The Infrastructure Planning Nobody Talks About
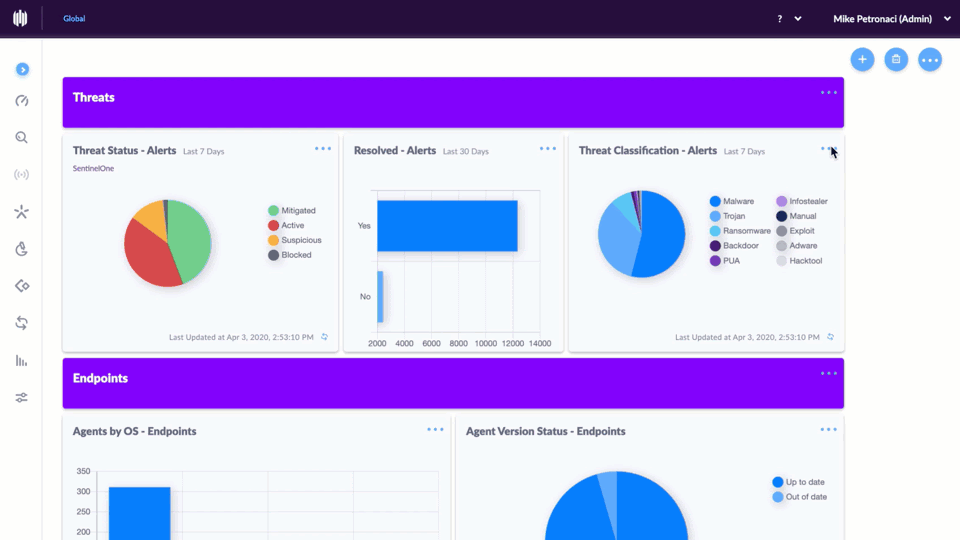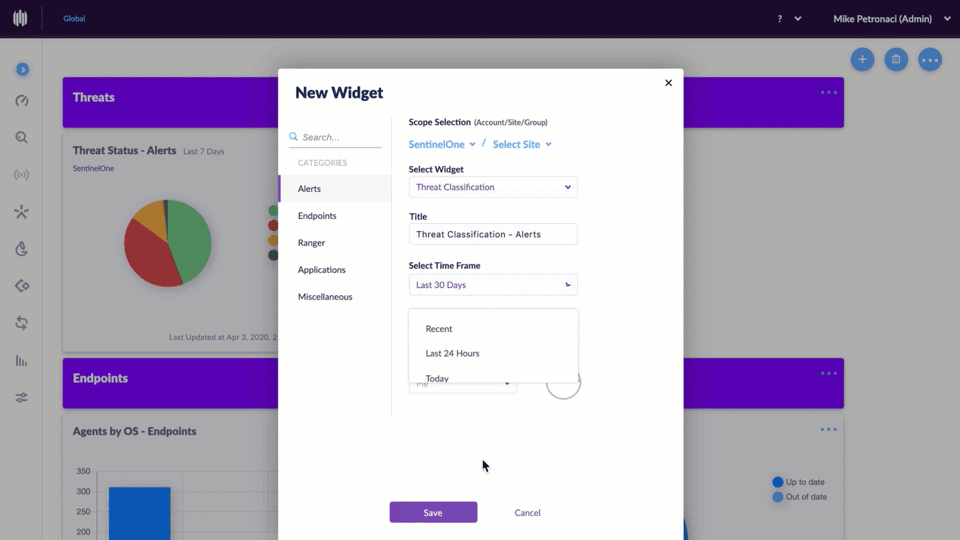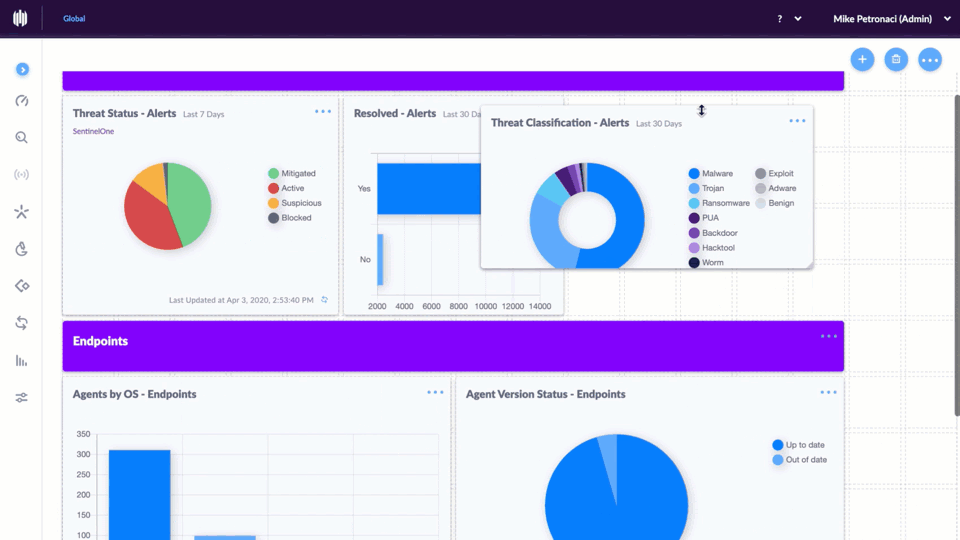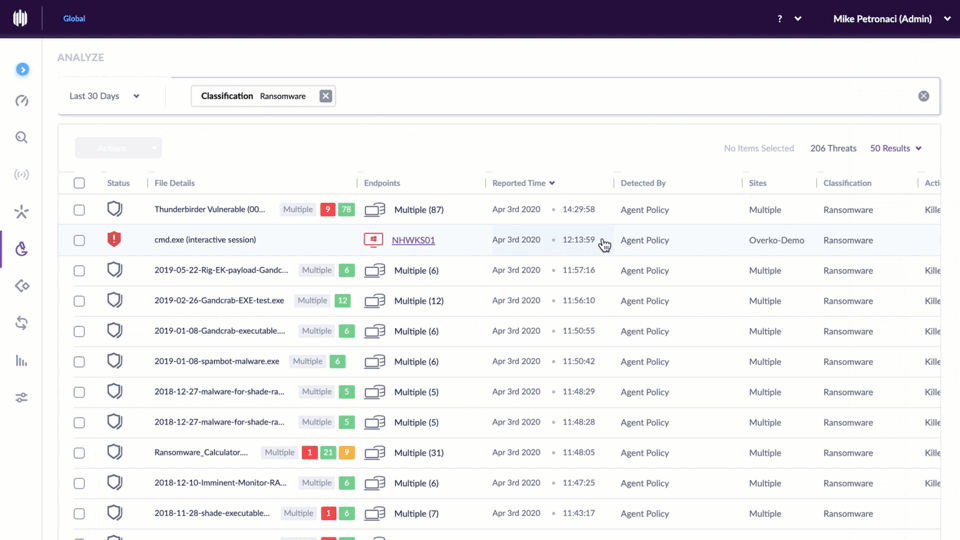
SentinelOne's marketing horseshit about handling 500,000 endpoints is technically true in the same way a Ferrari can do 200mph - sure, under perfect lab conditions. They conveniently forget to mention that you'll slam into brick walls around 100,000 endpoints unless your infrastructure was designed by God himself - which it fucking wasn't.
That "50-150MB RAM usage" in their docs? Pure fantasy. I've personally watched the agent eat 1.2GB during a ransomware incident at a manufacturing plant. Try running SentinelOne 22.3.1 on anything less than 8GB and watch your users revolt. Your users are still limping along on 4GB machines because procurement wouldn't approve hardware refresh three years ago, so get ready for non-stop calls about "the computer being slower than my grandmother with a walker."
The real nightmare isn't the agent - it's that nobody plans for the clusterfuck that follows. Your bandwidth calculations are wrong because you believed their documentation. Your storage estimates are pure fantasy because you trusted their "lightweight forensics" claims. That gorgeous multi-tier policy hierarchy you spent three weeks architecting? It'll become a management hellscape faster than you can say "policy exception" when every department manager wants their special snowflake applications excluded from security.
The Policy Hierarchy Trap That Ruins Everything
Here's the actual shitshow that happens with multi-tier deployments: you start with a beautiful Global → Regional → Local hierarchy that looks perfect in the PowerPoint. Week 3: accounting's ancient PDF software triggers false positives. Week 5: marketing demands exceptions for their cracked design tools downloaded from Russian torrent sites. Week 8: legal threatens to involve the board if their document retention policies don't match their compliance fantasies.
Six months later, you're maintaining 73 completely fucking contradictory policies with names like "Marketing-DesignTools-Exception-v4-FINAL-REALLY-FINAL-USE-THIS-ONE" and nobody - including you - remembers why half of them exist or which endpoints they actually apply to.
Global Tier: The policies that worked perfectly when you tested them on your 5 IT lab machines
Regional Tier: Where your well-intentioned architecture goes to die a slow, bureaucratic death
Local Tier: Pure fucking anarchy disguised as "critical business requirements"
The policy inheritance system sounds sophisticated when the sales engineer demos it. It's less sophisticated when you're debugging at 3am, half-drunk on Red Bull, trying to figure out why 200 accounting staff can't open Excel files and the CEO is threatening to fire everyone involved in this "security disaster."
Performance Impact: The Shit They Don't Want You to Know
Their documentation claims 50-150MB RAM usage. Here's what actually happens in the real world:
- Normal operation: 200-400MB (double their "worst case" estimate)
- During scans: 600-800MB while users watch their machines turn into expensive paperweights
- Active threat response: 1.2GB+ and the machine becomes completely fucking unusable
- Legacy systems on Windows Server 2012: Agent crashes every 3 hours with EVENT_ID 7034
After deploying to 50,000+ endpoints across manufacturing plants where every machine matters, I learned this the hard way: anything under 8GB RAM is guaranteed pain. That 15-20% performance impact they casually mention for 4GB systems? Try 50-70% performance degradation during scans, and prepare for users to start physically unplugging network cables to stop "that virus software that's somehow worse than actual viruses."
Actual Planning Metrics (Not Sales Fantasy):
- Network bandwidth: Multiply their estimates by 5x minimum - those cute "10-50KB per hour" numbers assume steady state, not 500 endpoints hammering your 10Mbps MPLS link at 9AM Monday
- Storage: Their 2-5GB per endpoint estimate is fucking laughable - budget 15-20GB if you want forensics data that doesn't make investigators laugh at you
- API limits: 1,000 requests per minute sounds generous until you have 50 panicking analysts hammering the API during the first major incident
- Maintenance windows: Ignore their 2-4 hour estimates - plan for 8-12 hours because something critical will break at 2am and you'll need time to fix it
Network Requirements That Break Your WAN
Those neat fucking bullet points about *.sentinelone.net:443 connectivity requirements conveniently skip the part where your branch offices are limping along on 10Mbps MPLS connections that they share with VoIP, video calls, and whatever else the business threw at them. When 200 agents simultaneously try to phone home after a policy update, your entire sales team can't make phone calls for two hours and guess who gets blamed?
What You Actually Need (Not What Sales Promised):
- Dedicated security bandwidth: Your network team will fight you tooth and nail on this because "it's just antivirus"
- Local caching/proxy servers: Expensive as hell but absolutely mandatory unless you enjoy explaining WAN outages
- Traffic shaping: Business apps get priority over security telemetry, no matter how much SentinelOne wants to phone home
- Offline operation planning: Plan for when (not if) connectivity shits the bed completely
Their "offline protection" sounds great until your agents haven't checked in for 3 days because some backhoe operator cut the fiber line, and now you have zero visibility into half your environment. Remote workers with Comcast residential connections drop offline every time it rains, and you'll spend 40% of your day explaining to executives why you can't see what's happening on a third of your endpoints.
Operating System Support: The Legacy System Nightmare
SentinelOne's OS support matrix looks impressive until you try to deploy to an environment where "modern Windows" means Server 2012 and half your critical applications run on Windows 7 machines that haven't been patched since 2019.
Windows Reality Check
Modern Windows: Works fine if your environment is actually modern (it's not)
Legacy Windows: Prepare for pain - behavioral analysis breaks everything
End-of-Life Windows: Just don't. Windows XP support is technically there but functionally useless
The biggest lie in enterprise security is that you can just "upgrade your legacy systems" as part of the deployment. These systems are legacy because they CAN'T be upgraded without breaking million-dollar manufacturing equipment or custom applications that nobody knows how to fix.
I spent three fucking weeks debugging why SentinelOne shut down a $50M automotive production line - turns out their brilliant behavioral detection decided that the PLC control software was "potentially malicious" because it injects code into memory. You know, exactly like PLC software has done for the past 20 years. The "reduced functionality" mode for Windows XP is basically security theater - accept that 20% of your environment will have garbage security forever and move on.
The macOS and Linux Adventures
macOS M1/M2 support is actually decent now, but good luck explaining to your Mac users why their laptop fans are spinning up randomly. The "kextless" security model is great in theory until you realize it means you have less visibility into what's actually happening.
Linux deployment is where things get interesting. Those 10 supported distributions assume you're running standard kernel builds. If your infrastructure team compiled custom kernels (and they probably did), you're looking at agent recompilation, testing, and probably breaking something important.
What They Don't Document:
- SELinux will block half the agent functionality by default
- Container workloads need separate agents that cost extra
- ARM support works until you hit edge cases that brick the agent
- Every kernel update is a potential disaster
The Four-Phase Deployment Fantasy
Every vendor sells you a "proven four-phase methodology." Here's what actually happens in each phase:
Phase 1: Lab Success, False Confidence (Weeks 1-8)
You deploy to 500 IT endpoints and everything works perfectly because IT systems are boring and standardized. Management declares victory. You make the mistake of believing your own success metrics.
What Really Happens:
- SSO integration breaks twice due to certificate issues nobody anticipated
- SIEM integration works in the lab but fails under production load
- Your baseline policies are based on IT systems, not the chaos that is the rest of your environment
- Training goes great because IT people understand security tools
Phase 2: Reality Hits Hard (Weeks 9-16)
You expand to business units and discover that every department runs software that behaves like malware. Accounting's PDF tools trigger behavioral detection. Manufacturing systems start throwing alerts every 5 minutes. Marketing's pirated Photoshop alternatives get quarantined.
Phase 3: The Nightmare Phase (Weeks 17-24)
This is where deployments die. Legacy applications break in mysterious ways. Performance complaints flood the help desk. Policy exceptions multiply like a virus. Half your analysts quit because alert fatigue makes their jobs unbearable.
Phase 4: Damage Control (Weeks 25-52)
You spend the next 6 months fixing everything that broke in Phase 3, explaining to management why the deployment took twice as long as planned, and documenting the 347 policy exceptions that make your security architecture look like Swiss cheese.
Reality: Most deployments take 9-12 months, not 4-6, and that's if you're lucky.