GPT-5 dropped on August 7, 2025, and it's OpenAI's attempt to build one model that handles everything from "what's 2+2" to "debug this 50,000-line codebase." The official announcement makes it sound revolutionary, but the big idea is simpler: instead of you picking between fast/slow models, GPT-5 picks for you. Check out Microsoft's integration coverage for enterprise perspective, and DataCamp's comprehensive analysis covers the technical features in detail.
Sometimes this works great. Sometimes you wait 30 seconds for it to "deeply reason" about your typo. The model tries to be smart about routing simple stuff to a fast path and complex problems to a slower thinking mode, but its definition of "complex" doesn't always match yours. I've had it spend 25 seconds reasoning through 'convert this to uppercase' while ignoring actually complex database queries.
What's actually happening when it "thinks"
Here's how GPT-5 actually works under the hood:
- Router: Tries to be smart about what needs the full brain vs fast mode. Gets it wrong like 20% of the time, so you'll wait 30 seconds for it to deeply ponder your typo.
- Fast Mode: Sub-second responses for "easy" stuff. Works great until it decides your API call is too simple and gives you a one-word answer.
- Thinking Mode: Burns through tokens while "reasoning." Asked it to explain a simple function once - went into deep thought mode and cost me like 10 bucks explaining variable scope. For a three-line function.
The 400K token context window is designed to drain your bank account. Accidentally fed it our entire codebase and got a $380 or something crazy AWS bill. GPT-4's 128K limit suddenly looks reasonable.
Performance reality check
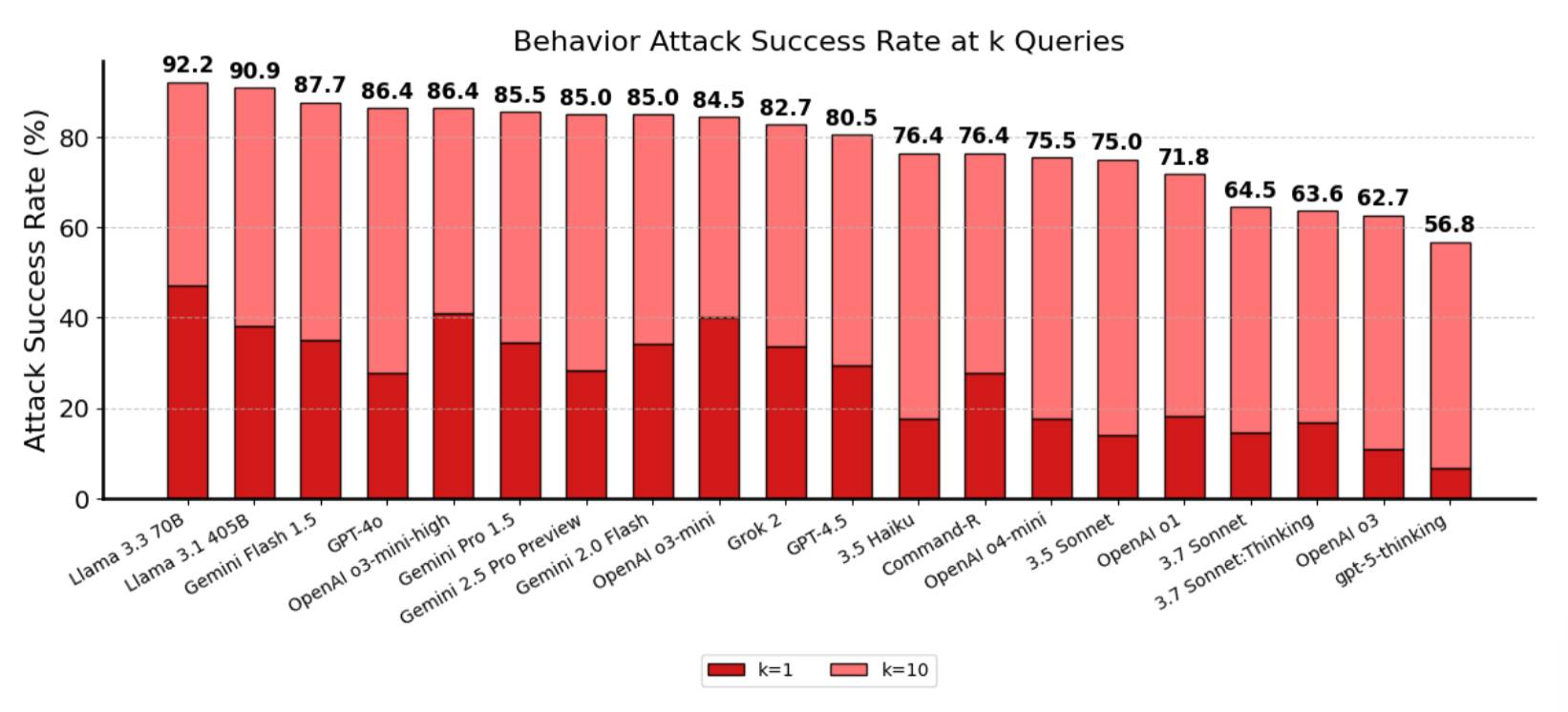
OpenAI's system card claims some impressive numbers, and independent evaluations by METR provide additional technical analysis. MIT Technology Review and CodeRabbit's technical benchmark offer detailed performance comparisons. But here's the reality from actual usage:
- Coding Performance: Beats GPT-4 on benchmarks. In practice, generates more verbose code that your team will hate reviewing.
- Reasoning Tasks: Good at math problems that fit in textbooks. Still struggles with "why is my Docker container randomly dying."
- Hallucination Reduction: 45% fewer made-up facts. That still leaves plenty of confident bullshit to catch.
- Multimodal: Handles images and text together. Voice is decent but not magic.
Real-world benchmarks show decent performance, and Artificial Analysis data provides additional context. However, coding quality analysis and technical evaluations reveal the truth: GPT-5 writes code like a junior dev who discovered comments last week. Functional, but you'll spend more time cleaning it up than you'd like.
The model lineup (and which one won't bankrupt you)
OpenAI offers three flavors, each with the same 400K context window but wildly different costs:
GPT-5 (Standard)
- What it's for: When you need the full brain and have money to burn
- Reality check: $1.25 input/$10 output per million tokens. Use this for complex stuff only.
- Best for: Code reviews, architecture decisions, anything worth paying premium for
GPT-5 Mini
- What it's for: The sweet spot for most developers
- Reality check: $0.25 input/$2 output. Still smart enough, way cheaper.
- Best for: Everything else. Seriously, start here and upgrade only when needed.

GPT-5 Nano
- What it's for: When you need answers yesterday
- Reality check: $0.05 input/$0.40 output. Fast responses, simpler reasoning.
- Best for: Chat apps, simple queries, anything latency-sensitive
Pro tip: Mini handles 90% of what you actually need. The full model is impressive but it'll use reasoning mode for shit like "format this JSON" if you're not careful.
What you actually need to know
OpenAI wants GPT-5 to handle multi-step workflows without you babysitting it. Enterprise automation guides outline the potential, integration tutorials show practical implementation, and OpenAI-Anthropic safety evaluation details recent improvements. Sometimes it works, sometimes you're debugging why it decided to rewrite your entire component instead of fixing a typo.
Where it actually helps:
- React/Next.js: Knows the frameworks well, generates decent components. Frontend coding guide shows examples, but you'll still get 200-line files for simple buttons.
- Code Generation: Output is functional but verbose. SWE-bench scores 74.9% on coding tasks. Expect to refactor everything it writes.
- Document Analysis: Good at parsing long docs. Will confidently tell you document sections that don't exist. Asked it to summarize our API docs once and it invented three endpoints we've never built.
- Workflow Automation: Can chain tasks together. Will also chain your bank account to OpenAI's revenue stream.
Real talk: The improved prompt following is nice, but you're still prompt engineering. The model doesn't replace thinking, just makes some thinking faster.
GPT-5 became the default in ChatGPT for everyone on August 7, 2025, replacing GPT-4o. If you're wondering why your ChatGPT responses suddenly got longer and slower, that's why.

