Container security scanning turns your 3-minute builds into 15-minute endurance tests. Developers start pushing straight to production to avoid the wait. Security teams wonder why nobody uses their expensive scanning tools. The problem isn't the security - it's the goddamn performance.
I've tested most of the popular scanners, and performance varies like crazy. Same image takes 30 seconds in Trivy but 10+ minutes in some others. The performance differences aren't just academic bullshit - they directly impact whether developers actually use security scanning or create workarounds to bypass it entirely.
I've been stuck fixing this mess at multiple gigs. Startup where developers started pushing directly to prod to avoid our 18-minute builds - CTO called it "agile development." Another place where Trivy kept crashing on our massive Java containers and nobody noticed for weeks because our monitoring was dogshit. Most recent was Harbor's database ate all our disk space. Kept crashing Friday deployments for weeks because nobody thought to check the damn retention settings until I dug into it one weekend.
Each time I cut build times by 60-80% while actually improving security coverage. Not by buying faster hardware (management's favorite suggestion) but by understanding how these scanners actually work and where they waste your fucking time.
The Real Performance Killers
Database downloads kill everything. Most scanners pull down huge vulnerability databases on every run. Trivy's DB is 25MB compressed but balloons to 200MB+ when decompressed. Download it 50 times across different runners and you're burning serious bandwidth. Docker Scout hits rate limits randomly with no warning. Snyk crawls through corporate proxy servers that add 30 seconds per HTTP request. Container vulnerability database optimization can help, but caching is where the real wins are.
## This is what's actually slowing down your builds
time trivy image --download-db-only
## real 4m32s - just downloading the damn database
## user 0m1s
## sys 0m1s
## Errors that will ruin your day:
## FATAL failed to download vulnerability DB
## error downloading vulnerability database: Get \"https://github.com/aquasecurity/trivy-db/releases/download/v2/trivy-offline.tar.gz\": dial tcp: i/o timeout
## ## Or the classic:
## ENOENT: no such file or directory, open '/root/.cache/trivy/db/trivy.db'
## ## Personal favorite when corporate firewall blocks GitHub:
## FATAL failed to download vulnerability DB: context deadline exceeded
Spent half a day debugging that shit once before someone mentioned our corporate firewall was blocking GitHub. Fun times.
You're scanning the same base images over and over. Node apps use node:18-alpine, Python apps use python:3.11-slim, but every pipeline scans the same layers because nobody configured caching right. Docker layer optimization and multi-stage build security scanning help, but you need shared cache volumes that most teams skip.
Everything runs in serial when it could be parallel. Building 5 containers? That's 5×scan_time instead of running them concurrently. CI systems default to sequential builds because it's "safer" but it kills performance. CI/CD pipeline optimization techniques show the patterns, but you need proper resource limits or parallel jobs will crash each other.
Network bullshit in corporate environments. Air-gapped networks with proxy servers add latency to every request. Scanners make dozens of HTTP calls for database updates and result uploads. Add 2-3 seconds per request times 50 requests and your "30-second scan" takes 5 minutes.
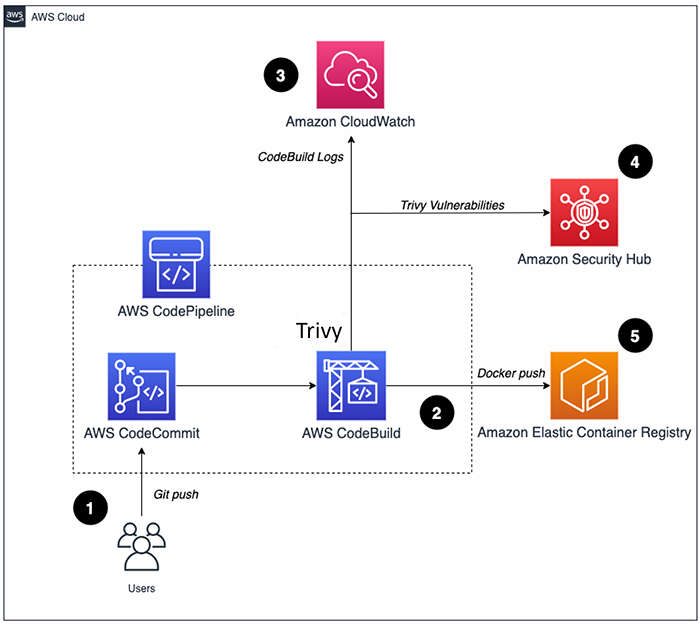
Registry-Side Scanning: The Performance Game Changer
![]()
Here's what actually speeds things up: scan images once when you push them instead of every damn deployment, run scans in parallel instead of watching paint dry, and cache those vulnerability databases because they don't change every five minutes.
The fastest scan is the one you don't run. Registry-side scanning means you scan images once when pushed, then every subsequent deployment just checks the scan results. Harbor registry integration and enterprise container registry comparison show the performance benefits of this approach.
Harbor does this right:
- Scan images automatically on push using Trivy or Clair
- Block pulls of vulnerable images with configurable policies
- Share scan results across all clusters pulling from the registry
- Only rescan when base layers actually change
- Uses Inspector to scan on push
- Integrates with EventBridge for automated responses
- Costs extra but removes scanning from build pipelines entirely
- Can block vulnerable images at deployment time
- Performance comparison with GitLab container scanning shows significant speed improvements
Azure Container Registry:
- Built-in Qualys or Twistlock scanning on push
- Task-based scanning with webhooks for notifications
- Scan results available via REST API for custom integrations
## Harbor webhook configuration for automatic scanning
apiVersion: v1
kind: ConfigMap
metadata:
name: harbor-webhook-config
data:
webhook.yaml: |
targets:
- type: http
address: https://harbor.company.com/service/notifications
skip_cert_verify: false
events:
- push_artifact
- scan_completed
- scan_failed
Parallel Scanning Strategies That Actually Work
GitHub Actions parallel matrix:
GitHub Actions optimization guide covers advanced parallelization patterns that significantly improve scanning throughput.
name: Container Security Scan
on: [push]
jobs:
scan:
runs-on: ubuntu-latest
strategy:
matrix:
image: [api, web, worker, scheduler, metrics]
fail-fast: false # Don't stop other scans if one fails
steps:
- uses: actions/checkout@v4
- name: Scan ${{ matrix.image }}
run: |
docker build -t ${{ matrix.image }}:${{ github.sha }} ./apps/${{ matrix.image }}
trivy image --cache-dir /tmp/trivy-cache ${{ matrix.image }}:${{ github.sha }}
GitLab CI parallel jobs:
stages:
- build
- scan
- deploy
variables:
TRIVY_CACHE_DIR: /tmp/trivy-cache
.scan_template: &scan_template
stage: scan
script:
- trivy image --cache-dir $TRIVY_CACHE_DIR $IMAGE_NAME:$CI_COMMIT_SHA
cache:
key: trivy-db
paths:
- /tmp/trivy-cache/
scan:api:
<<: *scan_template
variables:
IMAGE_NAME: api
scan:web:
<<: *scan_template
variables:
IMAGE_NAME: web
scan:worker:
<<: *scan_template
variables:
IMAGE_NAME: worker
Caching Strategies That Don't Suck
Trivy database caching:
The vulnerability database doesn't change hourly. Cache it properly and share across builds:
## Pre-download and cache the vulnerability database
mkdir -p /tmp/trivy-cache
trivy image --download-db-only --cache-dir /tmp/trivy-cache
## Use the cached database for all scans
trivy image --skip-db-update --cache-dir /tmp/trivy-cache myapp:latest
Layer-aware scanning:
Don't rescan unchanged layers. Most scanners support this, but you need to configure it:
## Trivy automatically skips unchanged layers if you use the same cache directory
trivy image --cache-dir /shared/trivy-cache myapp:v1.0
trivy image --cache-dir /shared/trivy-cache myapp:v1.1 # Only scans changed layers
Build cache integration:
Share scanning cache with your Docker build cache:
## Multi-stage build with scan caching
FROM node:18-alpine AS deps
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
FROM deps AS scanner
## Download vulnerability DB during build
RUN curl -sfL https://raw.githubusercontent.com/aquasecurity/trivy/main/contrib/install.sh | sh -s -- -b /usr/local/bin v0.48.3
RUN trivy image --download-db-only --cache-dir /tmp/trivy-cache
FROM deps AS runtime
COPY . .
EXPOSE 3000
CMD [\"node\", \"server.js\"]
Network Optimization for Air-Gapped Environments
Offline database management:
Air-gapped environments need special handling for vulnerability databases:
## On connected system: download databases
trivy image --download-db-only --cache-dir ./trivy-offline
tar czf trivy-db-$(date +%Y%m%d).tar.gz ./trivy-offline
## Transfer to air-gapped environment
scp trivy-db-20250903.tar.gz air-gapped-system:/opt/trivy/
## On air-gapped system: extract and use
cd /opt/trivy
tar xzf trivy-db-20250903.tar.gz
trivy image --skip-db-update --cache-dir ./trivy-offline myapp:latest
Local registry mirrors:
Set up local mirrors of vulnerability databases and base images:
## docker-compose.yml for local registry mirror
version: '3.8'
services:
registry:
image: registry:2
ports:
- \"5000:5000\"
volumes:
- ./data:/var/lib/registry
environment:
REGISTRY_PROXY_REMOTEURL: https://registry-1.docker.io
trivy-server:
image: aquasec/trivy:latest
ports:
- \"4954:4954\"
command: server --listen 0.0.0.0:4954
volumes:
- ./trivy-cache:/root/.cache/trivy
Selective Scanning: Skip What Doesn't Matter
Not every image needs the same scanning intensity. Production images need thorough scanning. Development images? Maybe just check for critical vulnerabilities.
## Environment-specific scanning policies
production:
severity: [\"UNKNOWN\",\"LOW\",\"MEDIUM\",\"HIGH\",\"CRITICAL\"]
security-checks: [\"vuln\",\"secret\",\"config\"]
timeout: 10m
staging:
severity: [\"MEDIUM\",\"HIGH\",\"CRITICAL\"]
security-checks: [\"vuln\"]
timeout: 5m
development:
severity: [\"HIGH\",\"CRITICAL\"]
security-checks: [\"vuln\"]
timeout: 2m
ignore-unfixed: true
Smart scanning based on image changes:
Only scan images that actually changed:
#!/bin/bash
## Only scan if image layers changed
IMAGE_NAME=\"myapp:${CI_COMMIT_SHA}\"
PREVIOUS_DIGEST=$(docker images --digests myapp | awk 'NR==2 {print $3}')
CURRENT_DIGEST=$(docker images --digests ${IMAGE_NAME} | awk 'NR==2 {print $3}')
if [ \"${PREVIOUS_DIGEST}\" != \"${CURRENT_DIGEST}\" ]; then
echo \"Image changed, running security scan...\"
trivy image ${IMAGE_NAME}
else
echo \"Image unchanged, skipping scan\"
fi
The key to fast security scanning isn't buying more powerful build agents - it's eliminating redundant work and optimizing what remains. Every minute you cut from scanning time is a minute developers can spend building features instead of waiting for builds to complete.