memory_profiler solves the problem of "where the fuck is my Python script eating all the RAM?" While cProfile tells you what's slow, memory_profiler tells you what's fat. Simple as that.
It's Dead But Still Works
Version 0.61.0 from November 2022 is the final release. The maintainers officially threw in the towel - they're not fixing bugs or answering issues. But here's the thing: it still works perfectly. 4.5k GitHub stars don't lie. The code is stable, battle-tested, and handles Python 3.5+ without breaking.
How It Actually Works
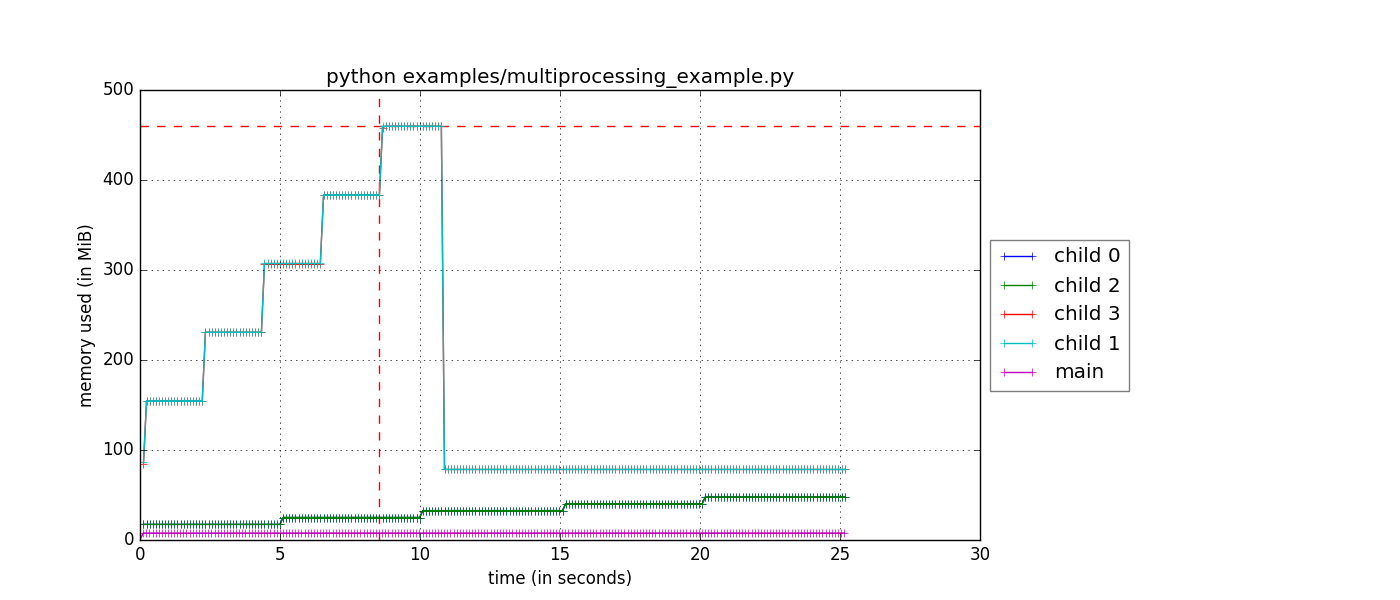
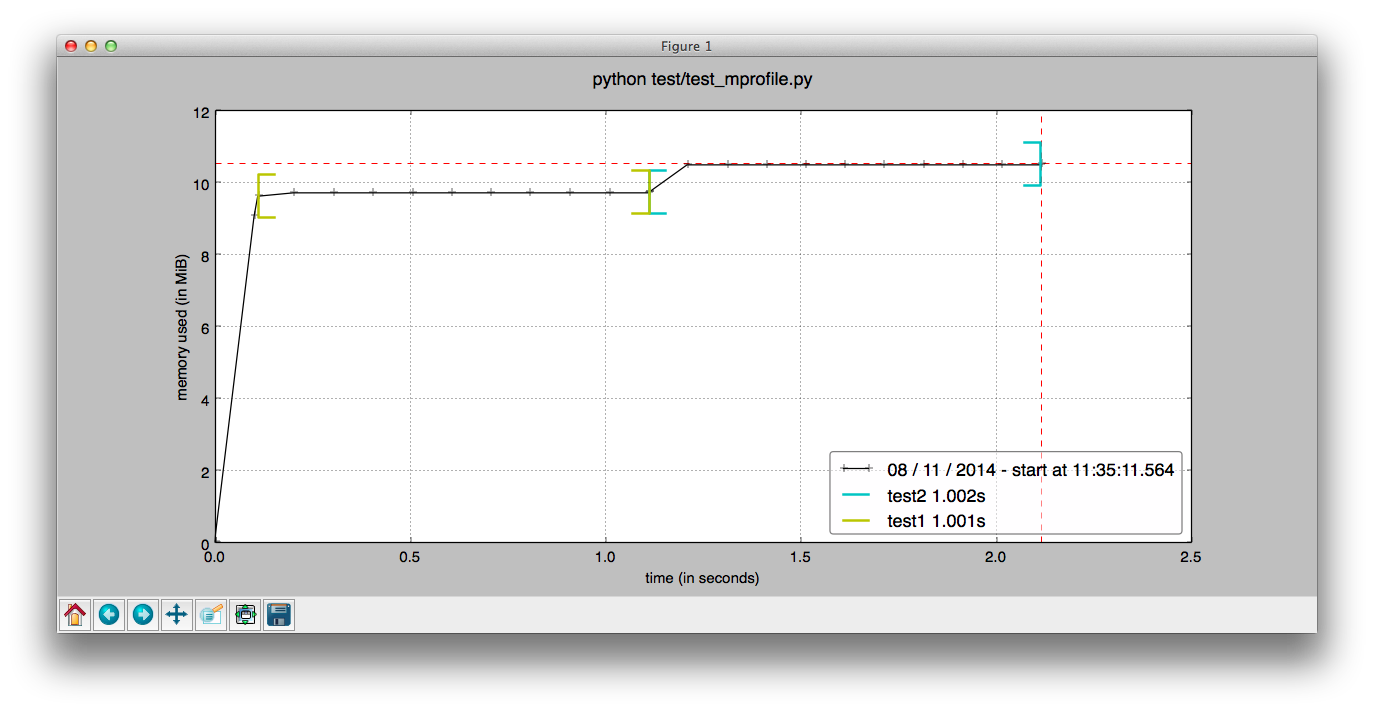
Two ways to use it: slap @profile decorators on functions for line-by-line analysis, or use mprof to spy on running processes externally. The decorator approach shows you exactly which line ate 500MB. The external monitoring catches memory leaks in production without touching your code.
It uses psutil under the hood for cross-platform memory readings. Unlike tracemalloc (which only tracks Python objects), memory_profiler shows real system memory including C extensions and whatever numpy is doing behind the scenes.

When You Actually Need This
memory_profiler is handy when your Python script eats more RAM than Chrome. Specifically:
- Your data processing pipeline randomly OOMs on production data
- Your web app slowly leaks memory until it dies at 3am (I once had a Flask app that leaked 50MB every hour - took three weeks to find the culprit: a pandas DataFrame that wasn't getting garbage collected because of a circular reference. memory_profiler pinpointed it in 20 minutes.)
- Your ML training crashes after 6 hours with "cannot allocate memory"
- You're debugging scientific code that should use 2GB but somehow needs 16GB
Works great with Jupyter notebooks via %mprun and %memit magic commands. Load it with %load_ext memory_profiler and you're off to the races.

Production Reality
Line-by-line profiling slows things down noticeably - expect 2-10x overhead depending on your code. I once had memory_profiler running on production and forgot about the overhead. Our API response time went from 200ms to 2 seconds. Customer called screaming about the slowdown while I frantically figured out why everything was broken. For production monitoring, use mprof to watch from outside. The measurements vary between runs because Python's garbage collector does whatever it wants, but the trends are reliable enough to catch real problems.