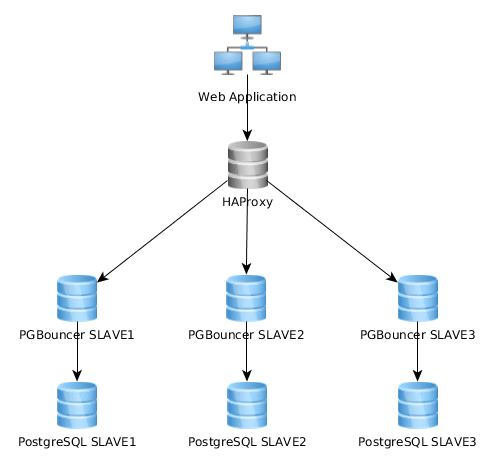
PgBouncer: Your Best Friend and Worst Enemy
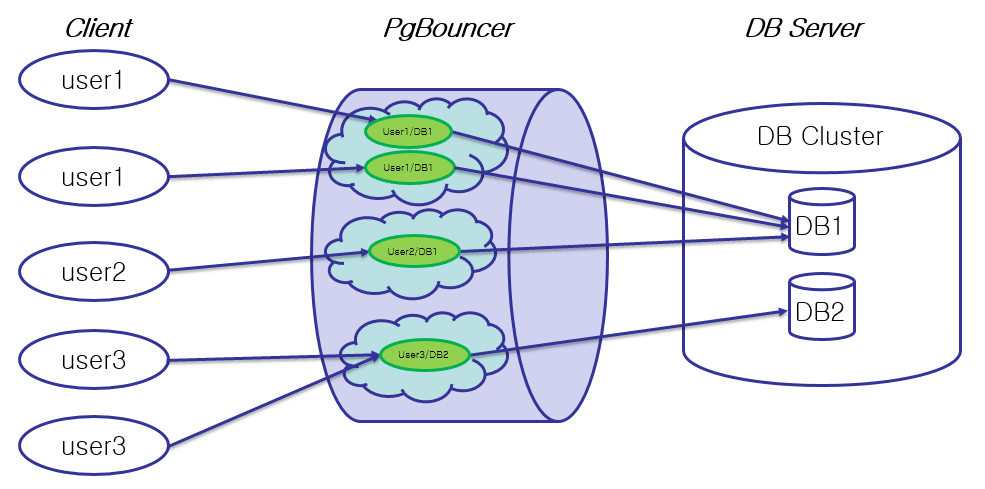
PgBouncer is what makes the magic happen. When it works, it's brilliant. When it doesn't... well, I've spent many late nights debugging why PgBouncer decided to stop working for no reason. The PgBouncer documentation and PostgreSQL connection pooling best practices are essential reading.
Getting PgBouncer Not to Hate You
Here's a config that actually works in production:
## /etc/pgbouncer/pgbouncer.ini
[databases]
myapp = host=source-host port=5432 dbname=production
[pgbouncer]
listen_port = 6432
listen_addr = 0.0.0.0
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
pool_mode = transaction
max_client_conn = 1000
default_pool_size = 20
reserve_pool_size = 5
admin_users = pgbouncer_admin
Authentication Setup (The Part That Always Breaks)
## /etc/pgbouncer/userlist.txt
\"postgres\" \"md5d41d8cd98f00b204e9800998ecf8427e\"
\"app_user\" \"md5c93d3bf7a7c4afe94b64e30c2ce39f4f\"
Generate those MD5 hashes (because plain text passwords are for suckers):
echo -n \"passwordusername\" | md5sum
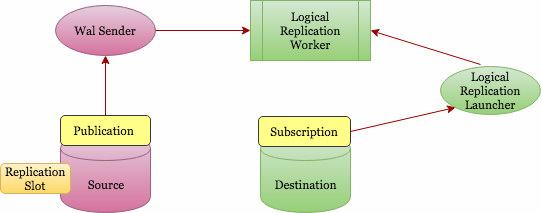
Setting Up Logical Replication (Where the Real Fun Begins)
Step 1: Create the Publication (The Easy Part)
-- On your source database
CREATE PUBLICATION upgrade_publication FOR ALL TABLES;
-- Double-check it worked (because trust but verify)
SELECT pubname, puballtables FROM pg_publication WHERE pubname = 'upgrade_publication';
Step 2: Create the Subscription (Where Things Get Interesting)
First, make sure your target database has the schema but no data:
-- Nuke all the data but keep the schema
DO $$
DECLARE
r RECORD;
BEGIN
FOR r IN (SELECT tablename FROM pg_tables WHERE schemaname = 'public') LOOP
EXECUTE 'TRUNCATE TABLE ' || quote_ident(r.tablename) || ' CASCADE';
END LOOP;
END $$;
Now create the subscription and pray to the PostgreSQL gods:
-- This is where things either work beautifully or explode spectacularly
CREATE SUBSCRIPTION upgrade_subscription
CONNECTION 'host=source-host port=5432 dbname=production user=replication_user password=secure_password'
PUBLICATION upgrade_publication;
Step 3: Watching the Initial Sync (And Slowly Going Insane)
The initial sync takes forever. On a 100GB database, it took like 6 hours, but could've been 8 - I wasn't exactly watching the clock. Here's how to monitor it without losing your mind:
-- Is it even working?
SELECT subname, pid, received_lsn, latest_end_lsn, last_msg_send_time, last_msg_receipt_time
FROM pg_stat_subscription;
-- How far behind are we? (this number will haunt your dreams)
SELECT EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp())) as lag_seconds;
-- Are the tables actually getting data?
SELECT schemaname, tablename,
(SELECT count(*) FROM information_schema.tables WHERE table_name = tablename) as target_count,
pg_stat_get_tuples_inserted(oid) as source_inserts
FROM pg_tables
WHERE schemaname = 'public';
Making Sure Your Data Didn't Get Corrupted
The Paranoid Data Validation Step
Trust but verify. I learned this lesson when 20,000-something user records went missing during my first migration:
-- Row count comparison (the basic sanity check)
SELECT 'source' as db, count(*) FROM source_table
UNION ALL
SELECT 'target' as db, count(*) FROM target_table;
-- Data checksum comparison (the paranoid check)
SELECT 'source' as db, md5(string_agg(md5(t.*::text), '' ORDER BY id))
FROM source_table t
UNION ALL
SELECT 'target' as db, md5(string_agg(md5(t.*::text), '' ORDER BY id))
FROM target_table t;
Performance Warning: Logical replication will slow down your source database during initial sync. I've seen 30-40% performance degradation on write-heavy workloads. Plan accordingly - maybe don't do this during Black Friday. Learn from my pain. Check the PostgreSQL monitoring guide for tracking performance during migration.
Once logical replication is humming along and your data looks sane, you're ready for the switchover. That's where things get really exciting - and by exciting, I mean terrifying. But we'll tackle that in the next phase, armed with monitoring queries that actually work and emergency procedures that don't assume everything goes perfectly.