Enterprise container security is broken by design. Not the tools - Trivy, Snyk, Aqua all work fine for small teams. The problem is enterprise environments where nothing was designed to work together.
You've got legacy systems that predate containers, compliance requirements written before Docker existed, and politics between security teams who want everything locked down and developers who need to ship code. Then someone decides to "solve" this by buying a enterprise security platform.
What Actually Breaks Everything
Here's what vendors don't mention in their shiny demos:
Admission controllers will lock you out when they fail. Had this happen during a production outage - webhook couldn't reach the scanner and started blocking everything, including the fix we were trying to deploy. Spent way too long figuring out how to delete the admission controller while everyone waited for the fix.
Developers will route around security controls faster than you can deploy them. Give them a production registry that scans images, and they'll find a way to push directly to ECR within a week. You need admission controllers that check at the Kubernetes API level, not just at the registry.
SIEM integration is broken. Splunk dies on Trivy's massive JSON logs. QRadar can't parse container image digests. Every tool outputs different formats and none of them play nice with enterprise logging infrastructure.
Auditors will ask for impossible reports. They want "proof" that every container was scanned before production. Great - let me magically correlate image digests across 50 clusters with different registries, CD systems, and scanning tools.
The tools that actually work in production (not just demos):
![]()
- Trivy: Open source, works everywhere, but you're on your own for enterprise features
- Snyk: Great developer UX until you hit their scan limits and the bill explodes
- Aqua Security: Expensive but actually handles multi-cluster deployments
- Prisma Cloud: Kitchen sink approach - does everything poorly rather than one thing well
Kubernetes Admission Controllers: The Double-Edged Sword

Kubernetes admission controllers are your nuclear option for container security. They can't be bypassed, can't be disabled by developers, and will absolutely lock you out of your own cluster if you fuck up the configuration.
I've been locked out way too many times. Worst was during Log4J when the admission controller rejected our emergency patch because the scanner webhook was down. Try explaining to incident command why the security system just blocked the security fix. That call with the CISO sucked.
## This will bite you in the ass eventually
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionWebhook
metadata:
name: container-security-webhook
webhooks:
- name: security.example.com
failurePolicy: Fail # This line has ruined many weekends
clientConfig:
service:
name: security-scanner
namespace: security-system
rules:
- operations: ["CREATE", "UPDATE"]
resources: ["pods"]
What they don't tell you about admission controllers:
- They WILL fail during outages and block all pod creation. Always have a kill switch ready
- Performance impact hurts - pod creation gets noticeably slower when every container needs webhook validation
- Certificate management is a nightmare - webhook certs expire silently and suddenly every pod creation fails with "x509: certificate has expired or is not yet valid" errors
- Break-glass procedures don't work when the admission controller itself is preventing the fix
Multi-Cluster Hell: The Enterprise Reality

Here's the thing nobody mentions: enterprise organizations don't have "a Kubernetes cluster." We have dozens of clusters across multiple cloud providers and regions, and every single one has different security requirements because nothing can ever be simple.
The multi-cluster security nightmare:
- Dev clusters where developers push whatever they want and security scanning is "advisory"
- Staging clusters that are supposed to match production but have different base images
- Production clusters where every image must be scanned, signed, and approved by 3 different teams
- Compliance clusters running in air-gapped environments with 6-month-old vulnerability databases
Each cluster needs its own scanning configuration, but management wants "unified reporting." Good luck with that.
## What cluster management actually looks like
for cluster in dev-us-east dev-eu-west staging-us prod-us prod-eu compliance-gov; do
echo "Configuring scanner for $cluster..."
# Different configs for each cluster because reasons
kubectl --context=$cluster apply -f scanner-config-$cluster.yaml
# Error: dial tcp 10.96.0.1:443: i/o timeout - cluster is fucked
# Error: admission webhook "security.scanner.io" denied the request:
# context deadline exceeded (Client.Timeout exceeded while awaiting headers)
# Half of these will fail but you won't know until Monday morning standups
done
The Tools That Actually Work (And Their Problems)
After 3 years of fighting with enterprise container security, here's what I've learned:
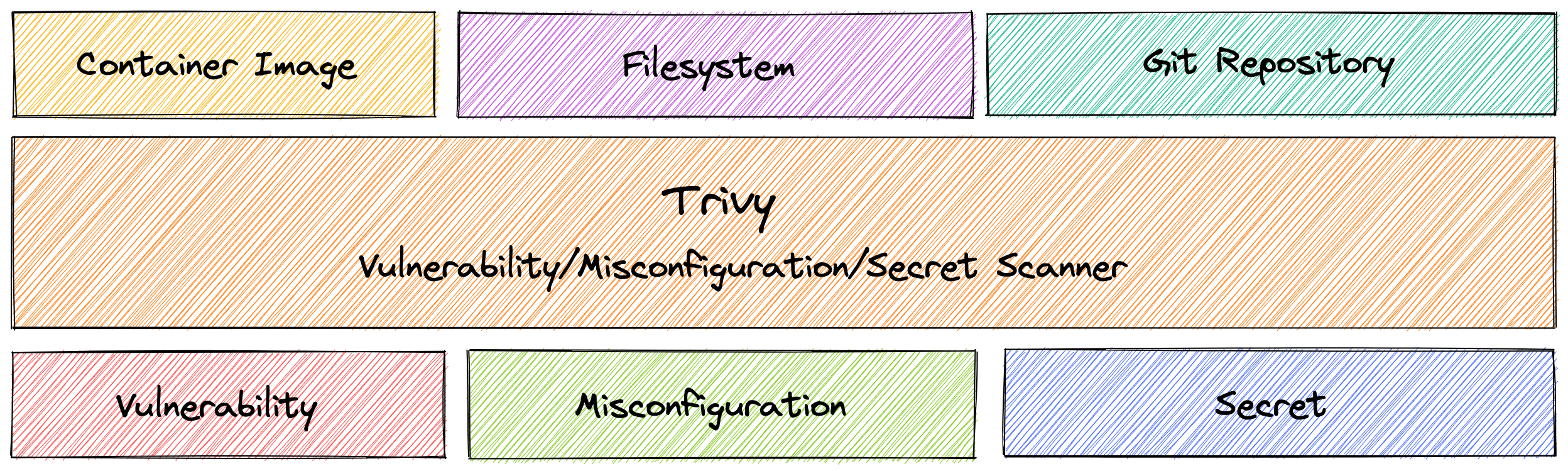
Trivy is solid for open source scanning. Catches most vulnerabilities, works in air-gapped environments, handles the supply chain scanning everyone wants now. But when it breaks during an outage, you're debugging it yourself with GitHub issues and Stack Overflow.
![]()
Aqua Security does multi-cluster management better than anyone else. Their admission controllers don't randomly break and their compliance reports work. Expensive as hell though.
Snyk has great developer UX - they actually use it. Integrates everywhere, doesn't slow down deployments. Until you hit their usage limits and get a massive bill.
Prisma Cloud tries to do everything: container scanning, cloud security, compliance, runtime protection, SIEM integration. It does all of it adequately and none of it exceptionally well. Classic enterprise bullshit - jack of all trades, master of none.
What You Actually Need to Deploy This Shit
Forget the vendor marketing. Here's your real deployment timeline:
Months 1-3: Tool evaluation and procurement hell. Security team wants Aqua, developers want Snyk, compliance wants whatever has the most checkboxes, CFO wants the cheapest option. Somehow nobody ends up happy with the final choice.
Months 3-4: Initial deployment on dev clusters. Everything breaks. Your admission controllers reject legitimate workloads. Your scanning pipelines time out. Your developers start using kubectl port-forward to bypass everything.
Months 5-6: Production rollout. More things break. You discover that your legacy applications don't run as non-root users. Your compliance auditors want reports that don't exist. Your incident response team needs SIEM integration that nobody planned for.
Months 7-12: Actually making it work. You write custom scripts to parse vulnerability data. You implement exceptions for all the legacy applications that will never be fixed. You train developers on new workflows they'll ignore until their deployments start failing.
The vendors will tell you it's a 30-day deployment. They're lying. Plan for a year if you want it done right.
Links That Don't Suck
Real resources that have actually helped me fix things:
- Kubernetes Security Best Practices - The official docs are actually good
- OWASP Container Security Cheat Sheet - Practical advice without the marketing fluff
- Falco Rules Repository - Real detection rules that work in production
- OPA Gatekeeper Library - Policy templates you can actually use
- CIS Kubernetes Benchmark - What auditors actually check for
