After dealing with production KrakenD deployments for years, these are the problems that wake you up at 3am. Most of them have simple fixes once you know what to look for.
Memory Leaks and OOM Kills
Symptom: KrakenD containers randomly restart, kubectl logs shows exit code 137, Kubernetes keeps killing your pods.
This usually hits when you're handling concurrent requests without proper resource limits. KrakenD spawns goroutines like crazy during traffic spikes, and if you don't configure memory limits correctly, Kubernetes will murder your pods. Check the Kubernetes deployment guide and Docker deployment best practices for proper resource configuration.
The fix that actually works:
resources:
limits:
memory: "1Gi"
cpu: "1000m"
requests:
memory: "512Mi"
cpu: "100m"
Set explicit memory limits in your Kubernetes deployment. Don't trust the defaults. I've seen teams lose entire weekends because they skipped this basic step. Also check your circuit breaker configuration - aggressive timeouts can cause request pileups. For monitoring, set up Prometheus metrics and Grafana dashboards to catch these issues early.
Configuration Validation Hell
Symptom: KrakenD starts but endpoints return 404s, config changes don't take effect, mysterious routing issues.
The number one cause: your JSON config has subtle syntax errors that don't break startup but break routing. KrakenD's error messages for config issues are... not great. You'll spend hours debugging what should be a 30-second fix. Use the configuration check command and configuration audit tool to catch these before deployment.
Check this first:
## Always validate before deploying
krakend check --config krakend.json
Common gotchas:
- Missing
http://in backend URLs (this one cost me 2 hours last month) - Trailing slashes in endpoint paths -
/api/users/vs/api/usersare different endpoints - Wrong
url_patternvsendpointmatching - read the docs because this trips everyone up. Also check backend configuration and parameter forwarding guide.
Backend Service Discovery Failures
Symptom: 502 errors, "connection refused", KrakenD can't reach your services even though they're running.
In Kubernetes, this is usually DNS resolution. KrakenD tries to connect to backend-service:8080 but can't resolve the hostname because of namespace issues or service naming problems. Check the service discovery documentation and Kubernetes networking guide.
Debug the networking:
## From inside your KrakenD pod
kubectl exec -it krakend-pod -- nslookup backend-service
kubectl exec -it krakend-pod -- curl your-backend-service:8080/health
## Replace 'your-backend-service' with your actual service name and add http://
Kubernetes-specific fixes:
- Use full service names:
backend-service.namespace.svc.cluster.local:8080 - Check your service selector labels match your backend pods
- Verify port numbers - common mistake is exposing 80 but backend listens on 8080
JWT Validation Breaking Authentication
Symptom: 401 errors for valid tokens, authentication works sporadically, users getting logged out randomly.
KrakenD's JWT validation is picky about token format and timing. Clock drift between services can cause valid tokens to be rejected as expired.
Common authentication failures:
- JWK endpoint unreachable - KrakenD can't fetch public keys
- Token algorithm mismatch - your auth service uses RS256, config says HS256
- Clock synchronization issues - NTP drift causes timing validation failures
The nuclear option that usually works:
{
"auth/validator": {
"alg": "RS256",
"jwk_url": "https://your-auth.com/.well-known/jwks.json",
"cache_ttl": "15m",
"disable_jwk_security": true
}
}
disable_jwk_security is a temporary hack while you fix the real issue. Don't leave it in production.
Rate Limiting Gone Wrong
Symptom: Legitimate traffic getting 429 errors, rate limits triggering during normal load, users complaining about blocked requests.
KrakenD's rate limiting configuration is confusing and the defaults are aggressive. Token bucket settings don't behave like most people expect.
Rate limiting that doesn't suck:
{
"qos/ratelimit/token-bucket": {
"max_rate": 1000,
"capacity": 1000,
"every": "1s"
}
}
Start with generous limits and tune down based on actual traffic patterns. Monitor your rate limiting metrics in Grafana to see what's actually being blocked.
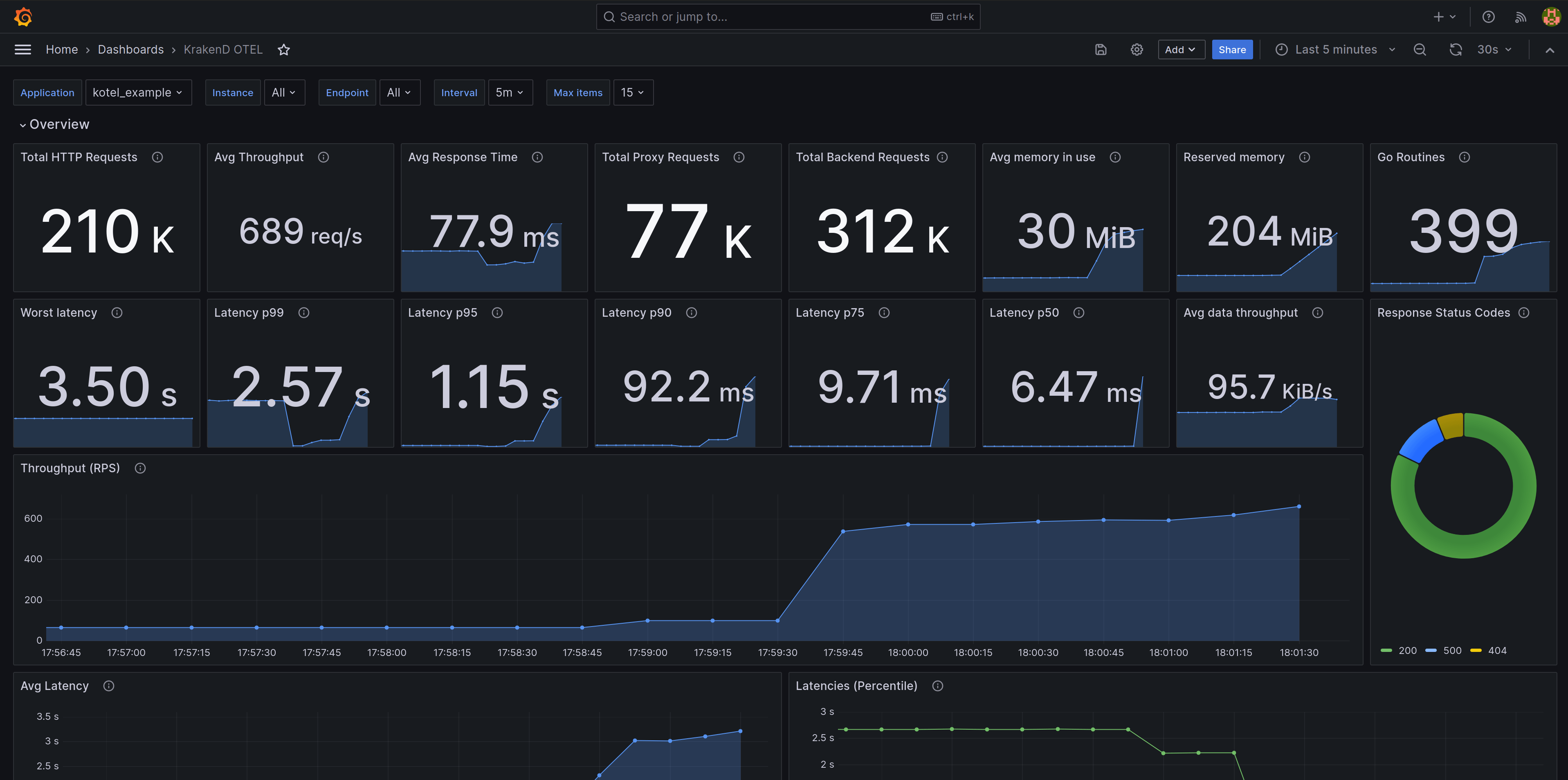
 Response time percentiles by endpoint:
Response time percentiles by endpoint: