I've migrated 12 production databases over the last 8 years. Four of those migrations failed spectacularly. One took down our payments system for 6 hours on a Friday afternoon. Another corrupted 3 months of user data because someone forgot to test the foreign key constraints.
Here's what I learned from debugging these disasters at 3am while fielding angry Slack messages from the CEO.
The Real Definition (Not Marketing Bullshit)
Zero downtime migration means your users don't notice you're moving the database. That's it. No 30-second maintenance pages, no "we'll be back shortly" messages, no customers calling support because they can't place orders.
The dirty truth: even the "best" zero downtime migrations have hiccups. GitHub's 2018 database incident showed that MySQL to MySQL replication can fail catastrophically. Their "zero downtime" migration took down GitHub for 24 hours because of a split-brain scenario nobody anticipated.

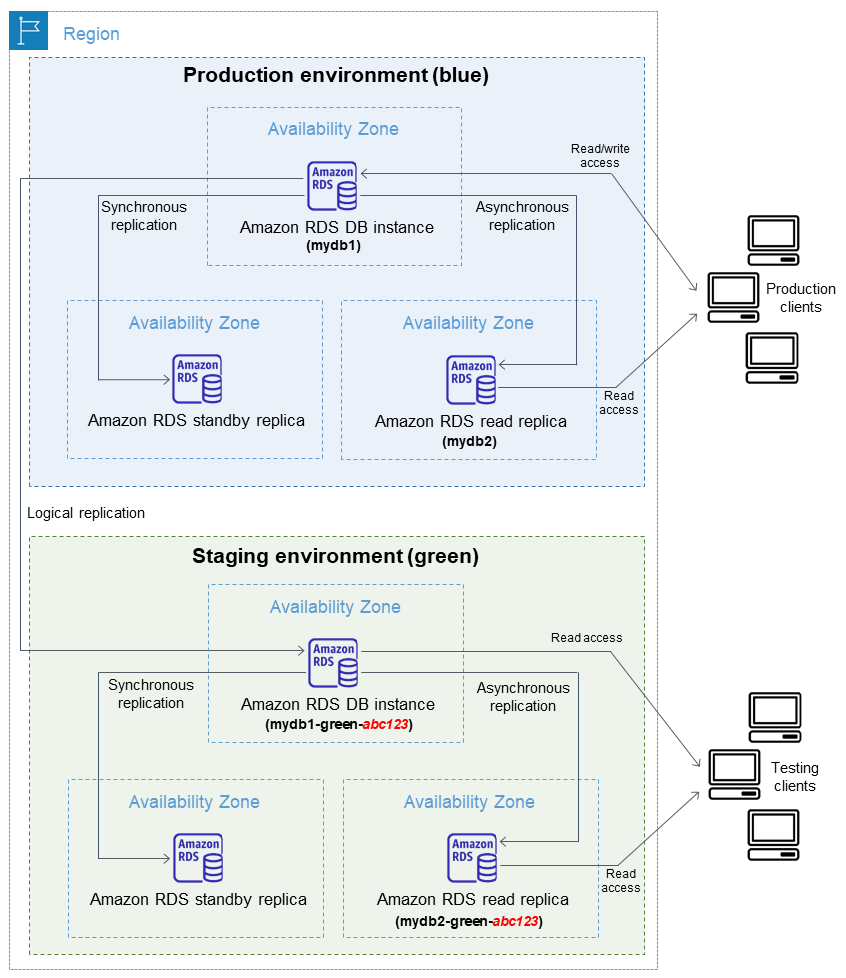
The architecture above looks clean and simple. In practice, every arrow in that diagram represents 2-3 weeks of debugging edge cases that nobody anticipated.
What Actually Goes Wrong
Backward Compatibility is a Lie: Every database schema change breaks something. That "simple" column addition? It just broke the legacy API that accounting still uses. The new NOT NULL constraint? Half your microservices are crashing because they send empty strings.
I learned this when we added a user_preferences JSON column to PostgreSQL 11. Turns out our Java service was still on some ancient JDBC driver from 2017 that couldn't handle JSONB types properly. The driver would silently convert JSONB to TEXT, breaking our JSON parsing logic. Took down user logins for 3 hours until we rolled back.
Replication Lag Will Destroy You: AWS RDS documentation casually mentions that read replicas can lag "minutes behind" the primary. They don't mention that during peak traffic, lag can hit 15+ minutes. Your "instant" cutover becomes a 15-minute window where half your users see stale data.
Your Tools Will Fail: AWS DMS looks great in demos until you hit LOB data larger than a few MB. Then performance degrades catastrophically due to memory allocation issues, and you'll spend weeks debugging why your migration is crawling. Oracle GoldenGate works perfectly until you discover it can't handle your custom composite primary keys. Every migration tool has edge cases that will bite you.
The Hidden Costs Nobody Talks About
AWS DMS Architecture: The service uses a replication instance to read data from your source database, transform it as needed, and write it to the target database. Sounds simple until you discover it can't handle your specific edge cases.
Double Everything: Blue-green deployments sound elegant until you realize you need 2x storage, 2x compute, and 2x the AWS bill. Shopify's migration to sharded MySQL required running parallel infrastructure for 6 months. Their hosting costs literally doubled.
Professional Services Scam: That "free" migration tool from your database vendor? Surprise! You need $50,000 in professional services to configure it properly. Oracle's sales team loves pushing zero downtime migration tools, then charging enterprise rates for consultants who actually know how to use them.
The Real Timeline: Marketing says 2 weeks. Engineering estimates 6 weeks. Reality is 4 months because you discover the database has undocumented stored procedures written in PL/SQL by someone who left the company in 2019.
What Success Actually Looks Like
The best zero downtime migration I ever saw was boring as hell. Stripe's document database migration took 18 months of careful planning, gradual traffic shifting, and extensive monitoring. No exciting cutover ceremony, no war room, no 3am crisis calls.
They used feature flags to slowly migrate read queries, then writes, then let the databases synchronize for weeks before final cutover. Boring, expensive, successful.
The worst migration I ever did was "quick and easy" - a simple PostgreSQL upgrade using logical replication. We scheduled 2 hours. It took 20 hours because:
- The replication slot filled up disk space
- Custom extensions weren't compatible with the new version
- Query performance regressed 40% due to planner changes
- The application's connection pooler couldn't handle the new SSL requirements