On January 14, 2025, Fly.io fully enabled CPU quota enforcement changes that have fundamentally altered how applications perform on their platform. What used to be 30-second deploys now take 8+ minutes for Django, Rails, and Node.js applications, catching developers completely off-guard with zero email notification about the breaking change.
Understanding the New CPU Throttling System
The core change is brutal in its simplicity: shared vCPUs are now limited to 1/16th of a CPU core (6.25% baseline), while performance vCPUs get 100% of a dedicated core. This means a shared-cpu-1x machine that previously had access to burst CPU power can now only sustain 62.5 milliseconds of CPU time per second.
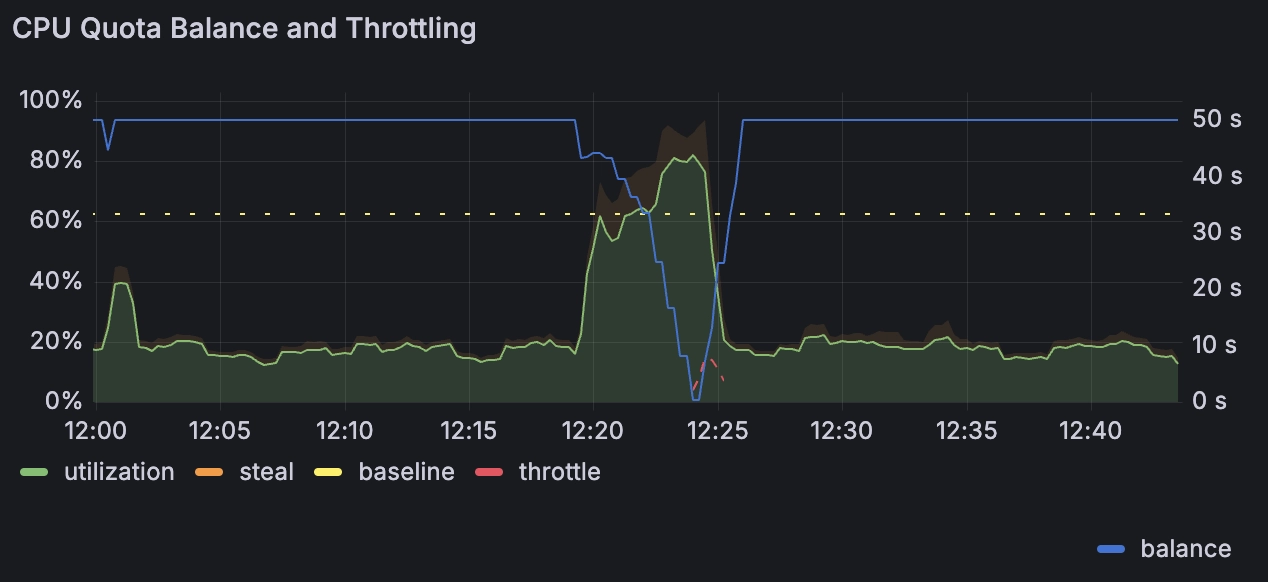
The throttling system works on 80ms cycles, where each cycle grants you 5ms of CPU time on a shared-cpu-1x. Any time you don't use gets banked as "burst balance" - but with a low accrual rate that makes startup-heavy applications suffer dramatically.
The Real-World Impact
Deploy Time Explosions: Applications that previously deployed in 30 seconds now take 8-20 minutes to boot because startup processes get throttled immediately. Django apps loading models, Rails apps precompiling assets, and Node.js apps warming up V8 all hit this wall hard.
Production Outages: Multiple users reported immediate production outages when the enforcement went live. Rolling deployments failed because new instances couldn't pass health checks within reasonable timeframes.
Scaling Confusion: A shared-cpu-8x machine still gets the same 6.25% baseline as shared-cpu-1x, making the scaling meaningless for CPU-bound workloads. Users found themselves forced to upgrade to performance instances just to deploy successfully.
Why Fly.io Made This Change
The Predictable Processor Performance initiative aimed to address "noisy neighbor" problems where some applications consumed excessive CPU, affecting others on the same hardware. The change aligns with industry standards - AWS Lambda has similar throttling, Google Cloud Run limits concurrent requests, and most cloud providers limit shared resources.
However, Fly.io completely botched this rollout. Despite their bullshit claims that "a tiny fraction of organizations" would be affected, the change broke apps everywhere. My production Rails app shit the bed middle of the day with zero warning - I found out when users started complaining about 10-second page loads, not from any email from Fly.io.
Zero fucking email notifications about a change this massive violates every change management practice that real platform providers follow.
The Burst Balance System
Fly.io provides a "burst balance" mechanism to soften the throttling impact. Unused CPU time accumulates and can be spent in bursts, but the math is unforgiving:
- Idle Accumulation: A completely idle
shared-cpu-1xaccrues only 3.75 minutes of burst balance per hour, similar to AWS EC2 burst credits but with much lower accrual rates - Startup Penalty: New machines start with just 5 seconds of burst balance, insufficient for most application startup sequences and unlike Google Cloud Run's generous startup allowances
- Reset on Restart: Restarting a machine after startup mysteriously works better - took me 3 hours of debugging to figure this shit out, but restart the machine and suddenly it's fast again
Performance vs. Shared CPU Economics
So now you're stuck choosing between broken or expensive:
- shared-cpu-1x: $2/month but doesn't work
- performance-1x: $7/month but actually functions
shared-cpu-1x costs $2/month but doesn't work, performance-1x costs $7/month but actually functions. Do the math - about 4x more expensive for basic functionality that worked fine before their throttling disaster. AWS and Google do similar throttling, but they don't spring it on you without warning like Fly.io did.
