Ever spent 3 months building a model only to discover it doesn't work in production? Yeah, TFX exists because that happens to literally everyone. Most ML projects struggle to reach production - the exact percentage is debated (ranging from 70-90% depending on who's counting), but the core problem is real: models that work in Jupyter break in production because nobody knows how to deploy them without everything catching fire.

TFX is Google's attempt to solve this, released in 2019 and currently at version 1.16.0. But here's what the documentation won't tell you upfront: TFX requires Python 3.9-3.10 and if you're on 3.11, good luck - half the dependencies will break in spectacular ways.
The Production Nightmare TFX "Solves"
The real problem isn't just getting models to production - it's that production breaks models in ways you never imagined. Your beautiful pandas code? Gone. Your scikit-learn preprocessing? Rewrite it in TensorFlow ops. That CSV file that worked perfectly in Jupyter? Now it needs to be a TFRecord because reasons.
Data Validation Hell: TFX's TFDV component sounds great until you realize it requires understanding TensorFlow's type system, which is about as intuitive as assembly language. I've seen teams spend 2 weeks just getting schema validation to work because their data had one unexpected null value. The error message? INVALID_ARGUMENT: Schema validation failed for feature 'user_id' - which tells you absolutely fucking nothing about what's actually wrong.
"Reproducible" Pipelines: Sure, TFX pipelines are reproducible - if you can remember the exact versions of TensorFlow (2.16.0), TFX (1.16.0), Apache Beam (2.x), and the dozen other libraries that need to align perfectly. Mix these wrong and you'll spend a week in dependency hell. Pro tip I learned the hard way: TFX 1.15.0 + Apache Beam 2.48.0 = broken serialization that works locally but fails in Dataflow with AttributeError: module 'tensorflow.python.util.deprecation' has no attribute 'deprecated_endpoints'. Cost us 2 days of debugging.
Apache Beam "Features": The Apache Beam requirement means you're signing up for distributed computing headaches even for simple models. That "scalable infrastructure" will cost you $5000/month in Google Cloud Dataflow costs if you're processing real data.
The Components That Will Actually Ruin Your Life
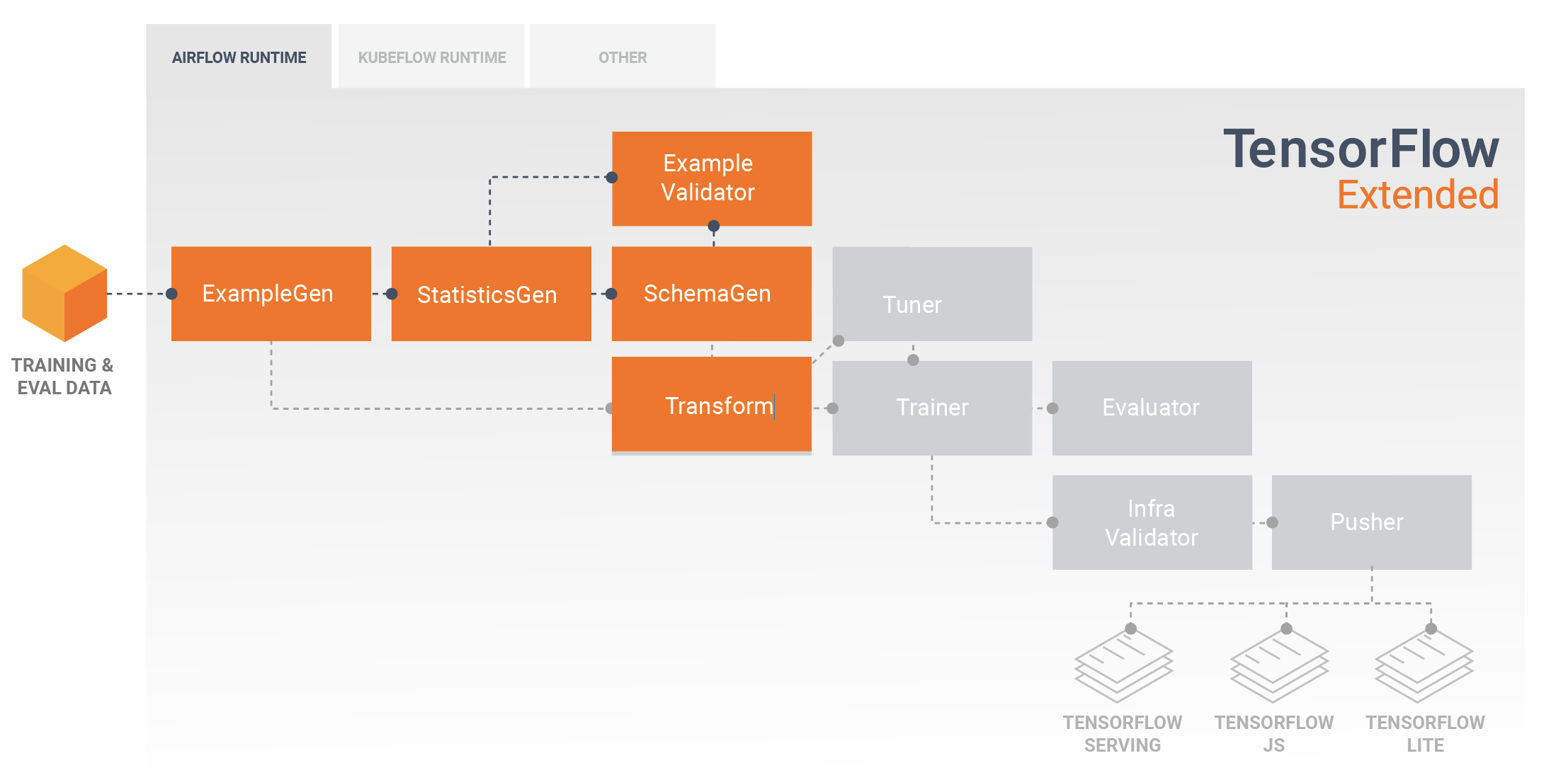
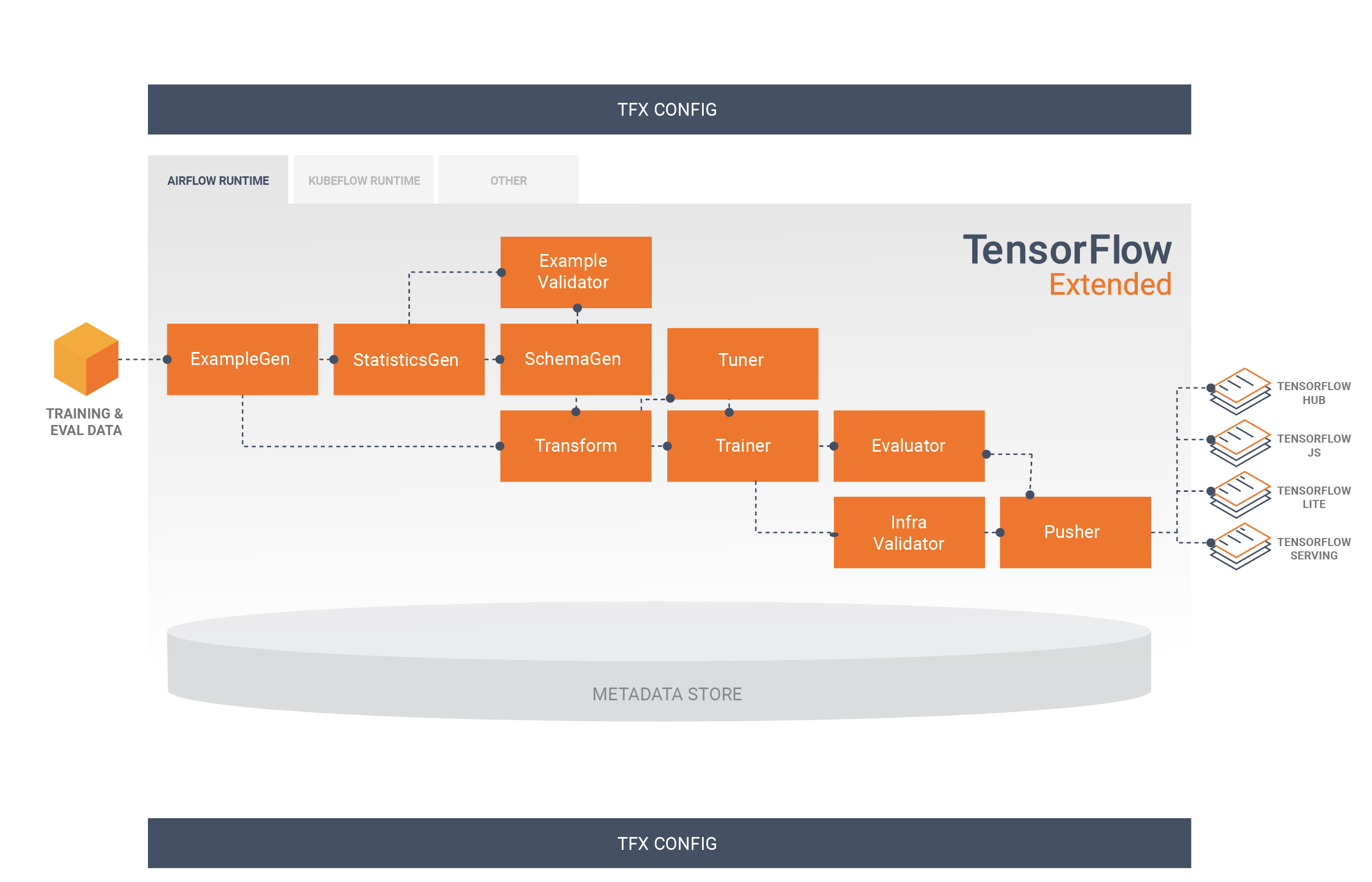
Look, TFX has 9 components because Google engineers think everything needs to be a microservice. I could go through all of them, but honestly, Transform and ExampleValidator are the ones that will ruin your week.

Transform forces you to rewrite working pandas code in TensorFlow ops that crash randomly. I've seen teams spend 3 weeks converting a 50-line pandas script that worked perfectly into TensorFlow operations that fail for mysterious reasons.
ExampleValidator fails on null values and gives you error messages about as helpful as "something went wrong." SchemaGen automatically generates schemas that are wrong 60% of the time, then ExampleValidator validates against those wrong schemas. It's like designed failure. Fun fact I discovered at 3am: TFX breaks silently if your dataset has Unicode characters in column names - no error, just mysteriously empty outputs.
The other components? ExampleGen converts your CSV files into TensorFlow's binary format and crashes with cryptic errors. StatisticsGen spends 2 hours computing what df.describe() does in 2 seconds. Trainer finally does actual model training but only if you follow TFX's rigid patterns.
Each component "operates independently" which means when something breaks, you get to debug across 9 different failure points. Good luck figuring out if it's a Transform issue, a schema problem, or just Apache Beam being Apache Beam.
"Enterprise" Features (Translation: More Complexity)
TFX's "enterprise-grade" features are what happen when Google engineers design for companies with unlimited engineering budgets. The ML Metadata tracking creates comprehensive audit trails, which sounds great until you realize it's another database to maintain and backup.
The platform integrates with Apache Airflow (if you enjoy debugging YAML files), Kubeflow Pipelines (if you're a Kubernetes masochist), and Google Cloud Vertex AI (if you don't mind AWS-sized bills). "Seamless integration" means you only need to learn 3-4 additional orchestration frameworks.
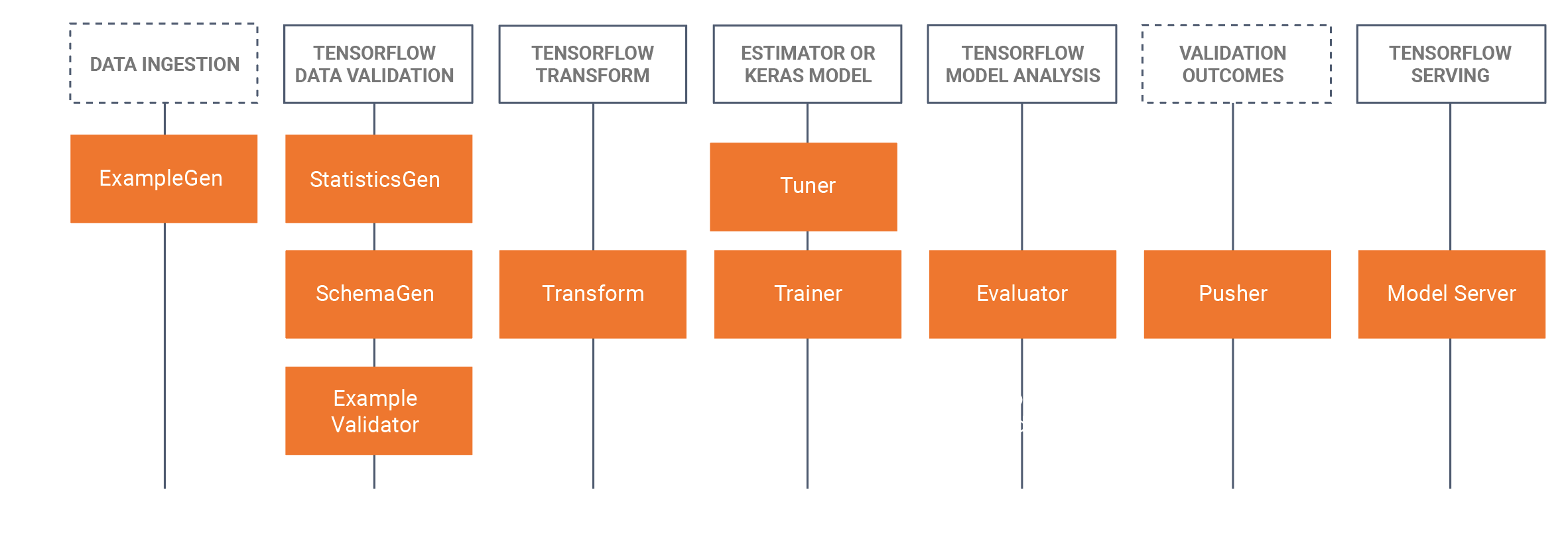
The multi-platform deployment sounds impressive: TensorFlow Serving for servers, TensorFlow Lite for mobile, TensorFlow.js for browsers. In practice, each deployment target has its own gotchas, and what works in one rarely works in another without modification.
Bottom line: TFX solves real problems, but introduces 10 new ones for every problem it fixes. If you have a team of 5+ engineers who understand TensorFlow, distributed systems, and don't mind spending 6 months becoming TFX experts, it might work for you. Otherwise, use literally anything else.
OK, how does this compare to other tools?