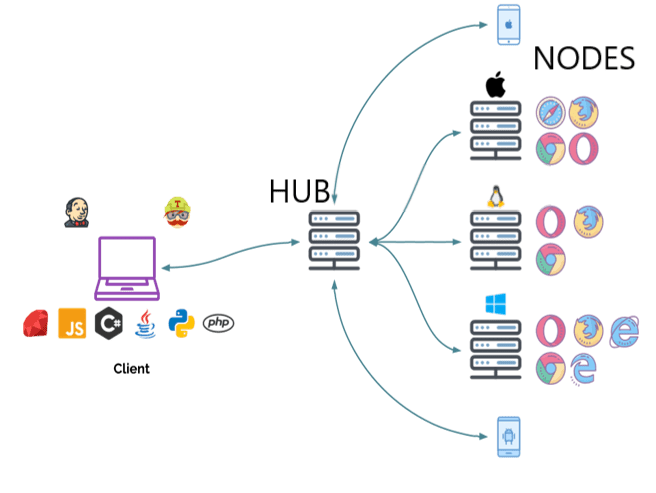
Selenium Grid takes your normal Selenium WebDriver tests and runs them on multiple browsers at once. Instead of your laptop running one Chrome browser testing your app, Grid spins up 5 Chrome browsers on different machines and splits your tests between them.
The catch? Setting up Grid is like assembling IKEA furniture - the instructions look simple until you actually try it. Selenium 4 supposedly made this easier by splitting everything into microservices architecture. In practice, it just gave you more moving parts to break.
The Six Components That Need To Talk To Each Other
Grid 4 split into 6 different services that need to play nice together. The Distributor and Session Map are the ones that'll ruin your day when they break. The Distributor decides which browser gets which test - when it dies, all your tests just hang forever. The Session Map remembers which browser is doing what, and when it gets confused (daily occurrence), tests start sending commands to random browsers.
The Router is basically a traffic cop, the Session Queue holds tests in line, and the Event Bus lets everything gossip with each other. The Node actually runs browsers and is where Chrome crashes, Firefox leaks memory, and everything goes sideways.
Hub-Node vs Fully Distributed (Both Have Problems)
Grid 3 had a simple hub-node setup where one hub managed everything. Grid 4's distributed approach splits the hub into separate services.
The distributed model is supposedly more reliable because if one piece crashes, the others keep working. In reality, you now have 6 things that can break instead of 2. Each component failure manifests differently, making debugging distributed systems a special kind of hell.
The old hub-node model still works and is simpler to understand when things break. For small teams, it's probably the right choice unless you enjoy troubleshooting distributed systems at 2 AM.
When You Request A Browser Session
Here's what happens when your test asks for a Chrome browser:
- Router gets your request for Chrome
- Distributor checks if any Chrome nodes are free
- If all Chrome browsers are busy, Session Queue holds your test
- When a browser frees up, Session Map remembers the pairing
- Node starts Chrome and tells everyone it's ready
- Router sends your test commands to the right Chrome instance
This works great until step 5 fails because Chrome ran out of memory, or step 6 fails because the Session Map forgot which browser was which. The Event Bus is supposed to keep everything synchronized, but events can get lost during network hiccups or component restarts.
When it works, you get parallel test execution. When it breaks, you get tests hanging indefinitely with no clear error messages.