I've spent way too many 3am debugging sessions figuring out why Docker Swarm's networking shits the bed. Here's what actually happens when everything goes wrong.
Docker's Service Discovery Will Fuck You Over
Docker Swarm has like 5 different networking layers that all have to work perfectly or nothing works at all. When one breaks, good luck figuring out which one. The official docs sure as hell won't prepare you for debugging this mess.
DNS is the First Thing to Break
Docker Swarm uses built-in DNS that works until it doesn't. Your containers hit up Docker's embedded DNS server at 127.0.0.11 to find other services.
Here's how it's supposed to work:
- Service
webgets a Virtual IP that magically load balances tasks.webreturns actual container IPs (when it feels like it)- Every container trusts Docker's DNS server completely
The thing that'll bite you: DNS happens inside the Docker daemon, not in /etc/hosts. When DNS breaks, it's usually because nodes can't talk to each other, or Docker's DNS server has gone completely insane with stale data.
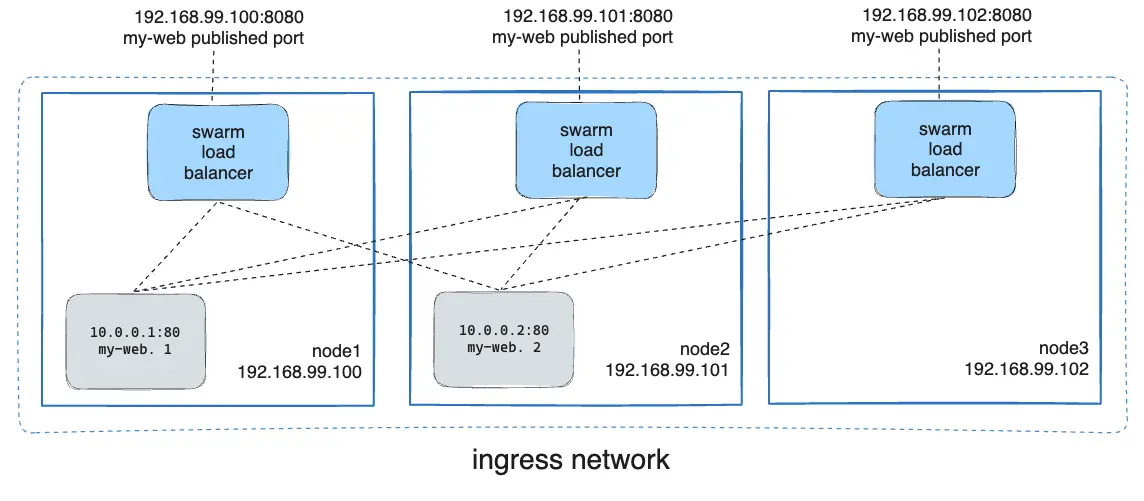
Routing Mesh: The Magic That's Not Actually Magic
The routing mesh is supposed to let you hit any node and magically reach your service. Published ports like --publish 8080:80 create this ingress network that should route traffic correctly.
What's actually happening under the hood:
- IPVS load balancing: Linux kernel doing the heavy lifting
- VXLAN tunneling: UDP port 4789 carries your traffic between nodes
- iptables rules: A massive pile of firewall rules that nobody understands
The Ways This Shit Will Break in Production
MTU: The Problem That Ruins Weekends
Here's the thing that took me 6 hours to figure out: MTU mismatches are the devil. VXLAN adds 50 bytes of overhead to every packet, so if your network MTU is 1500, you're fucked. There's an RFC that explains why this overhead exists, but that doesn't help when your production is down.
You'll see this bullshit:
- Ping works fine (small packets)
- HTTP requests just timeout (larger packets)
- File uploads randomly fail
- Database queries work until they don't
I learned this the hard way during Black Friday 2022. Site went down intermittently - small API calls worked fine, larger ones just died with "connection reset by peer". Spent 3 hours checking logs, database, load balancer. Basically everything except the obvious thing. Turned out network team had changed switch MTU from 9000 to 1500 the week before without updating Docker configs. Who does that right before Black Friday? Our revenue was dropping $2000/minute while I traced packets. Anyway, that's when I learned to check MTU first - could've saved 3 hours and my sanity.
DNS Goes Insane Under Load
Docker's DNS server loses its mind when shit gets busy. I've seen tasks.<service> return complete garbage:
- Empty results when containers are definitely running
- Only half your replicas show up in DNS
- IPs of containers that died last Tuesday
The symptoms are fun:
- Random "service not found" errors that make no sense
- Load balancer happily sending traffic to dead containers
- Half your app works, half doesn't, and you can't figure out why
Real example: We had a PostgreSQL connection pool in our Docker 20.10.8 setup using tasks.database to find all replicas. Under load, DNS would return stale IPs like 10.0.1.43 from containers that had been killed and rescheduled 6 hours earlier. 30% of connections failed with "ECONNREFUSED 10.0.1.43:5432" because they were trying to connect to ghost containers. Took me 2 fucking days to realize Docker's DNS was just lying to us. Turns out this is a known issue since Docker 19.03 - mentioned in one GitHub issue from 2020 that has 47 thumbs up and zero official response.
VXLAN Tunnels: When Nodes Can't Talk
VXLAN tunnel failures are my favorite because the symptoms are completely counterintuitive:
- Services work fine on the same node
- Cross-node communication is fucked
docker service psshows everything is healthy- You can ping between nodes just fine
Common causes that'll ruin your day:
- Firewall blocking UDP port 4789 (of course)
- Network gear that doesn't understand VXLAN properly (especially older switches)
- VMware NSX using the same damn port as Docker
- Cloud security groups configured by someone who doesn't understand networking
- MTU mismatches between host and overlay networks causing packet fragmentation
Certificates: The Silent Killer
Docker Swarm uses mutual TLS for everything. When certificates expire or get corrupted, service discovery just dies. Certificate management becomes critical for large-scale deployments:
- Services can't resolve across nodes (but local stuff works fine)
- Manager nodes randomly show "Unavailable"
- New services won't deploy and you get useless error messages
- DNS queries timeout and you blame the network
Load Balancer Goes Crazy
Docker's IPVS load balancer is great until it isn't. It'll happily keep routing traffic to containers that don't exist anymore:
- Some requests work, others randomly timeout
- Scaling events make everything slower
- Services look healthy but error rates spike
- IPVS backend state corruption causes persistent routing failures
When Everything Goes Wrong at Once
The real fun starts when multiple things break simultaneously. I've seen these combinations destroy entire weekends:
- MTU + DNS: MTU issues drop large DNS responses, so you only get partial service discovery
- Certificates + VXLAN: Expired certs prevent tunnels from re-establishing after network blips
- DNS + Load balancer: Stale DNS feeds bad IPs to the load balancer
- High availability + Scale: HA setups amplify networking failures
- Security + Performance: Security practices often conflict with network debugging needs
Resource Exhaustion: The Hidden Killer
Docker daemon resource usage will fuck you sideways:
- Memory pressure: Docker daemon eating all RAM makes DNS slow as molasses
- File descriptor limits: Hit the limit and new connections just die
- CPU throttling: High load means DNS timeouts and health checks fail
Here's what nobody tells you: monitor dockerd itself, not just your pretty containers. I've seen a daemon eating 15GB out of 16GB RAM cause intermittent service discovery failures that looked like application bugs. The error logs? "context deadline exceeded" - thanks for nothing. Spent 3 days debugging overlay networks and DNS configs until I noticed dockerd was swapping like a Windows 95 machine. DNS timeout issues are probably resource starvation more often than network fuckery, but Docker's error messages sure don't help you figure that out.
Why Dev Environment Tests Are Useless
Your local Docker setup won't prepare you for production reality:
- Geographic distribution: Cross-region latency makes VXLAN tunnels unstable
- Enterprise networking: Corporate firewalls and SDN that hate VXLAN
- Scale: DNS performance turns to shit with hundreds of services
- Load patterns: Burst traffic that destroys connection pools
- VIP network complexity: Service discovery behaves differently under load
- DNS resolver conflicts: Embedded DNS server issues with hundreds of errors per second in production
Docker's error messages are worse than useless: "Connection refused" could be MTU, DNS staleness, or certificate bullshit. "Service not found" might be DNS cache poisoning, and "Request timeout" could be anything from VXLAN tunnel failure to dockerd memory pressure.
Bottom line: Docker Swarm networking problems masquerade as application bugs when they're actually infrastructure failures. You can't debug this mess without understanding the entire fucking stack - from VXLAN tunnels to embedded DNS to IPVS load balancing to certificate rotation.