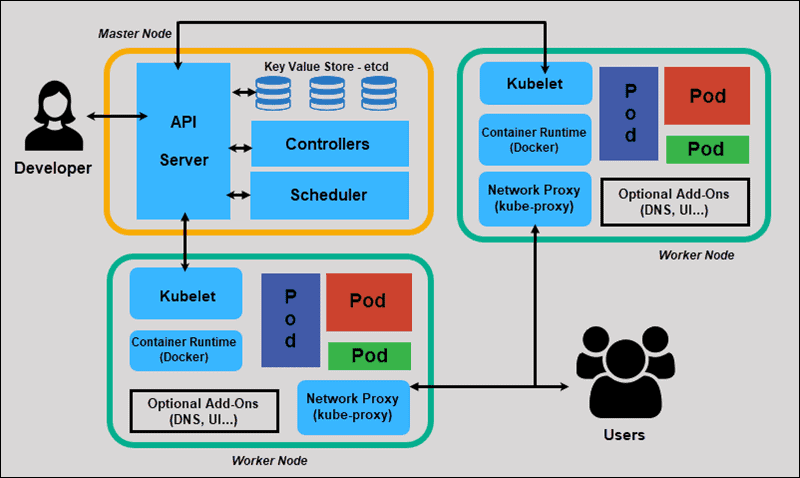
![]()
The Truth About AWS Discovery Tools
Forget AWS Application Discovery Service - it's garbage. I spent 2 weeks waiting for it to map dependencies only to discover it missed half our services and flagged a Redis cache as a "critical database dependency."
Instead, SSH into every box and run these commands:
df -h- see what storage you're actually usingfree -m- check memory allocation vs what AWS thinks you neednetstat -tulpn- find what services are talking to what (or usesson newer systems)systemctl list-units --type=service --state=running- see what's actually running
Takes maybe 2 hours vs the bullshit discovery process consultants wanted to charge us - what was it, like 50 grand? For a fucking Excel sheet.
What You'll Actually Find During Assessment

Compute Resources
Half your EC2 instances are over-provisioned because "we needed them for Black Friday 3 years ago." Your custom AMIs probably have security patches from 2019. Security groups will make you cry - somebody allowed 0.0.0.0/0 on port 22 because "it was faster than figuring out the actual CIDR."
Storage
S3 buckets with public read because someone needed to "quickly test something." EBS volumes that haven't been attached to instances in 18 months but still cost $200/month. EFS filesystems that someone created for a project that got cancelled but never cleaned up. Use AWS Config to find orphaned storage - saved me 3 hours of clicking through the console like an idiot.
Databases
RDS instances running MySQL 5.7 because "if it ain't broke, don't fix it" - except it IS broke, you just don't know it yet. DynamoDB tables with provisioned capacity that scales to handle traffic from 2018. ElastiCache clusters that nobody remembers the purpose of.
Network Clusterfuck
VPCs that were supposed to be temporary but became production. Route53 records pointing to ALBs that don't exist. NAT gateways costing $500/month to route traffic for a cron job.
Real Migration Objectives (Not Marketing Bullshit)
Cost Reality Check
The magical savings Google marketing loves to quote? Total bullshit. Our first GCP bill was fucking huge - like, higher than AWS because we just moved everything over without thinking. Took forever to clean up and fight with their weird pricing models before we saw any savings.
Performance Reality
GCP's network IS faster - until you hit cross-zone traffic, then latency sucks. BigQuery is amazing for analytics but terrible for transactional workloads (learned this during a late-night on-call when our reporting queries brought down production).
AI/ML Dreams vs Reality
Vertex AI sounds great until you realize your data is still in the wrong format and your team doesn't know Python. AutoML works for demos, breaks in production.
Building a Team That Won't Quit
Don't hire consultants
- One senior engineer who's done this before - worth 5 consultants
- Someone who knows your applications - database connections will break in ways you can't imagine
- A networking person - DNS will fuck you harder than you think
- Someone with GCP experience - IAM policies make AWS look simple
Plan 3x longer than you think. Our "2-week migration" took 3 months because nobody mentioned the mobile app hard-coded AWS IP addresses everywhere, the email service still pointed to Route53, and payment processor webhook URLs were all wrong. Found that last one when customers started complaining about failed payments during dinner. Fun times.
Ready to start? Let's dive into the migration process that actually works.