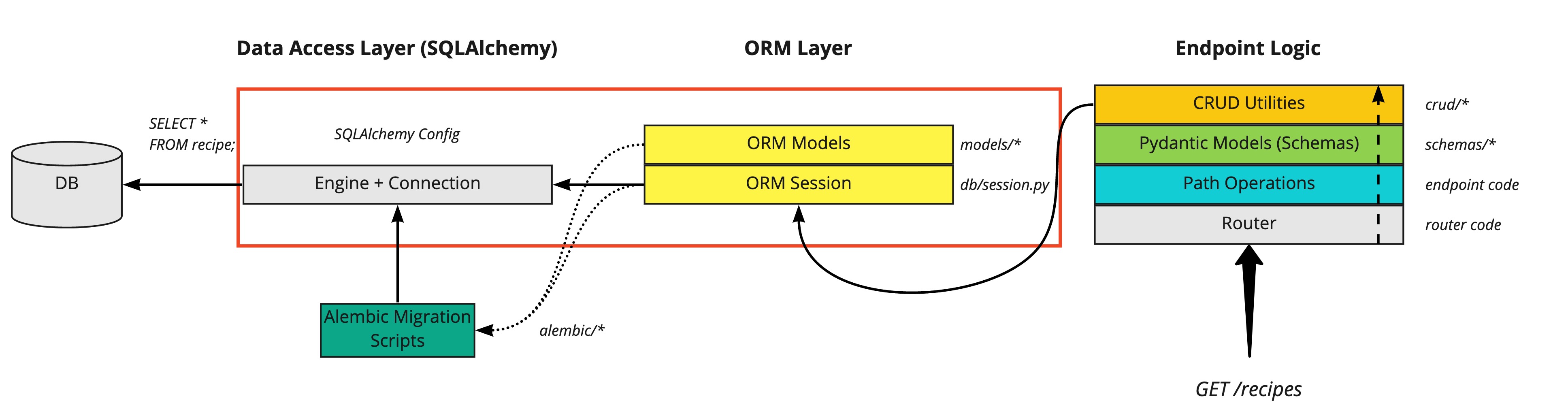
SQLAlchemy isn't just another ORM. It's two tools in one: Core and ORM. Most developers start with the ORM because it's easier, then discover Core when the ORM's generated SQL becomes garbage.
SQLAlchemy Core: For When You Need Control
SQLAlchemy Core is basically SQL with Python objects instead of string concatenation. You write SQL, but safely. No more worrying about SQL injection because some junior dev decided to use f-strings with user input.
Core is what you reach for when:
- The ORM generates 47 queries instead of 1 (N+1 problem will destroy your app)
- You need bulk operations that don't take 3 hours
- Your query is too complex for the ORM to handle without shitting itself
- You're debugging some performance disaster and need to see the actual SQL
Real example: Inserting 100,000 records with ORM took like 45 minutes, maybe longer, and nearly got me fired. Same operation with Core bulk_insert_mappings takes 2 seconds. Learned this the hard way during a data migration that was supposed to take "a few minutes."
SQLAlchemy ORM: For When You Want Magic
The SQLAlchemy ORM sits on top of Core and handles all the boring relationship stuff automatically. It tracks object changes and generates INSERT/UPDATE/DELETE statements for you.
ORM is perfect when you:
- Want relationships to "just work" without writing JOIN statements
- Need automatic dirty tracking (knows what changed since last save)
- Don't want to think about database connections and transactions
- Are building typical CRUD apps where performance isn't critical
Warning: The ORM makes it stupidly easy to write queries that murder your database. Always check the generated SQL with `echo=True` in your engine.
When Core vs ORM Becomes Life or Death

After 6 years of SQLAlchemy in production, here's what actually matters:
Use Core when:
- Bulk operations (> 1000 records)
- Complex analytics queries with multiple CTEs
- Performance is measured in milliseconds
- You're getting timeout errors from the ORM
Use ORM when:
- Standard CRUD operations
- You want to focus on business logic, not SQL
- Relationships are complex but records are few
- Rapid prototyping where performance doesn't matter yet
Version Hell Alert: SQLAlchemy 2.x breaks everything from 1.x. The migration guide is 50 fucking pages. I thought it'd take a weekend - took me a month. Check out the 20to13 compatibility layer if you're stuck in version hell.
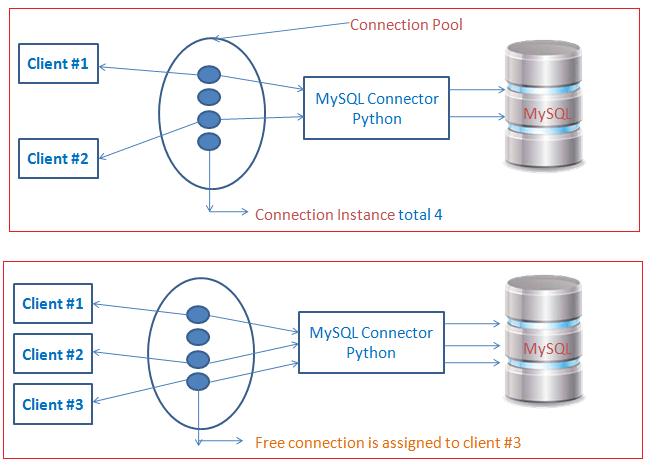
Production Gotcha: Connection pools default to 5 connections. Five. What brain-dead genius thought 5 was enough? Your app will randomly hang when traffic spikes. Set `pool_size=20` and `max_overflow=30` or prepare for 3am debugging sessions. Trust me - I learned this when our login page went down during launch day. PostgreSQL connection limits and MySQL's max_connections will bite you.
Most real apps use both. ORM for day-to-day CRUD, Core when the ORM generates garbage SQL and your boss is asking why the dashboard takes 30 seconds to load. Don't let purists tell you to "pick one" - that's how you end up with slow apps that users hate. I use patterns for mixing Core and ORM in every project.