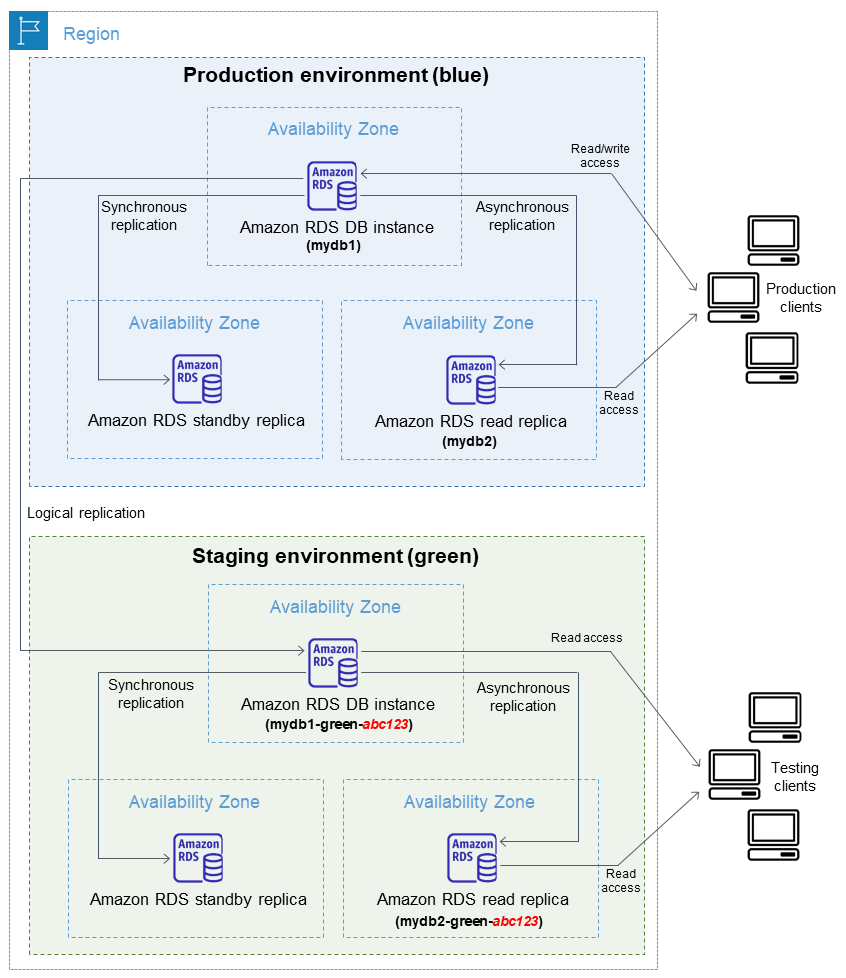

Blue/green deployments copy your production database to a separate environment where you can safely test upgrades. The "blue" environment is what's currently serving traffic, and the "green" environment is where you break things during testing so production keeps running.
It's like having a backup server where you can break shit without taking down production. When you're done testing and everything actually works, you just flip a switch and make the backup your new primary.
AWS launched this in November 2022 because too many DBAs were having panic attacks during major version upgrades. AWS's way of saying "stop doing maintenance windows at 3am and praying nothing breaks."
How This Actually Works
AWS copies your entire database setup - Multi-AZ, read replicas, storage config, monitoring, everything. The replication mechanism depends on your database engine, but the important part is it keeps your green environment in sync with production.
Here's what happens when you create one:
- AWS takes a snapshot and restores it as your green environment
- Sets up replication from blue to green (this can take forever on large databases)
- Green environment is read-only by default (don't fuck with this setting unless you know what you're doing)
- All your monitoring and backup configs get copied too
Reality check: The green environment takes time to warm up. Don't expect it to perform like production immediately - storage needs time to cache frequently accessed data.
Why You'd Actually Use This Thing
Most people use this for PostgreSQL 12 → 15 upgrades, bumping instance sizes, or parameter changes that might break everything.
What you actually get (when it works):
- ~1 minute downtime (assuming your app handles connection drops gracefully)
- Test your changes without touching production (revolutionary concept, I know)
- Easy rollback - the old environment sits there with "-old1" appended to the name
- Same endpoints - no app config changes needed
What they don't tell you: The "under one minute" switchover is bullshit if you have high write workloads. Replication lag will make you wait, and wait, and wait.
Supported Database Engines
Works with MySQL 5.7+, MariaDB 10.2+, PostgreSQL (added October 2023), and Aurora variants. Oracle and SQL Server? Still waiting after 3 years.
What's missing: Oracle and SQL Server support. AWS has been "working on it" for years. If you're stuck with these engines, you're back to maintenance windows at 3am and prayer-driven deployments.
What You Need to Know About the Architecture
The replication mechanism depends on your database engine. MySQL and MariaDB use physical replication for block-level sync, while PostgreSQL might use physical or logical replication based on what you're upgrading.
Read-only enforcement saves your ass
The green environment stays read-only by default, preventing you from accidentally writing test data and breaking replication. Don't disable this unless you're testing specific write scenarios - learned this the hard way when a junior dev ran a migration script on green and broke replication for half the afternoon. Cost us 3 hours of debugging and a very awkward conversation with management.
Monitoring is critical
Watch CloudWatch metrics obsessively during deployments. ReplicaLag is your most important metric - anything over 30 seconds means trouble. Set up alarms for replication lag or you'll be sitting there refreshing the console like an idiot wondering why switchover won't activate.
Common gotchas that will ruin your day:
- Read replica issues when cross-region replicas exist - they don't get migrated automatically
- Parameter group secrets causing provisioning to hang for hours (error:
ParameterNotFoundon custom parameter groups) - Large database deployments taking hours instead of minutes to sync - 500GB+ databases are painful
- Connection pooling failures during switchover causing app outages - pgbouncer throws
server closed the connection unexpectedlyfor 30+ seconds

When you're ready to automate this:
- Terraform modules for Infrastructure as Code - because clicking buttons gets old fast

