![]()
Look, I'll cut through the marketing bullshit. Sonnet 4 is noticeably better at coding tasks. My usual debugging tests went from failing about 40% of the time to maybe 25-30%. Noticeable difference when you're trying to actually ship code.
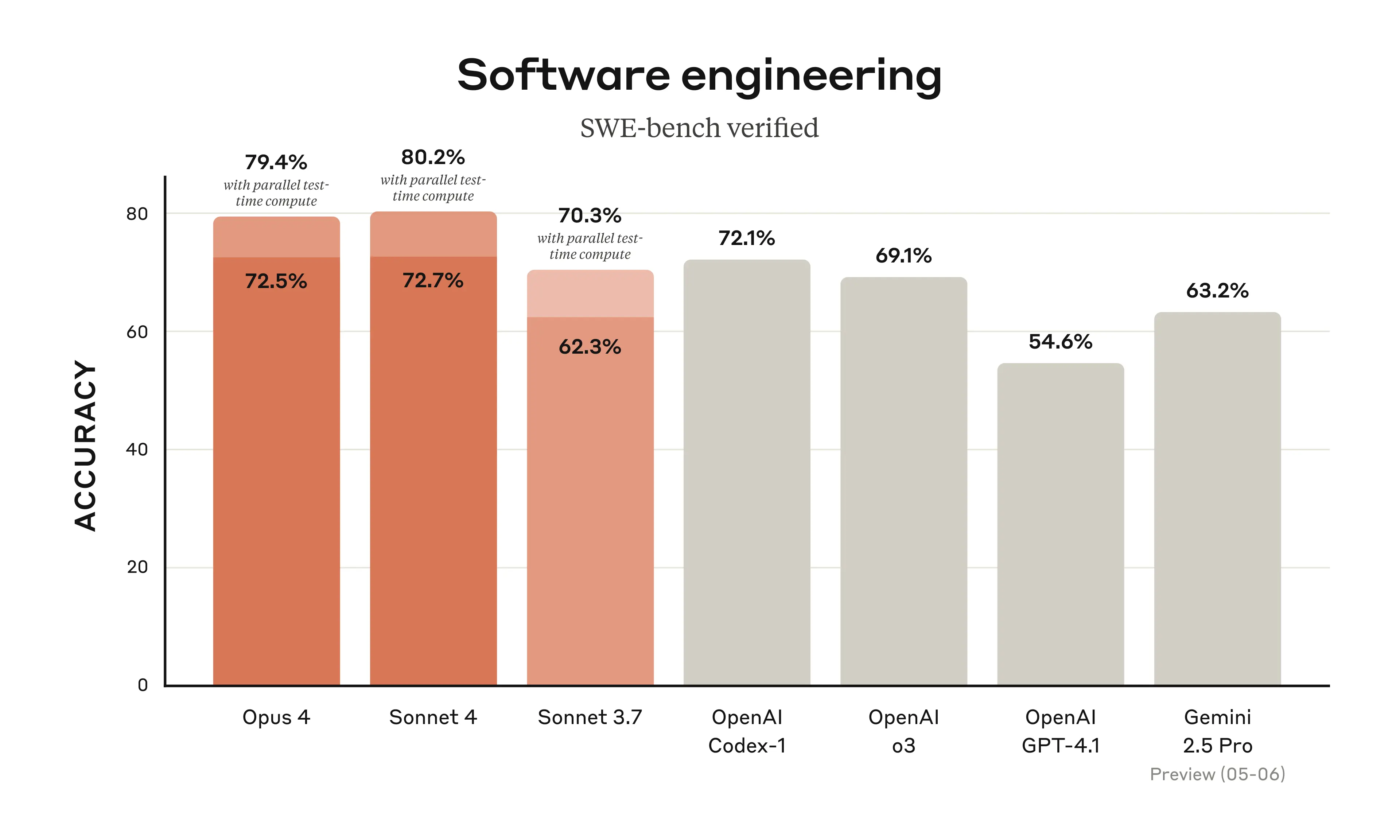
Yeah, the benchmarks actually match what I'm seeing - Sonnet 4 scores 72.7% compared to 3.7's 62.3% on real software engineering tasks. GPT-4.1 only hits 54.6% on the same stuff.
The Coding Got Way Better
Here's what changed: Sonnet 4 can actually follow complex debugging sessions without losing the thread. I had this React component that was throwing weird state update errors - kept getting the dreaded "Cannot update a component while rendering a different component" error. Fed the full component to 3.7 and it gave me generic advice about useEffect dependencies. Sonnet 4 immediately spotted the race condition in my state setter that was causing the cascade.
The big win is that it doesn't lose track of what it's doing in large codebases. I dumped a 2000-line file into it, asked for refactoring, and it actually remembered the architecture. 3.7 would forget the beginning by the time it reached the end.
GitHub started using it for Copilot, so it's definitely not just hype.
Extended Thinking Mode is Actually Useful

The "thinking" feature sounds gimmicky but it's actually useful for gnarly problems. When I give it a tricky algorithm problem or ask it to debug something with multiple interacting systems, the extra thinking time produces way better results than instant responses.
Downside: it's slow as hell. If you're trying to iterate quickly on simple problems, the 5-10 second thinking delay gets annoying fast. I use quick mode for basic stuff and extended thinking for the complex debugging.
Same Price, Better Output Limits
They didn't raise the API pricing ($3 input/$15 output per million tokens), which is nice because API bills are brutal enough already. The big improvement is the output limit - went from 8k tokens to 64k tokens. This means it can actually complete large code generation tasks without getting cut off mid-function.
I was working on a data migration script that needed to handle 15 different edge cases. With 3.7, I'd get halfway through and hit the token limit. Sonnet 4 spit out the complete 800-line script in one go. 64k tokens is roughly 50,000 words of output - enough for entire application modules.
Where It Still Sucks
It's not perfect. Sometimes it gets overly verbose when you give it a lazy prompt. Ask it to "make this code better" and you'll get 500 lines of overengineered garbage with dependency injection patterns you didn't ask for. You need to be specific about what you actually want.
It also makes up documentation sometimes. Spent 2 hours debugging one of its "solutions" that didn't work. It suggested using a useState pattern with async/await that causes infinite re-renders. Spent hours debugging why my component kept crashing before realizing async state updates don't work that way in React. Now I always double-check API references. This thing will confidently suggest patterns that look right but break in practice.
