DeepSeek Coder is an open-source family of code models that doesn't try to sell you on "revolutionary AI-powered solutions." It's a 236B parameter monster that beats GPT-4 Turbo at coding - and I know this because I've spent 6 months using both to fix shitty legacy code at 2am.
The Technical Reality Behind the Hype
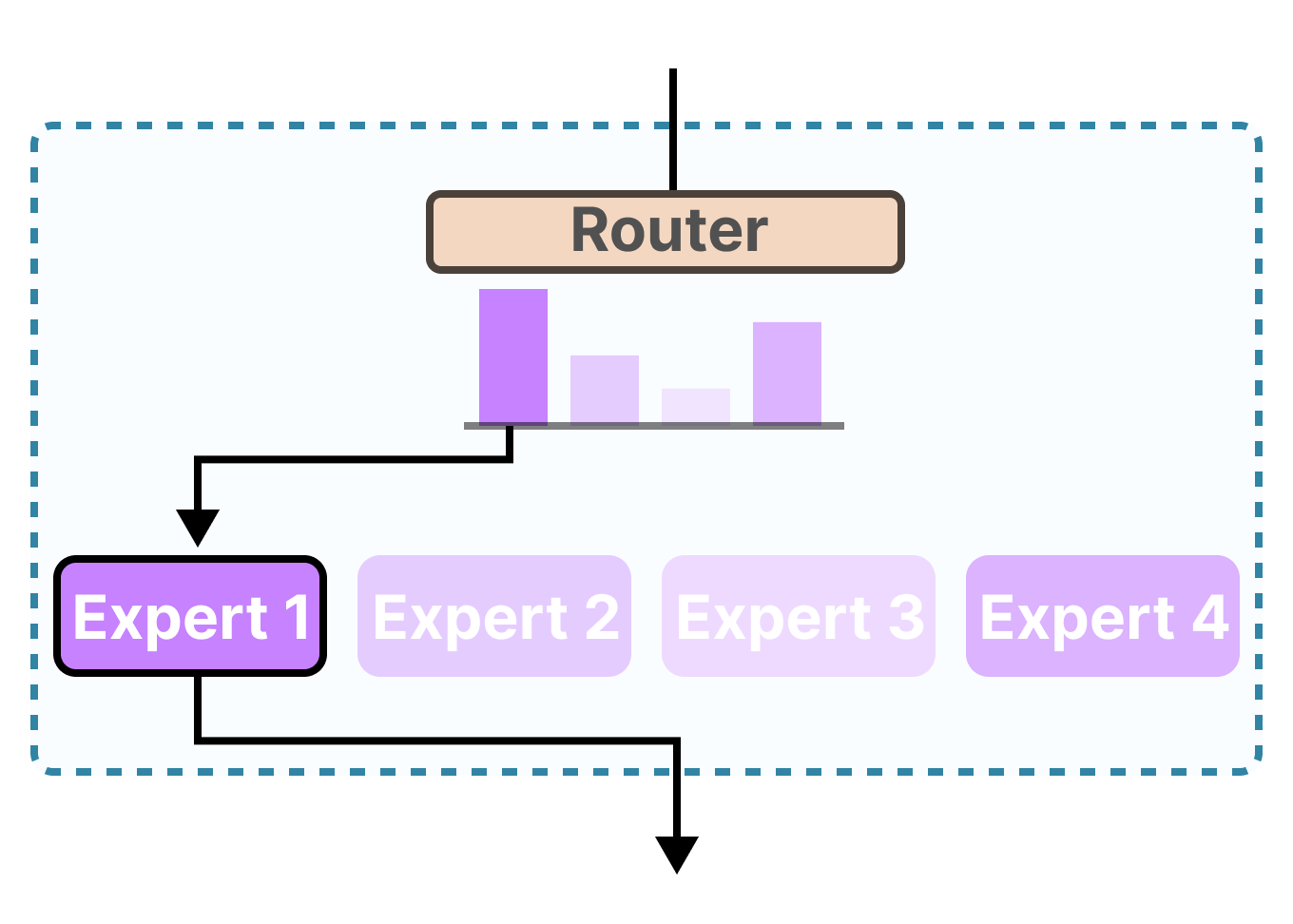
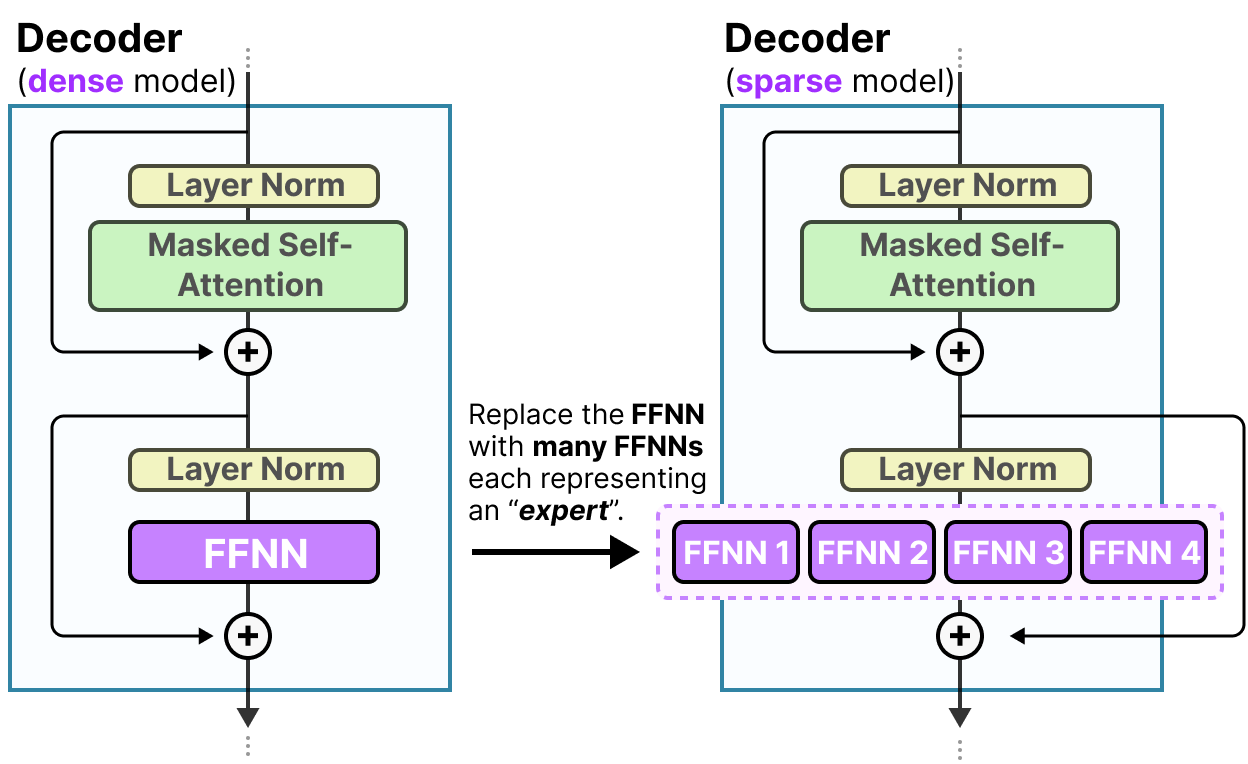
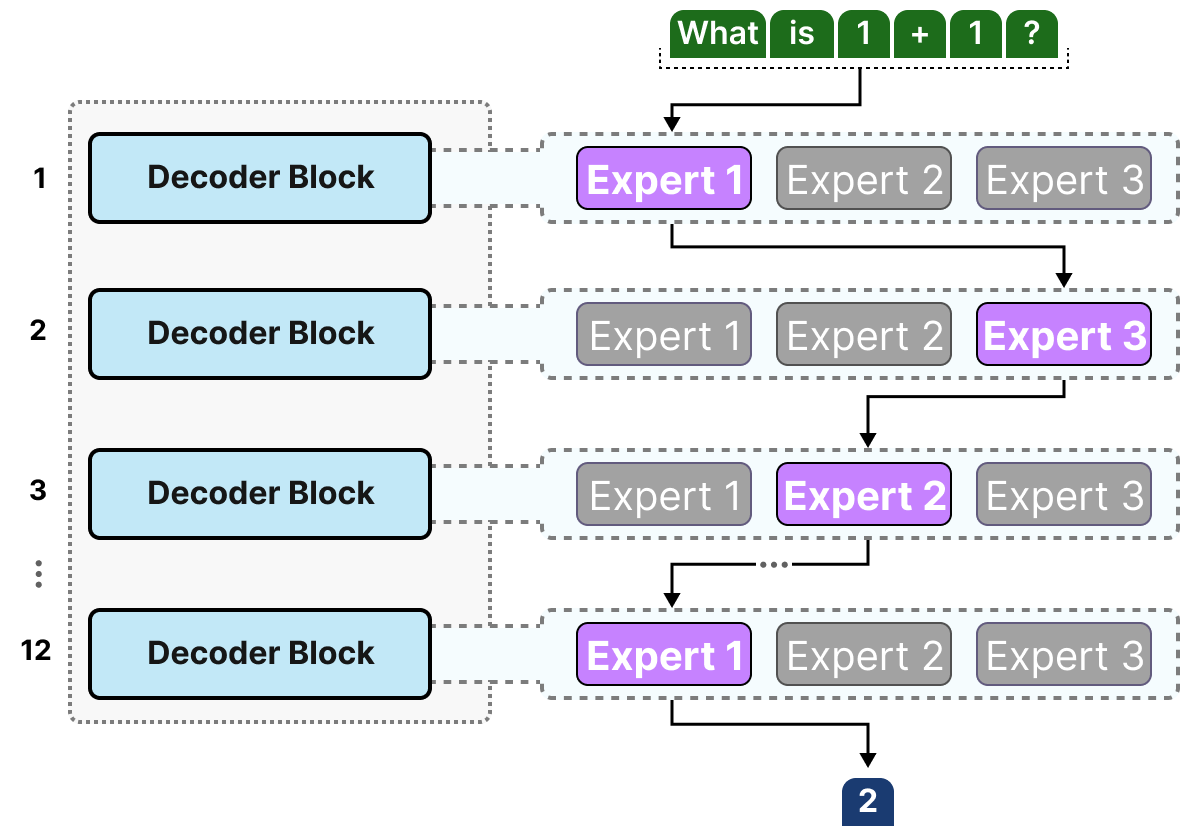
DeepSeek-Coder-V2 uses this Mixture-of-Experts (MoE) architecture - 236B total parameters but only 21B active per token. Yeah, it sounds like the same marketing garbage every AI company spews, but here's the thing: it actually fucking works. I've been running the lite version on a borrowed A100 and it generates React components that compile on the first try. Which is more than I can say for most human developers.
They trained it on trillions of tokens of code and math content. What this actually means: it's seen more real GitHub repositories than your entire engineering team combined. When it suggests a FastAPI route handler, it's not making shit up - it's pulling from actual production codebases.
The Two Models Worth a Damn
DeepSeek-Coder-V2 (236B parameters, 21B active)
- 128K context window (can process your entire monorepo without choking)
- Supports 338+ programming languages including that COBOL nightmare you're stuck maintaining
- Beats GPT-4 Turbo on code benchmarks - around 90% vs 88% on HumanEval
DeepSeek-Coder-V2-Lite (16B parameters)
- The "I don't have a server farm" version that still doesn't suck
- Generates better code than GitHub Copilot most of the time
- Actually fits on a single high-end GPU if you can afford one
Use the instruct versions, not the base models. I learned this the hard way after spending 2 hours debugging why the base model kept suggesting ArrayList<String> in my Python Flask app. Base models do autocomplete, instruct models understand what you're actually trying to accomplish.
The Benchmarks That Matter (And the Ones That Don't)
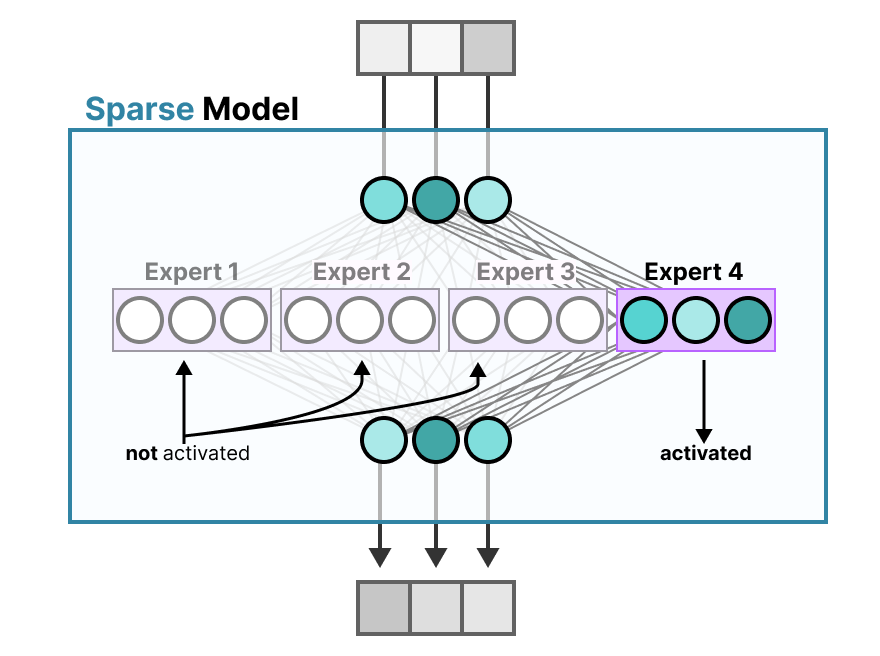
Look, benchmarks are usually complete bullshit, but these actually correlate with real-world performance:
- HumanEval: 90.2% (GPT-4 Turbo: 88.2%) - This is code completion on interview-style problems
- MBPP+: 76.2% (GPT-4 Turbo: 72.2%) - More realistic programming tasks
- LiveCodeBench: 43.4% (GPT-4o: 43.4%) - Updated monthly with fresh problems so models can't memorize
The math scores are impressive (GSM8K: 94.9%, MATH: 75.7%) but here's what really matters: this is the first open-source model that consistently beats closed-source alternatives at code generation.
When I'm debugging an async/await deadlock in .NET at 3am, DeepSeek immediately suggests ConfigureAwait(false) while GPT-4 gives me some generic "add retry logic" bullshit that makes the problem worse. There's your $20 difference per million tokens.
Language Support That Actually Matters

DeepSeek Coder supports 338+ programming languages. But here's what you actually care about:
- All the mainstream languages (Python, JavaScript, Java, C++, Go, Rust, TypeScript)
- The weird stuff you occasionally need (CUDA, Solidity, Julia)
- That legacy nightmare (COBOL, FORTRAN, Assembly)
- Domain-specific languages like R, MATLAB, and every SQL variant that's ever made you want to quit programming
The real magic? It understands context across languages. When you're building a Node.js API that calls a Python ML service, it suggests proper async/await patterns for the Node side and correct asyncio handling for the Python side.
How They Actually Trained This Thing
They trained it on 2 trillion tokens (87% code, 13% natural language). Here's why this actually matters instead of being another meaningless statistic:
- Trained on complete repositories, not just code snippets from Stack Overflow
- Project-level understanding - it knows that changing
config.pyaffectsmain.py - 128K context window means it can see your entire medium-sized codebase at once
- Fill-in-the-middle support using special tokens for code completion
Last month I had a Django ORM query hitting the database 847 times for a single page load. Fed the entire project to DeepSeek and it immediately identified the N+1 problem in line 23 of views.py, suggested select_related('author', 'category') on the exact queryset causing the issue. Took me 30 seconds to fix what would've been hours of debugging.
Anyway, here's how it stacks up against the competition.