Xata fixes the specific problem of "my staging environment is using real customer data and I'm probably going to get fired." It does this by making database cloning fast enough that you actually use it, and smart enough to scrub sensitive data automatically.
You don't have to migrate your production database, because nobody wants to spend 3 months begging the DBA to let you touch anything important. Xata works with whatever Postgres setup you already have - AWS RDS, Aurora, Google Cloud SQL, Azure Database, or that crusty server under Jimmy's desk that keeps the lights on.
![]()
Database Branching That Actually Works
The main thing Xata fixes is giving you realistic test data without accidentally leaking customer information all over your staging environment. They use Copy-on-Write storage to create database branches in seconds instead of hours.
This works by separating storage from compute - like Aurora does it, but at the storage level instead of hacking PostgreSQL itself. So you get 100% Postgres compatibility without vendor lock-in bullshit.
Database branching that takes maybe 10 minutes to set up, assuming your VPC doesn't hate you and you don't hit some weird "ENI limit exceeded" error because someone left 200 unused network interfaces lying around. No more "can I get a database copy by next Tuesday?" email chains with IT.
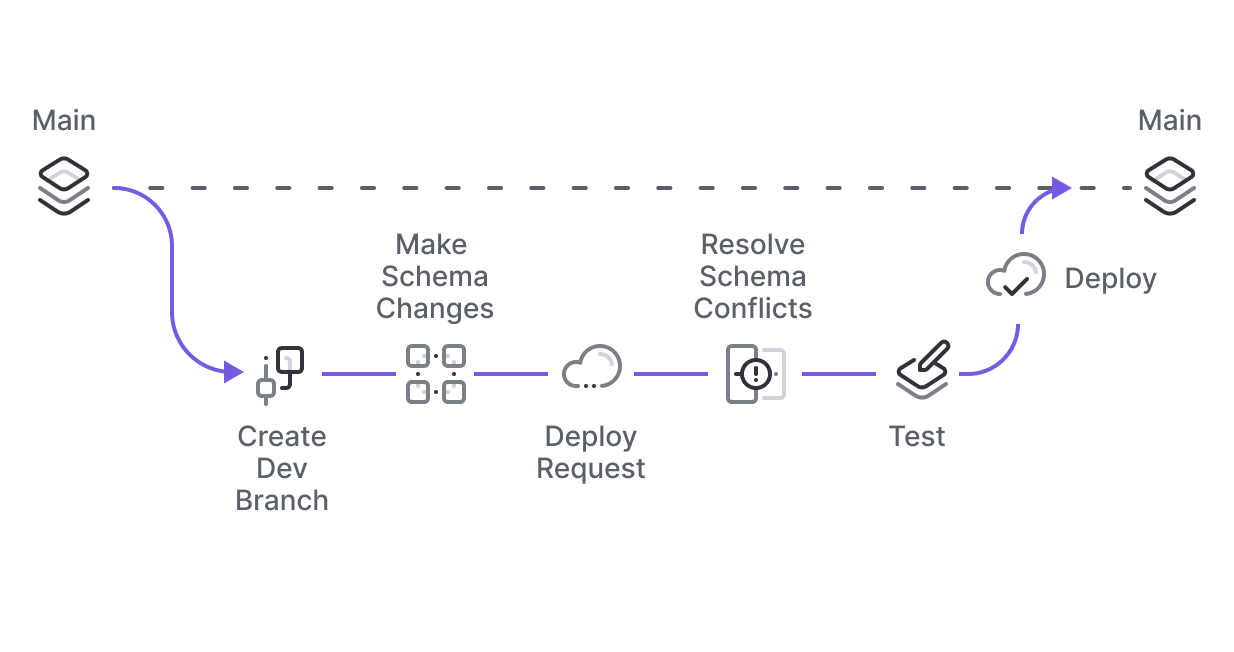
Zero-Downtime Migrations (When They Work)
Xata uses pgroll for schema changes that don't bring down production. pgroll actually works - creates dual schemas using views so old and new code can run simultaneously while you're migrating.
Zero-downtime migrations work great until they don't. Complex foreign key relationships can still be a pain in the ass, and you'll still want to test migrations because Postgres will throw errors like "column contains null values" right when you're trying to add a NOT NULL constraint, even when you swear you checked for nulls first.
Data Anonymization That Actually Works
pgstream handles the data anonymization piece. It's their CDC tool that replicates database changes while scrubbing sensitive data - pretty solid for database infrastructure.
The anonymization maintains referential integrity while masking PII, so your staging environment has realistic data volumes and relationships without actual customer information. Works well for GDPR compliance if you're dealing with that European regulatory nightmare.
AI Database Monitoring That Actually Helps
The Xata Agent monitors your database and suggests optimizations that aren't completely useless. It focuses on actionable insights rather than AI buzzword nonsense, which is refreshing.
It watches your database logs and metrics, identifies slow queries before they crash your app, suggests specific index improvements, and sends alerts via Slack when performance starts going to shit. The AI component uses OpenAI or Anthropic models to analyze patterns, but it won't magically fix a schema designed by someone who thinks foreign keys are optional.
This thing saved my ass when it caught some query doing a full table scan - I think it was on our orders table, maybe 10 million rows? Something huge. The query was taking like 45 seconds and throwing "statement timeout" errors in production. Suggested a composite index on (user_id, created_at) and suddenly queries went from painfully slow to sub-100ms. That kind of specific, actionable feedback is what makes it worth running, not generic "your database is slow" alerts.
Works with AWS RDS monitoring and CloudWatch integration. Check out their documentation for setup instructions and Discord community for troubleshooting help.

