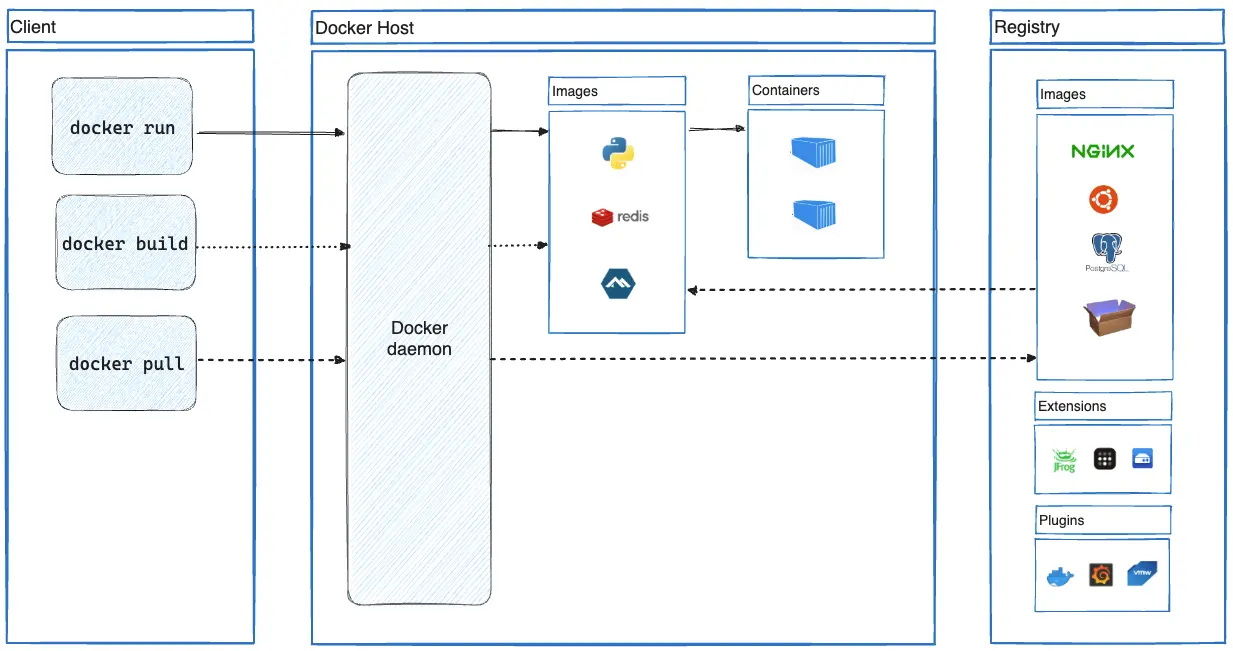
Docker: Simple Until It Isn't (Spoiler: It Never Was Simple)
So your MCP server runs like a dream in Docker on your laptop. Then you deploy that same container to production and watch it balloon from 500MB to 2GB because nobody told you multi-stage builds were a thing. The startup time goes from 2 seconds to 45 seconds because now you're pulling from Docker Hub over a terrible network connection. Don't get me started on the day we discovered our "lightweight" Alpine image was missing SSL certificates and all external API calls were just... failing. Silently. For 6 hours.
Docker is supposed to solve the "works on my machine" problem, but in reality it just moves the problem to "works in my Docker, fails in your Docker." Here's the stuff that'll bite you and how I figured out to fix it:
## Dockerfile that actually survives production (after 3 weeks of pain)
FROM python:3.11-slim as base
## Security scans will find every possible CVE, so create non-root user first
## took me 3 tries to get the UID/GID combo that works everywhere
RUN groupadd --gid 1000 mcpuser && \
useradd --uid 1000 --gid mcpuser --shell /bin/bash --create-home mcpuser
## CVE scanners will flag you if you don't update packages
## That rm command? Saves 100MB and makes security happy
RUN apt-get update && apt-get upgrade -y && \
apt-get install -y --no-install-recommends \
ca-certificates curl && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
## Cache layer optimization - requirements.txt changes less than code
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
## Set ownership BEFORE switching users or you'll get permission denied errors
COPY --chown=mcpuser:mcpuser . .
USER mcpuser
## Health check that doesn't immediately fail in k8s
## Python takes forever to start up but Kubernetes has zero patience
HEALTHCHECK --interval=30s --timeout=10s --start-period=60s --retries=3 \
CMD curl -f http://localhost:8000/health || exit 1
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
Your security team will scan every image with Docker Scout and somehow find CVEs in packages you've never heard of. Distroless images sound amazing until you're debugging at 3am and can't even run ls inside the container. Alpine Linux breaks Python packages in ways that make no sense. And seriously, don't use latest tags - that's how you accidentally deploy last month's code to production.
Welcome to Kubernetes Hell (Population: You and Your Regrets)
So Docker Compose worked fine until your startup grew past "three guys in a garage" and suddenly you need actual orchestration. Kubernetes promises to solve your container management problems, and it does - by replacing them with YAML configuration problems that are somehow worse. It's like trading a headache for a full-blown migraine that comes with a side of existential dread. But here we are, because it's the only game in town for running distributed stuff that doesn't fall over when someone sneezes.
## deployment.yaml - This YAML made me want to quit programming
apiVersion: apps/v1
kind: Deployment
metadata:
name: mcp-server
namespace: ai-platform
labels:
app: mcp-server
tier: production # Bold claim for something that crashes weekly
spec:
replicas: 5 # We started with 2, went to 50, crashed, settled around here
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # Add new pods BEFORE killing old ones
maxUnavailable: 0 # Never reduce capacity during deploy
selector:
matchLabels:
app: mcp-server
template:
metadata:
labels:
app: mcp-server
version: v1.2.3 # Semantic versioning until you need v1.2.3.1-hotfix-shit-is-broken
annotations:
prometheus.io/scrape: "true" # So you can watch it die in real time
prometheus.io/port: "8000"
prometheus.io/path: "/metrics"
spec:
serviceAccountName: mcp-server-sa
securityContext:
runAsNonRoot: true # Security team requirement after the last breach
runAsUser: 1000
fsGroup: 1000
containers:
- name: mcp-server
image: your-registry.com/mcp-server:v1.2.3 # Use actual SHA256 in production, and test on Docker 20.10.24+ because earlier versions break with certain base images
ports:
- containerPort: 8000
name: http
env:
- name: ENVIRONMENT
value: "production"
- name: LOG_LEVEL
value: "INFO" # DEBUG when things break, which is always
envFrom:
- secretRef:
name: mcp-secrets # Where passwords go to die
- configMapRef:
name: mcp-config
resources:
requests:
memory: "256Mi" # What it asks for
cpu: "250m"
limits:
memory: "1Gi" # What it actually needs before the OOM killer shows up
cpu: "1000m" # CPU throttling will slow everything down
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 45 # Python is slow, k8s is impatient
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3 # 3 strikes and you're restarted
readinessProbe:
httpGet:
path: /ready # Different from /health - learn the difference
port: 8000
initialDelaySeconds: 15
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 3
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true # Immutable containers or GTFO
capabilities:
drop:
- ALL # Drop all privileges, trust no process
volumeMounts:
- name: tmp
mountPath: /tmp # /tmp needs to be writable because everything breaks otherwise
- name: cache
mountPath: /app/cache
volumes:
- name: tmp
emptyDir: {}
- name: cache
emptyDir:
sizeLimit: 1Gi # Prevent cache from eating all disk space
nodeSelector:
kubernetes.io/os: linux # Because someone will try to schedule this on Windows
node-type: compute
tolerations:
- key: "ai-workload" # Custom taints because AI workloads are special snowflakes
operator: "Equal"
value: "true"
effect: "NoSchedule"
Resource Limits Are Where Dreams Go to Die: Resource requests and limits sound simple but they'll drive you insane. Set memory too low and your pods get OOM killed during lunch break. Set them too high and your AWS bill looks like a phone number. There's no magic formula - you just run it in prod, watch it break, adjust, and repeat until you find something that works most of the time.
Auto-Scaling: Because Manual Scaling is for Masochists
Horizontal Pod Autoscaler (HPA): HPA promises to scale your pods automatically based on demand. In practice, it scales too late during traffic spikes and too aggressively during normal fluctuations, creating a sawtooth pattern that will haunt your monitoring dashboards. But it's still better than being paged at 3am to manually scale pods because your MCP servers are dying under load.
## mcp-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: mcp-server-hpa
namespace: ai-platform
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mcp-server
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: mcp_requests_per_second
target:
type: AverageValue
averageValue: "100"
behavior:
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 60
selectPolicy: Max
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
selectPolicy: Min
Vertical Pod Autoscaler (VPA): Automatically adjust resource requests based on actual usage patterns. VPA helps optimize resource allocation over time.
Cluster Autoscaler: Scale the underlying infrastructure when pod demand exceeds node capacity. Cluster Autoscaler integrates with cloud providers to add/remove nodes automatically.
Service Mesh for Enterprise Networking
Why Service Mesh for MCP: Multi-agent architectures create complex networking requirements. Istio or Linkerd provide traffic management, security, and observability between MCP components.
## istio-mcp-configuration.yaml
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: mcp-server-vs
namespace: ai-platform
spec:
hosts:
- mcp-api.yourcompany.com
gateways:
- mcp-gateway
http:
- match:
- uri:
prefix: /api/v1/
route:
- destination:
host: mcp-server-service
port:
number: 80
fault:
delay:
percentage:
value: 0.1
fixedDelay: 5s
retries:
attempts: 3
perTryTimeout: 10s
timeout: 30s
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: mcp-server-dr
namespace: ai-platform
spec:
host: mcp-server-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http1MaxPendingRequests: 50
maxRequestsPerConnection: 10
circuitBreaker:
consecutiveErrors: 5
interval: 30s
baseEjectionTime: 30s
maxEjectionPercent: 50
loadBalancer:
simple: LEAST_CONN
mTLS Configuration: Service mesh provides automatic mutual TLS between MCP components without application changes. This ensures encrypted communication across the entire system.
Traffic Management: Implement canary deployments, circuit breakers, and retry policies declaratively through service mesh configuration.
Production Health Checks and Monitoring
Comprehensive Health Endpoints: Kubernetes needs multiple health check endpoints to make informed decisions about pod lifecycle management.
## health_checks.py
from fastapi import FastAPI, HTTPException, status
import asyncio
import time
import httpx
from typing import Dict, Any
app = FastAPI()
class HealthChecker:
def __init__(self):
self.start_time = time.time()
self.dependency_cache = {}
self.cache_ttl = 30 # seconds
async def check_database(self) -> Dict[str, Any]:
"""Check database connectivity and performance"""
try:
start = time.time()
# Simple query to test connectivity
await self.db.execute("SELECT 1")
latency = (time.time() - start) * 1000
return {
"status": "healthy",
"latency_ms": round(latency, 2),
"type": "database"
}
except Exception as e:
return {
"status": "unhealthy",
"error": str(e),
"type": "database"
}
async def check_external_apis(self) -> Dict[str, Any]:
"""Check external API dependencies"""
dependencies = {}
apis_to_check = [
("auth_service", "https://auth.internal.com/health"),
("data_service", "https://data.internal.com/health")
]
for name, url in apis_to_check:
try:
async with httpx.AsyncClient(timeout=5.0) as client:
response = await client.get(url)
dependencies[name] = {
"status": "healthy" if response.status_code == 200 else "degraded",
"response_time": response.elapsed.total_seconds() * 1000
}
except Exception as e:
dependencies[name] = {
"status": "unhealthy",
"error": str(e)
}
return dependencies
@app.get("/health")
async def health_check():
"""Kubernetes liveness probe - basic server health"""
uptime = time.time() - health_checker.start_time
try:
# Quick health checks only
db_status = await health_checker.check_database()
if db_status["status"] != "healthy":
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail="Database unhealthy"
)
return {
"status": "healthy",
"uptime_seconds": round(uptime, 2),
"timestamp": time.time(),
"version": os.getenv("APP_VERSION", "unknown")
}
except Exception as e:
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail=f"Health check failed: {str(e)}"
)
@app.get("/ready")
async def readiness_check():
"""Kubernetes readiness probe - ready to serve traffic"""
try:
# Comprehensive readiness checks
checks = await asyncio.gather(
health_checker.check_database(),
health_checker.check_external_apis(),
return_exceptions=True
)
all_healthy = all(
isinstance(check, dict) and check.get("status") == "healthy"
for check in checks
)
if not all_healthy:
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail="Not ready to serve traffic"
)
return {
"status": "ready",
"checks": checks
}
except Exception as e:
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail=f"Readiness check failed: {str(e)}"
)
@app.get("/metrics")
async def metrics():
"""Prometheus metrics endpoint"""
# Custom metrics for MCP server monitoring
return {
"mcp_requests_total": request_counter.get_value(),
"mcp_request_duration_seconds": request_duration.get_value(),
"mcp_active_connections": active_connections.get_value(),
"mcp_errors_total": error_counter.get_value()
}
Health Check Best Practices:
- Liveness probes should be lightweight - they determine if Kubernetes should restart the pod
- Readiness probes can be more comprehensive - they determine if the pod should receive traffic
- Startup probes handle slow-starting applications by delaying other probes


Database and Storage Considerations
Persistent Storage: MCP servers often need persistent storage for caching, session data, and application state. Kubernetes persistent volumes provide storage abstraction across cloud providers.
## mcp-storage.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mcp-data-pvc
namespace: ai-platform
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast-ssd
resources:
requests:
storage: 100Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mcp-cache-pvc
namespace: ai-platform
spec:
accessModes:
- ReadWriteMany
storageClassName: fast-ssd
resources:
requests:
storage: 50Gi
Database Connectivity: Production MCP systems need connection pooling, proper authentication, and connection lifecycle management.
## database_config.py
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import sessionmaker
from sqlalchemy.pool import QueuePool
import os
class DatabaseConfig:
def __init__(self):
self.database_url = os.getenv("DATABASE_URL")
self.engine = create_async_engine(
self.database_url,
# Connection pool configuration
poolclass=QueuePool,
pool_size=20, # Base connections
max_overflow=30, # Additional connections under load
pool_pre_ping=True, # Validate connections before use
pool_recycle=3600, # Recycle connections after 1 hour
# Performance optimization
echo=False, # Disable SQL logging in production
future=True,
# Security
connect_args={
"command_timeout": 60,
"server_settings": {
"application_name": "mcp-server",
"jit": "off" # Disable JIT for predictable performance
}
}
)
self.SessionLocal = sessionmaker(
self.engine,
class_=AsyncSession,
expire_on_commit=False
)
async def get_session(self):
async with self.SessionLocal() as session:
try:
yield session
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()
Caching Strategy: Redis clusters or Memcached for distributed caching across MCP server instances. Implement cache invalidation strategies to maintain data consistency.
Security Architecture for Enterprise MCP
Pod Security Standards: Kubernetes Pod Security Standards enforce security policies across the cluster.
## pod-security-policy.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ai-platform
labels:
pod-security.kubernetes.io/enforce: restricted
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/warn: restricted
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: mcp-server-sa
namespace: ai-platform
automountServiceAccountToken: false
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: ai-platform
name: mcp-server-role
rules:
- apiGroups: [""]
resources: ["configmaps", "secrets"]
verbs: ["get", "list"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: mcp-server-rolebinding
namespace: ai-platform
subjects:
- kind: ServiceAccount
name: mcp-server-sa
namespace: ai-platform
roleRef:
kind: Role
name: mcp-server-role
apiGroup: rbac.authorization.k8s.io
Network Policies: Implement Kubernetes Network Policies to control traffic between MCP components and external systems.
Image Security: Use container image scanning, signed images, and private registries. Implement admission controllers to prevent deployment of vulnerable images.
The infrastructure foundation determines whether your MCP system scales gracefully or fails catastrophically under load. Proper container orchestration, health monitoring, and security configuration are prerequisites for enterprise deployment - not nice-to-have features added later.
But getting the containers and orchestration right is just the foundation. The moment you mention "enterprise deployment" to your security team, you'll discover a whole new dimension of complexity: authentication that actually works with your existing identity systems, secrets management that doesn't make auditors cry, and compliance frameworks that turn simple deployments into month-long projects. Let's dive into the security architecture that separates toy projects from enterprise-ready systems.