Fargate is containers without the server babysitting. No more middle-of-the-night pages about disk space on your cluster nodes, no more debugging why your autoscaling group decided to terminate the wrong instance during a traffic spike.

The Real Problem Fargate Solves
Here's what actually happens when you deploy this thing (learned this from way too many weekend debugging marathons):
- Your EC2 instances run out of disk space from Docker image layers
- Cluster autoscaling fails mysteriously and you spend 3 weekends debugging it
- Security patches require coordinating maintenance windows across 20+ nodes
- Resource allocation becomes a nightmare when pods with different resource requirements compete
I learned this the hard way running ECS clusters on EC2 for 2 years. We had a microservice that would randomly OOM kill other containers because of poor resource isolation. Fargate fixes this by giving each task its own isolated compute slice.
How Fargate Actually Works (Not Marketing BS)
So what's the magic behind Fargate fixing all these cluster headaches? Fargate runs your containers on shared AWS infrastructure, but you get dedicated CPU/memory allocation. It's basically a really good virtualization layer that you never have to think about.

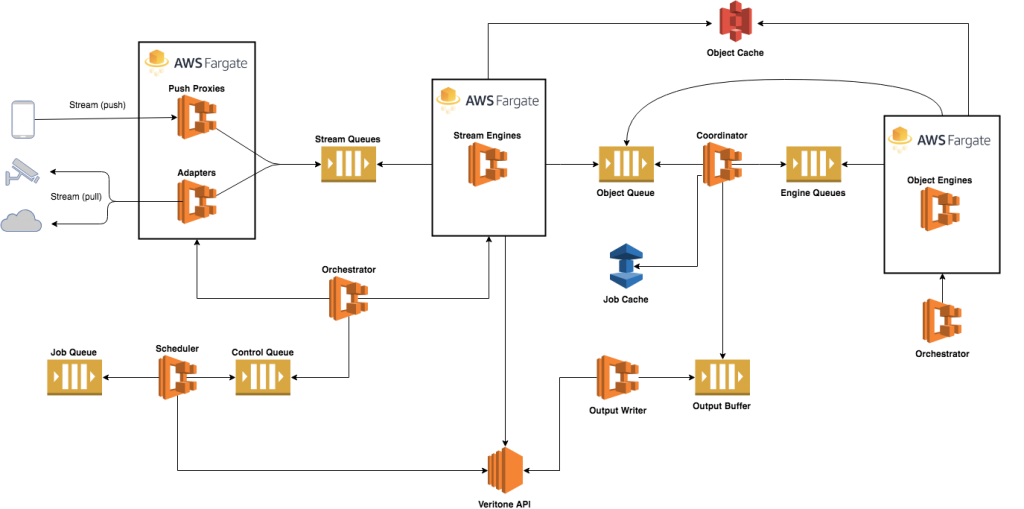
This architecture diagram shows a typical production Fargate setup: API Gateway → Network Load Balancer → Fargate tasks → RDS. Each layer scales independently, which is where Fargate shines compared to traditional VM-based deployments.
What you specify:
- CPU (0.25 to 16 vCPU)
- Memory (512MB to 120GB)
- Your container image
- Networking config
What AWS handles:
- Server provisioning and patching
- Capacity management
- Security updates to the host OS
- Load balancing across availability zones
The catch? It costs 2-3x more than EC2 for steady workloads, but you'll sleep better at night. AWS pricing calculator helps estimate costs, but hidden networking fees always surprise you.
The Gotchas Nobody Tells You About
That's the marketing pitch. Here's where it actually bites you:
Networking will bite you: Every Fargate task eats a subnet IP address. We hit subnet exhaustion during a traffic spike because each autoscaled task needed its own ENI. Plan your subnets accordingly and consider VPC endpoint costs for ECR access.
Cold starts are real: 30-60 seconds is AWS marketing speak. Budget 2+ minutes for production images over 1GB. Our React app was taking forever to start - like 5+ minutes, which was insane. Image was massive, something like 2.1GB I think? After we figured out multi-stage builds and Alpine Linux, got it down to around 400MB and starts dropped to maybe 45 seconds.
Platform version migrations: AWS will migrate your tasks to new platform versions without warning, sometimes breaking your deployment scripts. This happened to us with the 1.3.0 to 1.4.0 migration - our health check scripts failed because the task metadata endpoint changed.
When Fargate Will Bankrupt You (And When It Won't)
Let's talk cost, because it's fucking expensive. I mentioned the 2-3x premium, but when does that math actually work out?
When Fargate makes financial sense:
- Batch jobs that run sporadically
- Dev/staging environments (spin up, test, tear down)
- Apps with spiky traffic you can't predict
When Fargate will financially destroy you:
- ML training that runs 24/7 (just use EC2 with GPUs)
- Data processing that never stops
- Anything needing GPUs (Fargate barely supports them and charges extra)
We switched our API from t3.medium instances ($24/month) to Fargate ($58/month for equivalent resources) and consider it worth every penny. No more weekend maintenance, no more capacity planning, no more debugging ECS cluster autoscaling.
Real-World Use Cases Where Fargate Shines
Microservices APIs: Perfect for REST APIs that need to scale independently. Each service gets its own resource allocation and scaling policy.
Background job processing: Fargate Spot is 70% cheaper and handles job queue processing beautifully. We use it for image resizing, report generation, and data imports.
CI/CD build agents: Spin up fresh build environments on demand. No more managing Jenkins slaves or dealing with build environment pollution.
Development environments: Developers can spin up isolated environments without waiting for infrastructure team approval using AWS Copilot.
How Fargate Plays with Other AWS Services
Fargate plays well with other AWS services, but there are gotchas:
- Load balancers: Must use 'ip' target type, not 'instance'
- Service discovery: Works with AWS Cloud Map, but setup is more complex than it needs to be
- Monitoring: CloudWatch Container Insights is enabled by default (and costs extra)
- Secrets management: Built-in integration with Secrets Manager and Parameter Store
The best part? No more capacity planning. Traffic spike hits during dinner? Fargate scales up automatically. Traffic drops? You stop paying for idle capacity immediately.
But here's where the marketing bullshit ends and reality begins. Let me show you what Fargate actually looks like when the rubber meets the road.