The registry discovery nightmare you're about to enter
This discovery phase is tedious as hell but skip it and you'll regret it when you break production.
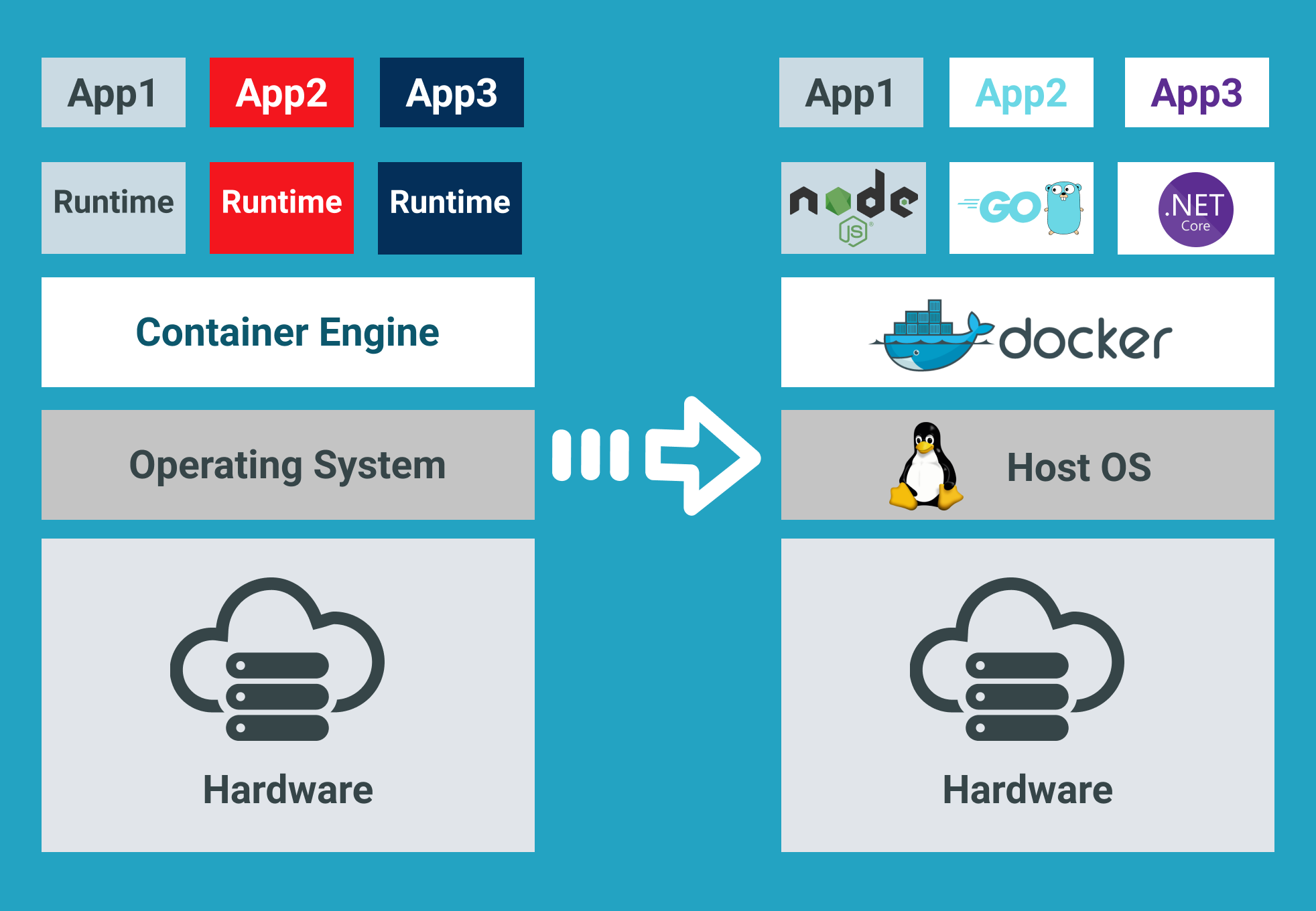
Before you flip the switch on Docker Registry Access Management, you need to figure out what registries your developers are actually using. This always takes longer than you think and you'll always find more shit than you expected. Docker Business runs $24/user/month as of September 2025 and includes RAM along with SSO, SCIM provisioning, and other enterprise features.
Everyone underestimates how many registries they use. I've seen companies that thought they only used Docker Hub and AWS ECR discover they were hitting 15-20 different registries across their teams. Personal registries, vendor registries, that one legacy Harbor instance someone forgot about - it's always a mess.
Reading Docker's security documentation and enterprise security best practices will help you understand why this matters. Container security isn't just about the containers themselves - it's about controlling where those containers come from.
How to actually find all your registries
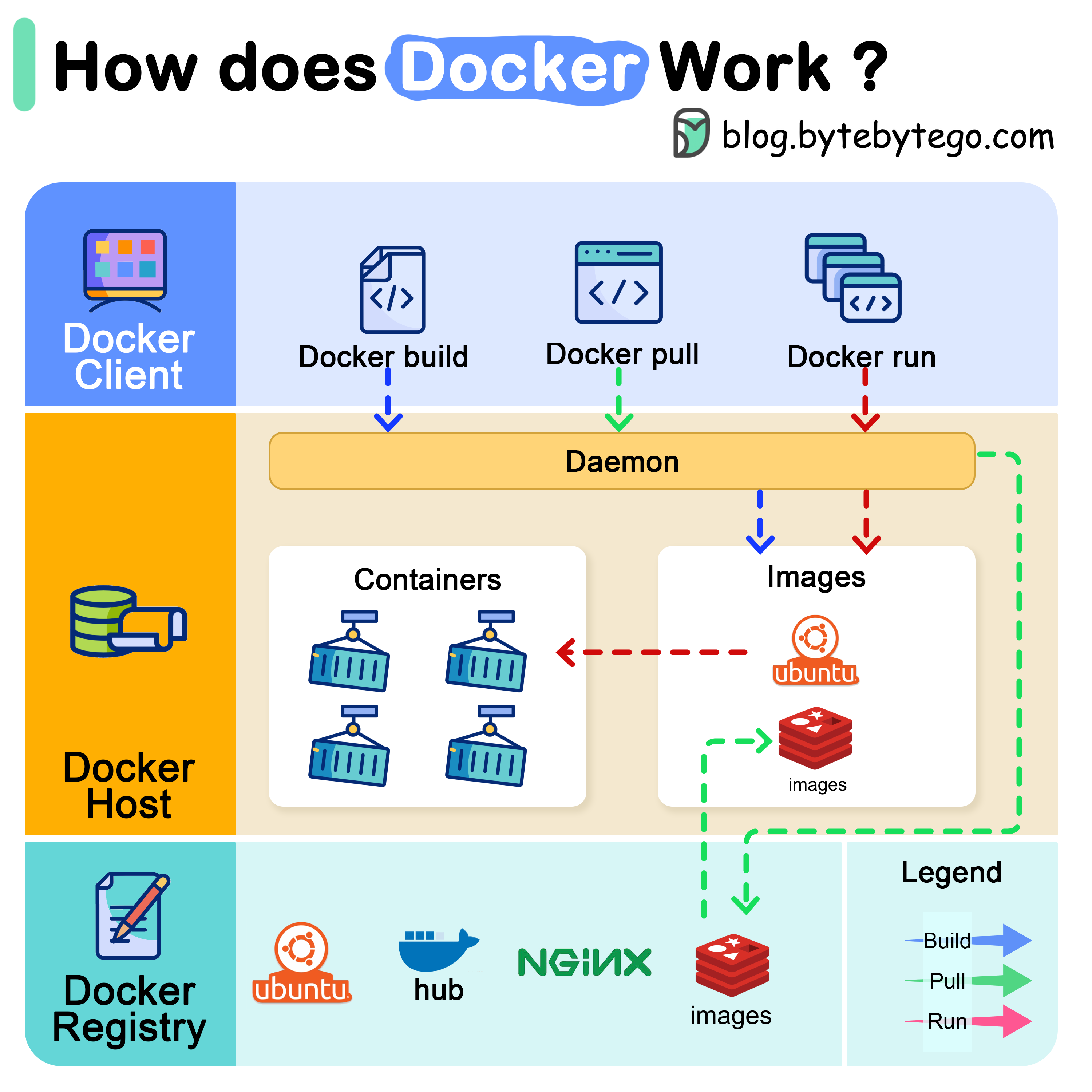
Watch the network traffic: Run Wireshark or tcpdump for a few weeks to see what your developers are actually pulling. Don't guess - you'll miss something important and get a nasty surprise later.
Watch your network traffic - DNS requests to registries, HTTPS on 443 and 5000 usually, though some weird setups use other ports. Check your CI/CD logs for docker pulls and auth attempts.
Survey your dev teams about what registries they're actually using: Ask about the obvious stuff (primary registries, CI/CD dependencies) but also the weird shit they won't think to mention:
- That one Harbor instance someone's running on their laptop
- Vendor registries they only use for demos
- The "emergency" registry that's never been tested
- Personal registries for side projects that somehow made it into production
Infrastructure audit: Review existing infrastructure documentation to identify:
- Harbor, Artifactory, or Nexus deployments
- Cloud registry configurations (AWS ECR, Azure ACR, Google GCR)
- Registry mirrors or proxy configurations
- Custom registry setups for compliance or air-gapped environments
Don't forget the weird stuff: Check for Red Hat's registry, Microsoft's registry, GitHub Container Registry, and Quay.io. These show up in base images more often than you think.
Figure out what breaks when you block stuff
Find the critical shit first: You need to know what'll catch fire when you start blocking registries:
- Production deployment pipelines: Your CI/CD probably pulls from 5 registries you forgot about
- Developer workflows: That one team definitely has some weird custom setup
- Testing environments: QA is pulling test data from some registry in Singapore
- Emergency procedures: Your incident response playbook assumes Docker Hub works
Map the dependencies before you break them: For each registry you find:
- Which teams will scream when it stops working
- How often they actually use it (vs. "we might need it someday")
- What backup plan exists (spoiler: there probably isn't one)
- How much money you lose per hour if it goes down
Had this one company where some dev was running Harbor on his laptop for their fraud detection stuff. Nobody knew until his laptop died and suddenly production couldn't deploy. Took them like 2 days to figure out what the hell was happening - turned out half their microservices were depending on this random laptop registry for base images.
Check your compliance requirements: Don't forget the boring but important stuff:
- What registries your security team actually approves of
- Whether you're allowed to pull containers from random places
- Geographic restrictions (some countries really don't like certain cloud providers)
- Whether your auditors will care about this (they will)
Figure out if this is worth the pain
Docker Business costs real money: $24/user/month adds up fast:
- 500 developers = $144k/year (your CFO will notice this)
- That includes SSO, SCIM, and other enterprise features you might actually use
- Compare it to what you're spending on security incidents and compliance gaps
Calculate your current security mess: This is where the business case gets interesting:
- What did your last supply chain incident cost? (Usually more than you want to admit)
- How much do you spend on compliance auditors finding container security gaps?
- What's your current incident response budget for "some developer pulled a bitcoin miner"?
Had a client where their security team was constantly chasing down crypto mining alerts. Some dev would pull some random base image from god knows where and boom - bitcoin miner running in prod. RAM cut way down on that crap, though they still find weird shit sometimes.
Reality check: Don't underestimate how much work this actually is. You're looking at weeks (not counting the inevitable meetings about meetings). Your devs need training and they'll definitely complain about it. Someone's gotta babysit this thing ongoing - maybe a few hours a week.
Make sure your infrastructure won't explode
Check your Docker Desktop versions: Half your developers are probably running ancient versions:
- Get everyone on Docker Desktop 4.41+ if you're on macOS (they fixed some config profile bypass issues in April 2025)
- Windows containers need WSL2 working properly (good luck with that)
- VDI environments are a nightmare - test early and test often
Your network is probably fucked: Enterprise networks hate everything:
- DNS needs to work for policy enforcement (shocking, I know)
- Firewalls will block Docker Desktop communication because of course they will
- Corporate proxies will break authentication in creative ways
One company I worked with had their corporate proxy rewriting Docker authentication headers. Took us 3 weeks to figure out why nobody could sign in to Docker Desktop. IT swore the proxy wasn't touching anything. It was touching everything.
Identity management integration prep: Get ready for enforced sign-in:
- SSO setup will take longer than you think
- SCIM provisioning breaks when people change teams
- User migration will find all the edge cases in your identity system
Clean up your registry mess first
Kill the redundant registries: You probably have way too many:
- Move team-specific registries to something centralized (good luck convincing them)
- Pick one cloud provider registry and stick with it
- Shut down that Harbor instance that nobody remembers why it exists
Plan your allowlist before you need it: Start small or you'll regret it:
- Begin with 20-30 essential registries (resist the urge to add "just in case" entries)
- Document all the weird redirect domains (AWS ECR requires multiple domains because AWS loves to complicate things)
- Have an emergency addition process ready - you'll need it at 2am
Registry mirrors can save your ass: Consider setting these up:
- Docker Hub mirrors for when Docker Hub inevitably goes down
- Internal mirrors of critical external registries
- Proxy registries that handle the redirect domain bullshit for you
This discovery phase typically takes 2-4 weeks if you do it right, but it'll save you months of pain later. Companies that skip this planning spend 2-3x longer on deployment and get way more angry tickets from developers. Don't be those companies.
Now that you know what you're dealing with, let's talk about the questions you'll definitely get asked...