I've been testing Llama 3 since it came out in April.
Here's what actually works and what's bullshit.
I deployed Llama 3 70B for our customer support system in early May. AWS bills were brutal the first month
- something like $3k+ while we figured out the quantization wasn't working right. Here's the real deal.

What Meta doesn't tell you in their blog posts
The 8B model is trash for anything serious. Yeah, it runs on a MacBook Pro, but so does a calculator.
I tried using it for code review
- it missed obvious SQL injection vulnerabilities that a CS student would catch. Stick to the 70B if you want something that won't embarrass you in front of your users.
Memory requirements are complete lies. They claim 80GB for the 70B model. Reality: you need way more memory than they claim, like 140GB+ with proper quantization, and even more if you want it to not randomly crash during long conversations.
Found this out when our production server OOMkilled middle of the night on a weekend.
The "128K context" marketing is mostly horseshit. Sure, it technically supports 128K tokens, but performance degrades massively after ~32K. I tested it with a huge legal document
- took forever to process and gave completely wrong answers about sections it definitely read.
What actually works well
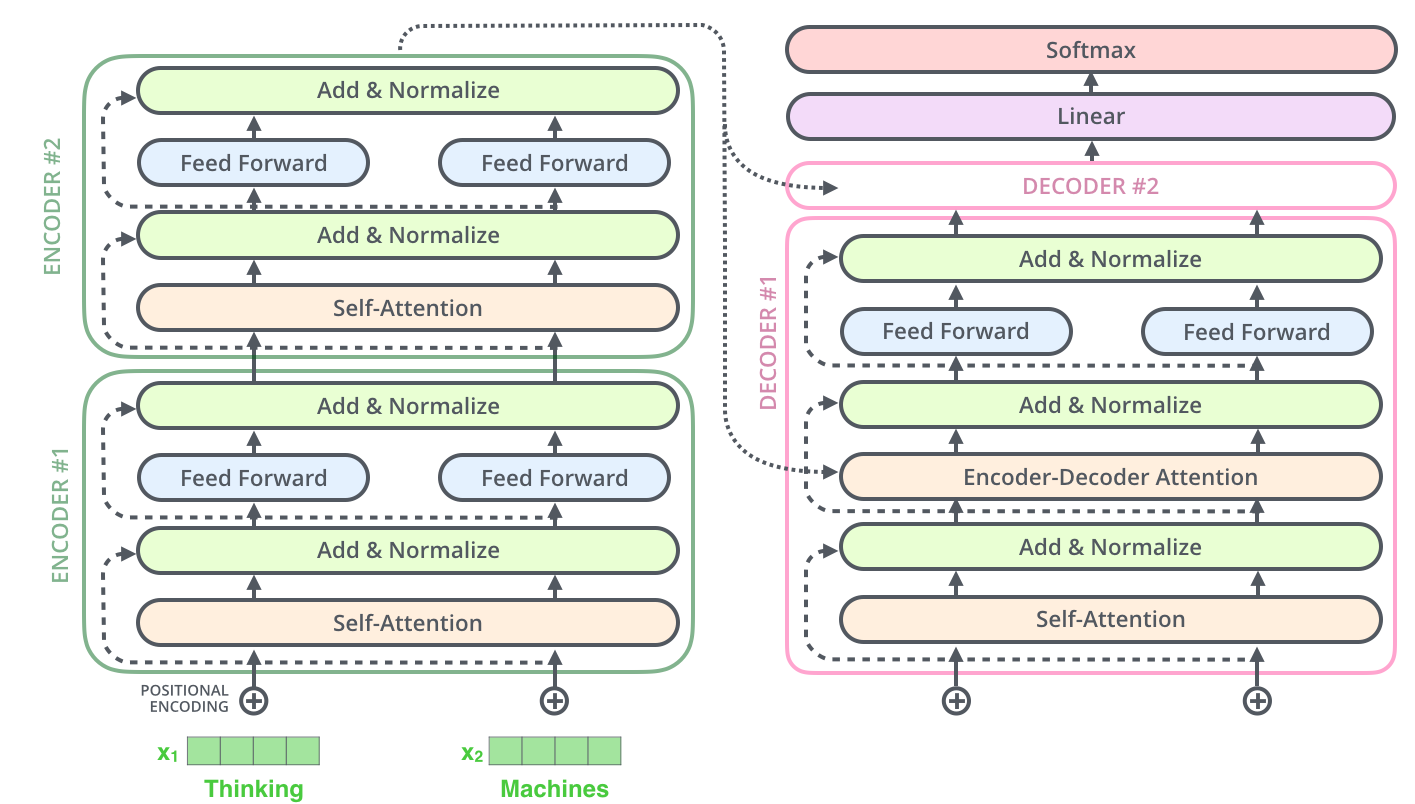
Code generation is legitimately good. Not GPT-4 level, but solid enough that I use it daily.
It understands our Python codebase structure and generates decent Fast
API endpoints. The 70B model nails most pandas operations correctly.
It doesn't phone home your data. Unlike OpenAI's API where your prompts disappear into the void, everything stays on your servers. Worth it for the legal/compliance folks who freak out about data residency.
Fine-tuning actually works. Spent 3 days training it on our support tickets. The results were surprisingly good
- better than GPT-3.5 for our specific use cases. LoRA fine-tuning is the sweet spot
- full fine-tuning is overkill unless you're Google.
The real costs nobody talks about
GPU rental will murder your budget. We're burning around $800-900/month on AWS g5.24xlarge instances just for inference. That's before you factor in the data transfer costs when your model hallucinates and users retry their queries.
Quantization breaks things randomly. The INT8 quantization works most of the time, but occasionally gives completely different answers for the same prompt. Found this during A/B testing
- bunch of responses were noticeably worse with quantization enabled.
Deployment is a pain in the ass. The official GitHub repo assumes you have a PhD in distributed systems. Took our DevOps team 2 weeks to get a stable deployment pipeline. Docker containers randomly segfault with large contexts because of course they do.
Why I still recommend it (with caveats)

Despite the frustrations, Llama 3 70B is the first open-source model that doesn't make me want to throw my laptop out the window.
It's not perfect, but it's good enough for production if you know what you're doing.
Use it if: You need data privacy, have compliance requirements, or want to avoid OpenAI's per-token pricing that scales with your success.
Skip it if: You're prototyping, need multimodal capabilities, or don't have someone who understands transformer serving architecture.
The Hugging Face implementation is your best bet for getting started. Their transformers library handles most of the edge cases, and the community has solved the weirdest deployment issues.
Bottom line: Llama 3 70B is production-ready if you treat it like enterprise software, not a demo. Plan for 2x the resources Meta claims, test thoroughly, and have monitoring that actually works.



