So you've heard pgcli makes psql bearable, but what does that actually mean? Let's be specific about where PostgreSQL's default client falls apart and where pgcli actually delivers.
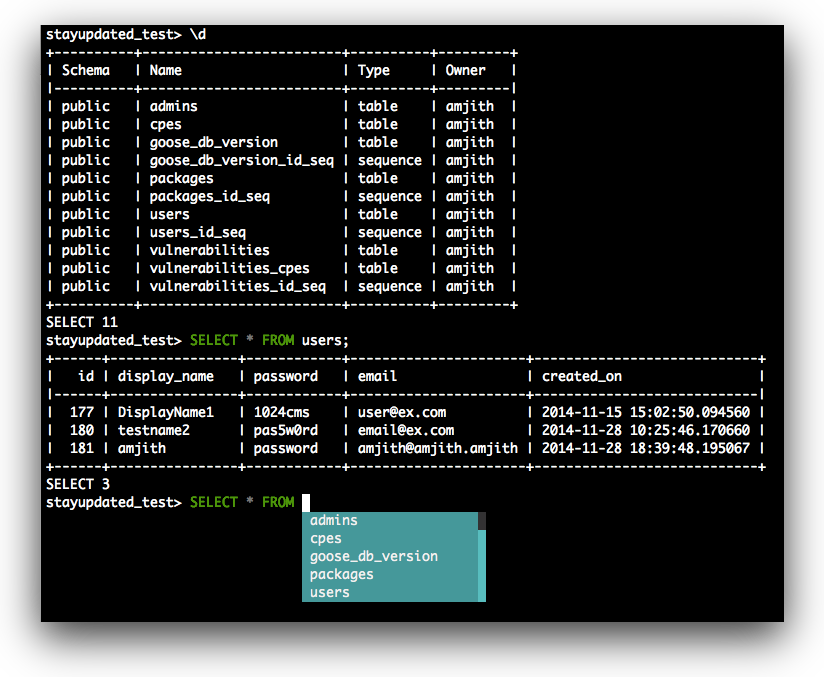
psql's tab completion is garbage. Type SELECT * FROM u and it suggests every command in your PATH instead of your user table. pgcli actually shows you table names like a sane person would expect.
Tab Completion That Actually Works
When you type SELECT * FROM and hit tab, pgcli shows your tables. When you type WHERE user_id = it shows columns from the users table. This is how completion should work, and somehow PostgreSQL's psql still hasn't figured this out after decades.
The catch? Schema indexing takes forever on databases with 500+ tables. First startup can take 30 seconds while it reads your entire schema. After that it's fast, until your database schema changes and it has to rebuild everything.
Auto-completion gets confused with complex JOINs and subqueries. Type something like SELECT u.name FROM users u JOIN orders o ON u.id = o.user_id WHERE and completion just gives up. Falls back to suggesting every column in your database.
Tables You Can Actually Read
psql output looks like ASCII vomit. pgcli formats results in actual tables with borders and proper alignment. No more counting spaces to figure out which value belongs to which column. It uses tabulate for table formatting and click for CLI styling.
The downside? Memory usage grows with result set size. Query returning 50k rows? pgcli eats 200MB of RAM formatting tables. psql just streams the output and uses 5MB. This is a known limitation of Python-based CLI tools vs native C programs.
Schema Awareness (Until It's Not)
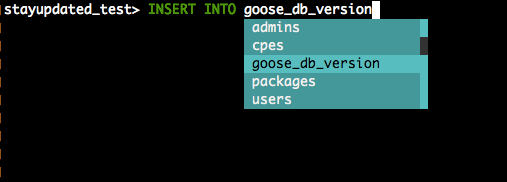
pgcli connects to your database and reads system catalogs to know about tables, columns, functions. Works great for development where you're constantly forgetting column names. The approach is similar to what SQL completion tools like DataGrip use.
Breaks on production databases where connection pooling interferes with schema queries. Also chokes on massive schemas - try using it on a database with 2000+ tables and watch it freeze for minutes.
Reality check: pgcli has 12k GitHub stars because it solves psql's most annoying problems. Just don't expect it to handle enterprise-scale databases gracefully. For comparison, mycli and litecli face similar scaling issues.
What's New in v4.3.0
The March 2025 release brought some improvements worth knowing about:
- Better Python 3.12+ compatibility - fewer dependency conflicts during installation
- Improved psycopg 3.x support - the newer PostgreSQL adapter, though psycopg2 still works fine
- Smarter schema caching - reduces startup time by 20-30% on databases with complex schemas
- Memory optimizations - still uses more than psql, but won't balloon as aggressively on large result sets
Still no fix for the fundamental scaling issues - 1000+ table schemas will still make it crawl. But for typical development databases (50-200 tables), it's noticeably snappier than previous versions.