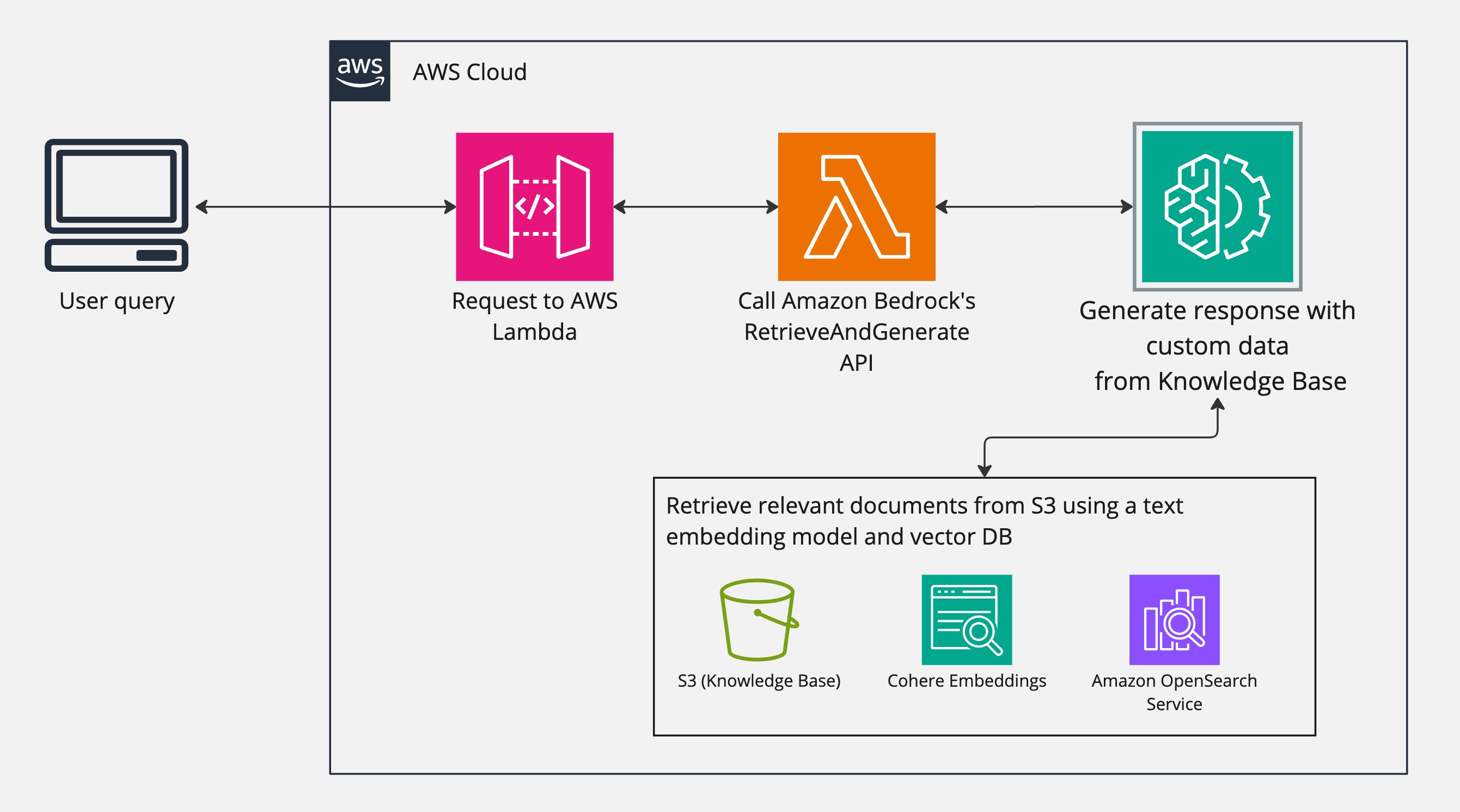
Monitor This Shit Before It Burns You
Look, I learned the hard way during a late Friday deployment. Boss was breathing down my neck, customers were pissed because features went dark mid-afternoon, and I was scrambling to figure out why our "working perfectly in staging" app was getting nuked by rate limits.
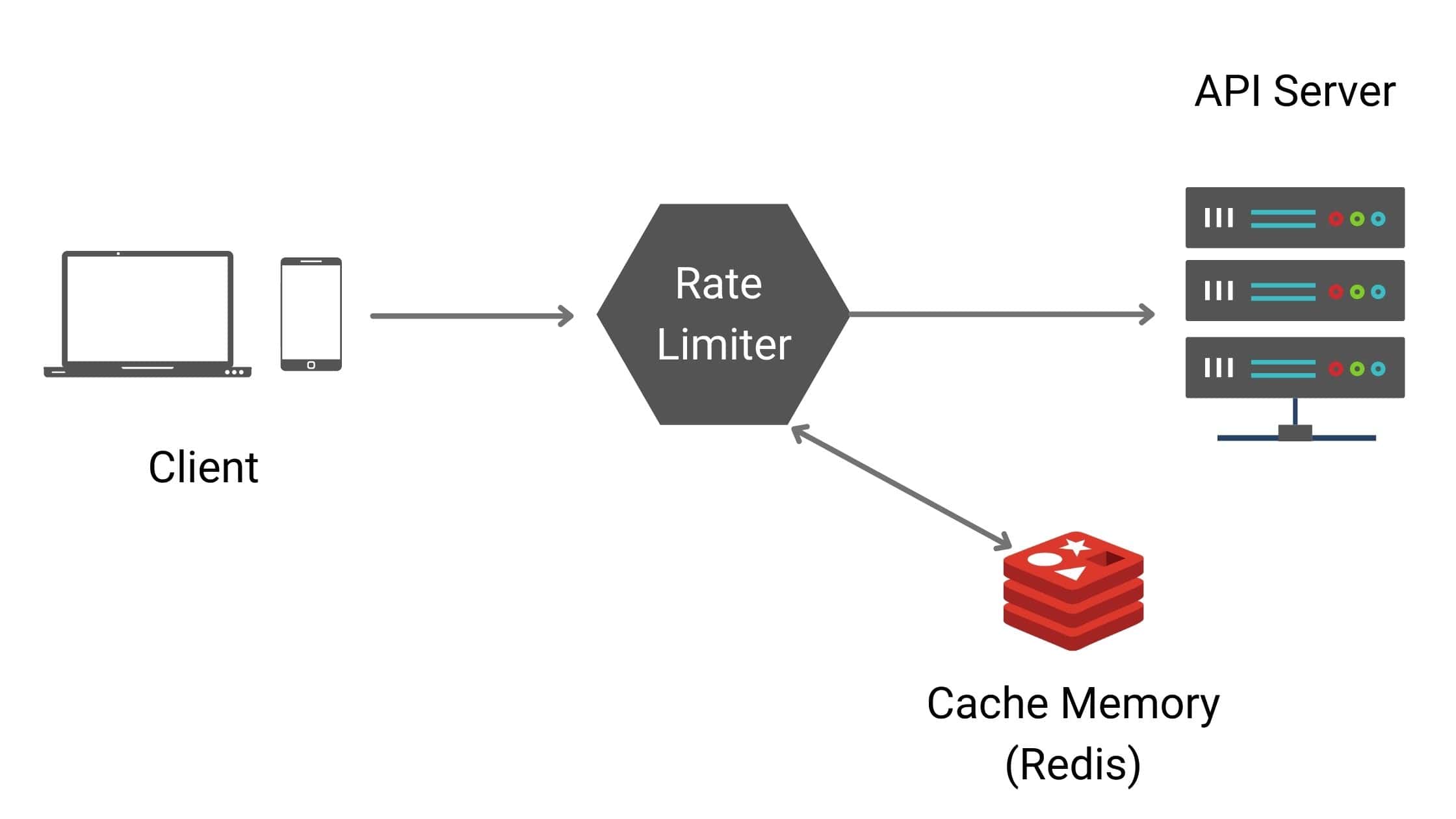
The only way to survive this mess is monitoring everything before Claude decides to fuck you. I've watched too many weekend deployments turn into Monday morning disasters because nobody was watching the token burn rate.
Building a Rate Limit Dashboard
Here's the shit you need to track if you don't want to get blindsided during dinner with your family:
import time
from dataclasses import dataclass
from collections import defaultdict
import asyncio
@dataclass
class RateMetrics:
requests_used: int = 0
tokens_used: int = 0
spend_today: float = 0.0
requests_remaining: int = 0
tokens_remaining: int = 0
reset_time: float = 0.0
class RateLimitMonitor:
def __init__(self):
self.metrics = defaultdict(RateMetrics)
self.usage_history = []
self.alerts_sent = set()
def update_from_response_headers(self, response_headers):
"""Extract rate limit info from Claude API response headers"""
current_time = time.time()
# Parse Anthropic's headers - these change more than Windows update schedules
self.metrics['requests'].requests_remaining = int(
response_headers.get('anthropic-ratelimit-requests-remaining', 0)
)
self.metrics['tokens'].tokens_remaining = int(
response_headers.get('anthropic-ratelimit-tokens-remaining', 0)
)
# Calculate usage rates
requests_limit = int(response_headers.get('anthropic-ratelimit-requests-limit', 50))
tokens_limit = int(response_headers.get('anthropic-ratelimit-tokens-limit', 30000))
requests_used = requests_limit - self.metrics['requests'].requests_remaining
tokens_used = tokens_limit - self.metrics['tokens'].tokens_remaining
# Store historical data
self.usage_history.append({
'timestamp': current_time,
'requests_used': requests_used,
'tokens_used': tokens_used,
'requests_per_minute': self._calculate_rate(requests_used, 60),
'tokens_per_minute': self._calculate_rate(tokens_used, 60)
})
# Check for alert conditions
self._check_alert_conditions()
def _calculate_rate(self, current_usage, window_seconds):
"""Calculate usage rate over time window"""
cutoff_time = time.time() - window_seconds
recent_usage = [
entry for entry in self.usage_history
if entry['timestamp'] > cutoff_time
]
return sum(entry.get('tokens_used', 0) for entry in recent_usage)
def _check_alert_conditions(self):
"""Send alerts when approaching limits"""
tokens_remaining = self.metrics['tokens'].tokens_remaining
requests_remaining = self.metrics['requests'].requests_remaining
# Alert at 80% usage
if tokens_remaining < 6000 and 'token_warning' not in self.alerts_sent:
self._send_alert("WARNING: 80% of token limit reached")
self.alerts_sent.add('token_warning')
# Alert at 90% usage
if tokens_remaining < 3000 and 'token_critical' not in self.alerts_sent:
self._send_alert("CRITICAL: 90% of token limit reached")
self.alerts_sent.add('token_critical')
def _send_alert(self, message):
"""Send alert via Slack, Discord, or whatever doesn't suck"""
# Wake everyone up because Claude is about to ruin your evening
print(f"RATE LIMIT ALERT: {message}")
# This saved my ass during Black Friday when Claude decided to nap
Cost Monitoring (Because CFOs Hate Surprises)
Here's something that bit me in the ass around month three: rate limits are tied to how much you spend. Hit your spending tier max and Claude just stops working. I found out when our analytics job burned through $400 in one night and locked us out until the next billing cycle.
Your CFO will not find this funny. Neither will your customers.
class CostTracker:
def __init__(self):
# Current pricing as of September 2025 - check [Anthropic pricing](https://www.anthropic.com/pricing) for updates
self.model_costs = {
'claude-3-5-sonnet-20241022': {'input': 0.003, 'output': 0.015},
'claude-3-5-haiku-20241022': {'input': 0.00025, 'output': 0.00125},
'claude-3-opus-20240229': {'input': 0.015, 'output': 0.075}
}
self.daily_spend = 0.0
self.monthly_spend = 0.0
self.spending_alerts = {
'daily_limit': 50.0, # Alert at $50/day
'monthly_limit': 1000.0 # Alert at $1000/month
}
def track_request_cost(self, model, input_tokens, output_tokens):
"""Calculate and track cost for API request"""
if model not in self.model_costs:
model = 'claude-3-5-sonnet-20241022' # Default fallback
costs = self.model_costs[model]
request_cost = (
(input_tokens * costs['input'] / 1000) +
(output_tokens * costs['output'] / 1000)
)
self.daily_spend += request_cost
self.monthly_spend += request_cost
# Check spending thresholds
if self.daily_spend > self.spending_alerts['daily_limit']:
self._alert_high_spending('daily', self.daily_spend)
if self.monthly_spend > self.spending_alerts['monthly_limit']:
self._alert_high_spending('monthly', self.monthly_spend)
return request_cost
def project_tier_advancement(self):
"""Predict when you'll advance to next tier based on spending"""
tier_thresholds = {
1: {'deposit': 5, 'monthly_limit': 100},
2: {'deposit': 40, 'monthly_limit': 500},
3: {'deposit': 200, 'monthly_limit': 1000},
4: {'deposit': 400, 'monthly_limit': 5000}
}
for tier, limits in tier_thresholds.items():
if self.monthly_spend < limits['monthly_limit']:
days_remaining = 30 - datetime.now().day
projected_spend = self.monthly_spend + (self.daily_spend * days_remaining)
return {
'current_tier': tier,
'projected_monthly_spend': projected_spend,
'will_advance': projected_spend > limits['monthly_limit'],
'new_limits': tier_thresholds.get(tier + 1, 'Max tier')
}
I spent a miserable Sunday afternoon debugging token usage because our dashboard showed normal patterns but we kept hitting limits around lunchtime. Turns out our "light" analytics job was sending 15KB context windows every request. Nobody caught it until I started logging every single API call.
Most teams have no clue where their tokens disappear until Claude stops working mid-presentation to the board.
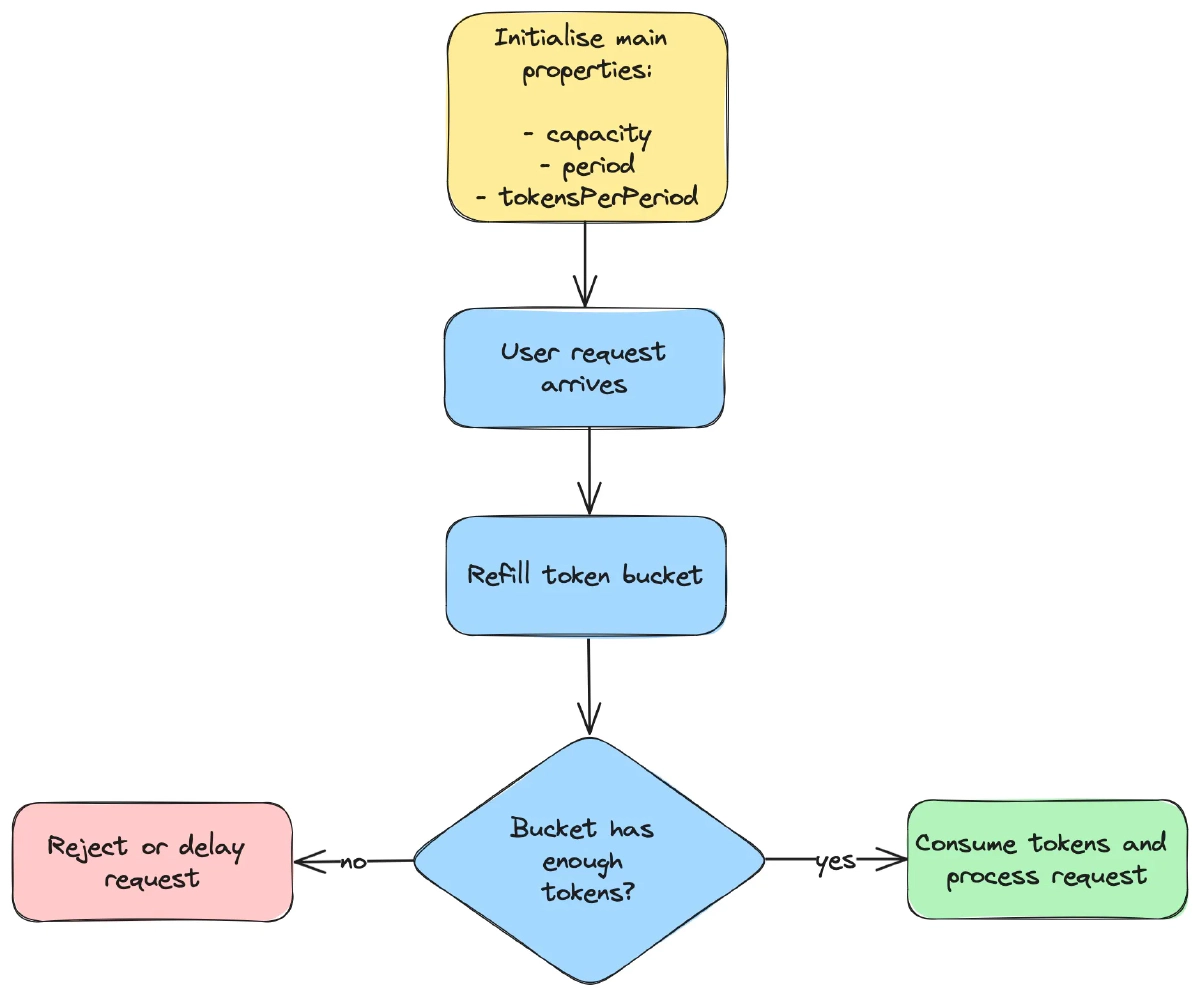
Token Usage Optimization
Many rate limit issues stem from inefficient token usage. Analyze and optimize your prompts using tiktoken for accurate counting and following prompt engineering best practices:
class TokenOptimizer:
def __init__(self):
self.token_estimates = {}
self.optimization_rules = []
def analyze_prompt_efficiency(self, prompt, response, tokens_used):
"""Analyze prompt efficiency and suggest optimizations"""
prompt_length = len(prompt)
response_length = len(response)
efficiency_score = response_length / tokens_used
# Store for historical analysis
self.token_estimates[prompt[:100]] = {
'estimated_tokens': tokens_used,
'prompt_length': prompt_length,
'response_length': response_length,
'efficiency': efficiency_score,
'timestamp': time.time()
}
# Suggest optimizations
optimizations = []
if prompt_length > 5000 and efficiency_score < 0.3:
optimizations.append("Prompt too verbose - consider summarizing")
if "please" and "thank you" in prompt.lower():
optimizations.append("Remove politeness terms to save tokens")
if prompt.count("example") > 3:
optimizations.append("Too many examples - reduce to 1-2 key examples")
return optimizations
def suggest_context_reduction(self, conversation_history):
"""Suggest ways to reduce context without losing important information"""
if len(conversation_history) > 10:
return {
'suggestion': 'Summarize old messages',
'keep_recent': 5,
'summarize_older': len(conversation_history) - 5,
'estimated_token_savings': len(str(conversation_history[:-5])) // 4
}
return {'suggestion': 'Context size acceptable'}
Request Batching and Consolidation
Reduce API calls by intelligently batching requests, implementing patterns found in async Python frameworks and enterprise scaling guides:
import asyncio
from typing import List, Dict, Any
class RequestBatcher:
def __init__(self, batch_size=5, max_wait_time=2.0):
self.batch_size = batch_size
self.max_wait_time = max_wait_time
self.pending_requests = []
self.batch_timer = None
async def add_request(self, prompt: str, callback) -> None:
"""Add request to batch queue"""
self.pending_requests.append({
'prompt': prompt,
'callback': callback,
'timestamp': time.time()
})
# Start batch timer if not already running
if not self.batch_timer:
self.batch_timer = asyncio.create_task(
self._wait_for_batch()
)
# Process immediately if batch is full
if len(self.pending_requests) >= self.batch_size:
await self._process_batch()
async def _wait_for_batch(self):
"""Wait for max_wait_time then process batch"""
await asyncio.sleep(self.max_wait_time)
if self.pending_requests:
await self._process_batch()
async def _process_batch(self):
"""Process all pending requests as a single API call"""
if not self.pending_requests:
return
# Combine prompts into single request
combined_prompt = self._combine_prompts([
req['prompt'] for req in self.pending_requests
])
try:
# Single API call for entire batch
response = await claude_api_call(combined_prompt)
responses = self._split_response(response)
# Distribute responses to callbacks
for req, resp in zip(self.pending_requests, responses):
await req['callback'](resp)
except Exception as e:
# Handle batch failure
for req in self.pending_requests:
await req['callback'](f"Batch error: {e}")
finally:
self.pending_requests.clear()
self.batch_timer = None
def _combine_prompts(self, prompts: List[str]) -> str:
"""Intelligently combine multiple prompts"""
combined = "Process these requests separately:
"
for i, prompt in enumerate(prompts, 1):
combined += f"Request {i}: {prompt}
"
combined += "Provide responses in the same order, clearly labeled."
return combined
def _split_response(self, response: str) -> List[str]:
"""Split combined response back into individual responses"""
# This would need sophisticated parsing based on your use case
responses = response.split("Request ")
return [resp.strip() for resp in responses if resp.strip()]
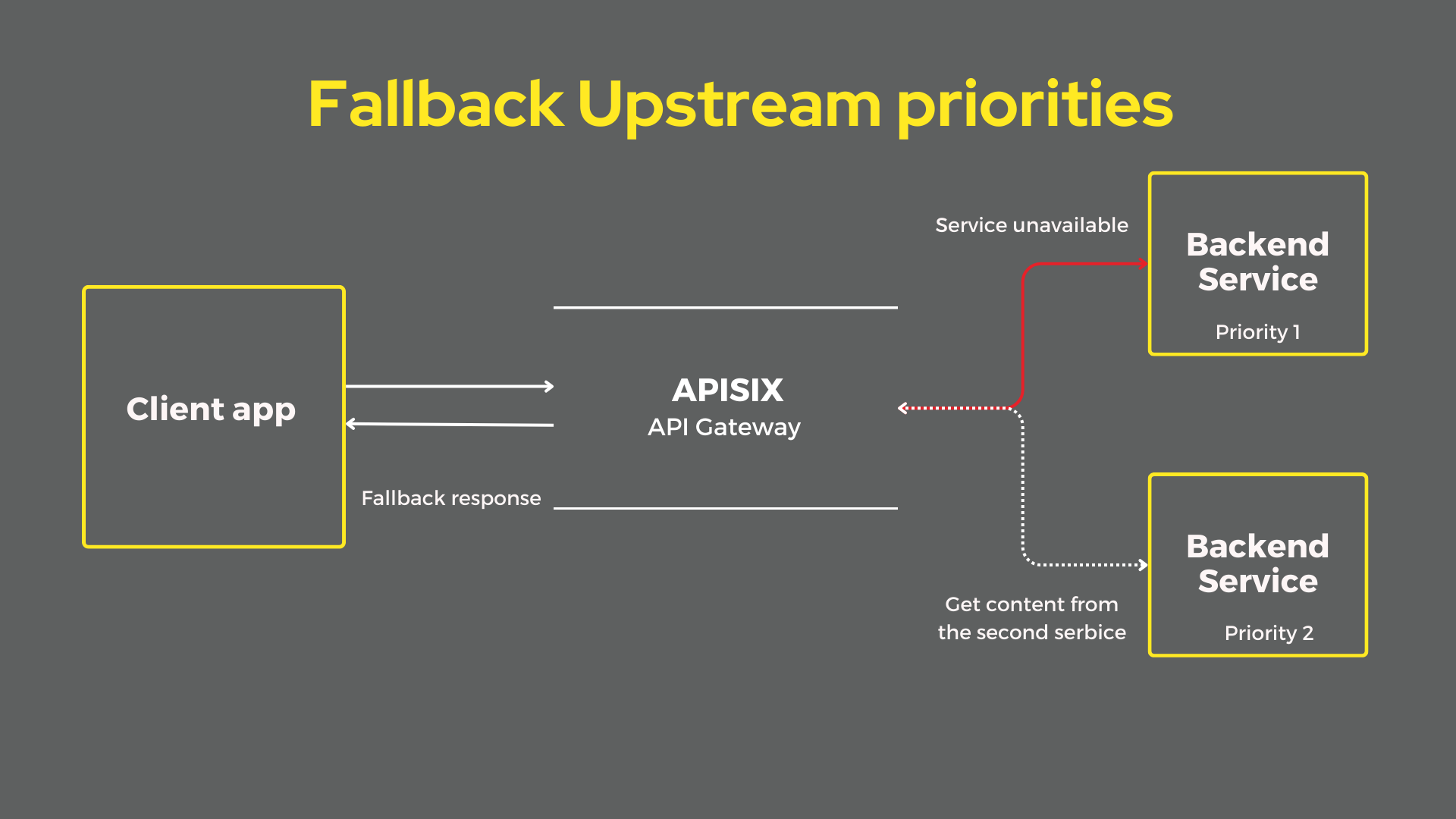
Emergency Response Plans
Rate Limit Crisis Management
When production systems hit rate limits unexpectedly, implement crisis management following incident response best practices and emergency procedures:
class RateLimitEmergencyHandler:
def __init__(self):
self.emergency_mode = False
self.cached_responses = {}
self.fallback_responses = {}
async def enter_emergency_mode(self):
"""Activate emergency procedures when rate limited"""
self.emergency_mode = True
print("🚨 ENTERING RATE LIMIT EMERGENCY MODE")
# 1. Stop all non-critical API calls
await self._pause_background_tasks()
# 2. Switch to cached responses when possible
self._activate_aggressive_caching()
# 3. Enable fallback responses for critical functions
self._prepare_fallback_responses()
# 4. Alert stakeholders
await self._notify_emergency_contacts()
async def _pause_background_tasks(self):
"""Pause non-critical background processing"""
# Cancel scheduled jobs, batch processing, etc.
background_tasks = [
'content_generation',
'data_analysis',
'routine_summaries'
]
for task in background_tasks:
print(f"Pausing {task} due to rate limits")
# Implementation specific to your task scheduler
def _activate_aggressive_caching(self):
"""Use cached responses even if slightly stale"""
# Extend cache TTL from 1 hour to 24 hours during emergency
self.cache_ttl = 24 * 3600
def _prepare_fallback_responses(self):
"""Prepare generic responses for when API is unavailable"""
self.fallback_responses = {
'analysis': "Analysis temporarily unavailable due to high demand. Please try again later.",
'generation': "Content generation is currently limited. Using cached result.",
'classification': "Unable to classify at this time. Manual review required."
}
async def handle_request_during_emergency(self, request_type, prompt):
"""Handle requests during rate limit emergency"""
# 1. Check cache first
cached = self._check_emergency_cache(prompt)
if cached:
return cached
# 2. Try rate-limited API call with extended timeout
try:
result = await self._limited_api_call(prompt)
self._cache_emergency_response(prompt, result)
return result
except RateLimitError:
# 3. Return fallback response
return self.fallback_responses.get(
request_type,
"Service temporarily unavailable due to high demand."
)
These monitoring and prevention strategies help production systems maintain reliability even when Claude API rate limits become restrictive. The key is implementing comprehensive monitoring before problems occur and having automated responses ready for when limits are reached. For additional guidance, see Anthropic's usage best practices, enterprise monitoring solutions, and production reliability patterns.