Redis 8 actually made clustering less painful with horizontal scaling for the Query Engine and I/O threading that doesn't suck as much. If you've spent weekends debugging weird cluster failovers in Redis 6 or 7, you'll appreciate what they fixed.
But let me be clear: Redis clustering will still make you question your life choices. The difference is that now you'll only lose sleep 60% of the time instead of 90%. Check out the Redis 8 clustering improvements and community feedback to see what actually got fixed.
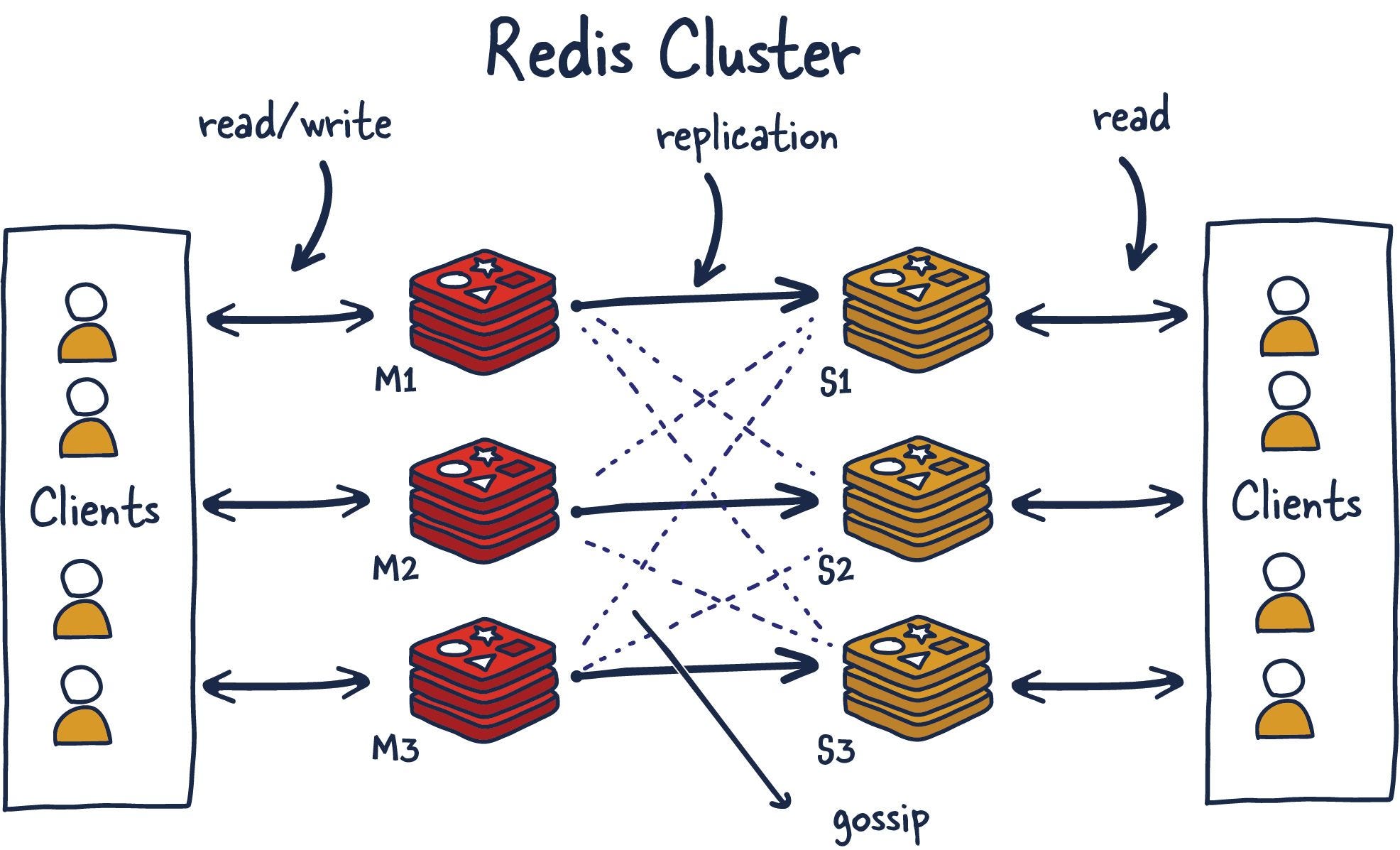

Hash Slots: The Thing That Will Break at 3AM

Redis splits your data across exactly 16,384 hash slots using CRC16(key) mod 16384. Sounds simple, right? It is, until you get that call at 3AM because some genius decided to run FLUSHALL on a single node and now half your slots are fucked.
The slot system is actually pretty clever:
- Each key goes to exactly one slot (no guessing games)
- Moving slots only copies the affected keys (not everything)
- Failover happens fast because replicas already know which slots they own
But here's what they don't tell you: if you lose the wrong combination of nodes, your cluster becomes read-only faster than you can say "split-brain scenario." I learned this the hard way when AWS decided to reboot three of our instances simultaneously during a "routine maintenance window."
I/O Threading: Finally Not Complete Garbage
Redis 8's I/O threading finally works without causing weird race conditions every other Tuesday. In previous versions, enabling threading was like playing Russian roulette - sometimes you'd get better performance, sometimes your cluster would just decide to stop talking to itself.
The threading helps clusters specifically because:
## Redis 8 clustering configuration example
io-threads 4 # Enable I/O threading (match CPU cores)
io-threads-do-reads yes # Process reads with threading
cluster-enabled yes # Enable cluster mode
cluster-config-file nodes.conf # Cluster state persistence
Pro tip from someone who debugged this shit for weeks: The gossip protocol (cluster bus) used to choke under heavy load in Redis 6/7. You'd see 5-second latency spikes during slot migrations that would make your monitoring explode with alerts. Redis 8 actually handles this without making you want to switch careers.
Redis High Availability Architecture: In a Redis Sentinel setup, you have multiple Redis instances (master and replicas) monitored by Sentinel processes that detect failures and coordinate automatic failover. This ensures your cluster stays available even when individual nodes crash. The gossip protocol enables nodes to communicate their status and detect failures within seconds, triggering automatic promotion of replica nodes to master status.
Network Setup: Where I've Fucked Up So You Don't Have To
I learned the hard way that Redis clusters need TWO ports per node, and I've personally watched engineers lose entire weekends forgetting this:
- Client port (6379): Where your app connects
- Cluster bus port (16379): Where nodes gossip about each other like high schoolers
I've literally sat there watching redis-cli --cluster create hang forever with zero useful error messages, cursing Redis's shitty diagnostics, only to realize I missed the bus port in my firewall rules. Again.
## Firewall configuration example for 3-node cluster
## Node 1: 192.168.1.101
## Node 2: 192.168.1.102
## Node 3: 192.168.1.103
## Allow client connections on port 6379
iptables -A INPUT -p tcp --dport 6379 -s 192.168.1.0/24 -j ACCEPT
## Allow cluster bus communication on port 16379
iptables -A INPUT -p tcp --dport 16379 -s 192.168.1.0/24 -j ACCEPT
War story: Our entire cluster went down during "routine network maintenance" because the network team forgot about port 16379. Spent 4 hours on a Saturday troubleshooting "why are all nodes showing as failed?" while the CTO kept asking for ETAs. Turns out one firewall rule was blocking the cluster bus and the whole thing collapsed like a house of cards. The Redis cluster troubleshooting guide mentions this, but doesn't emphasize how catastrophic it is. Also check this Stack Overflow thread about cluster timeouts.
Lesson learned: Make that bus port part of your infrastructure checklist, or you'll be explaining to management why the entire user session cache disappeared.
Memory Planning: Or How I Learned to Stop Trusting Calculators
I've never seen a Redis cluster that didn't eat more RAM than we planned for. Not once. Here's what actually consumes memory and why I always budget extra:
- Cluster metadata: Starts at 5MB per node but I've seen it hit 15-20MB with enough keys
- Replication buffers: These explode during network hiccups - learned this at 2AM when our buffers hit 2GB each
- Slot migration overhead: Keys exist in TWO places during resharding, sometimes for hours
Redis Memory Monitoring: Effective memory monitoring requires tracking used_memory, maxmemory_policy effectiveness, evicted_keys count, and replication buffer usage across all cluster nodes. Key metrics include memory fragmentation ratio and peak memory usage during slot migrations.
Real talk: I watched our AWS bill go from around $800 to something like $3200 overnight when I misconfigured the replication buffer size. Turns out 1GB per replica adds up fast when you have 12 replicas, and I had to explain to my manager why I didn't catch this in staging. The Redis memory optimization docs have the math, and this GitHub issue explains why the defaults are so conservative - they've been burned too.
## Production memory configuration for Redis 8 clusters
maxmemory 8gb # Set explicit memory limit
maxmemory-policy allkeys-lru # Eviction policy
client-output-buffer-limit replica 256mb 64mb 60 # Replication buffer sizing
repl-backlog-size 128mb # Increase from 1MB default
The official memory guide has nice formulas, but reality is messier than their math suggests. I've learned to budget 40-50% extra RAM for cluster overhead, not the 20-30% you see in blogs. This comes from watching too many out-of-memory kills during slot migrations - it happens fast and it's brutal. Here's a detailed analysis of cluster memory usage and a case study from Airbnb about their clustering memory lessons that mirror my own painful experiences.
Query Engine Scaling: Actually Pretty Cool
Redis 8's Query Engine horizontal scaling is one of the few new features that actually works as advertised. Your search and vector queries can now spread across multiple nodes instead of choking a single instance.
This was impossible before Redis 8, which meant we had to do hacky workarounds with custom sharding logic that nobody understood and everyone feared touching. Check out Redis Search documentation and this performance comparison against Elasticsearch.
## Redis 8 Query Engine clustering example
## Enables distributed search across cluster nodes
FT.CREATE products ON HASH PREFIX 1 product: SCHEMA name TEXT price NUMERIC
## This index will automatically distribute across all cluster nodes
Translation: your vector similarity searches won't timeout anymore when your AI team decides to index 50 million embeddings without telling anyone. Learned that lesson when our ML models started failing silently because the search queries were taking 30+ seconds. Here's the vector similarity search guide and a detailed benchmark study showing why this matters for ML workloads.
Redis Performance Scaling: Redis 8 benchmarks consistently show 150K+ operations per second on modern hardware, with linear scaling as you add cluster nodes. The I/O threading improvements mean you can actually utilize multi-core systems effectively, unlike older Redis versions that were stuck on single-threaded performance.
Modern Deployment Patterns: What Actually Works
Redis 8 clustering finally plays nice with containers, which is a fucking miracle considering how much of a pain Redis 6/7 clustering was in Docker environments. I've tried them all, so here's my honest take:
Docker Compose: Perfect for local dev - spin up a 6-node cluster in under a minute. But I've seen teams try to run this in production and it's a disaster. The networking is too fragile when nodes restart and you'll spend your weekends debugging why node discovery keeps failing.
Kubernetes with Helm: The Bitnami chart is actually solid - I've deployed it at 3 different companies and it just works. Takes about 30 minutes to get production-ready versus the 6+ hours I used to spend manually configuring everything.
Cloud Managed: AWS ElastiCache for Redis finally supports Redis 8 as of late 2024, Azure Cache is still catching up but they're usually 6-12 months behind anyway.
The reason containerized deployments work better now is because Redis 8's I/O threading doesn't shit the bed when CPU is throttled, and the gossip protocol doesn't timeout every time there's a brief network hiccup. Before Redis 8, container networking would constantly trigger false failovers.
When Clustering Makes Sense (And When It Doesn't)
Use Redis clustering when:
- Your data won't fit on one beefy machine: If you need more than ~100GB, clustering starts making sense
- You need write scaling: Single Redis instance maxes out around 100K writes/sec
- You can handle the operational complexity: Because clustering will 3x your troubleshooting time
- You have monitoring that doesn't suck: You'll need it when (not if) things break
Don't cluster if your data fits comfortably on one machine. Seriously. Redis Sentinel gives you high availability without the clustering headaches. Our team spent 6 months fighting cluster issues before realizing we could have just used a bigger server. The Redis Sentinel documentation explains the simpler high-availability option, and here's a comparison of clustering vs Sentinel from Stack Overflow.
Understanding these fundamentals is essential before moving to the practical setup process, which involves specific configuration steps and deployment decisions that can make or break your cluster's performance and reliability.