What Actually Works Out of the Box
The free CLI scanner is legit. You can literally run curl -fsSL https://raw.githubusercontent.com/hounddogai/hounddog/main/install.sh | sh and start scanning Python, JavaScript, and TypeScript codebases immediately. The installation docs are actually clear, which is rare for security tools.
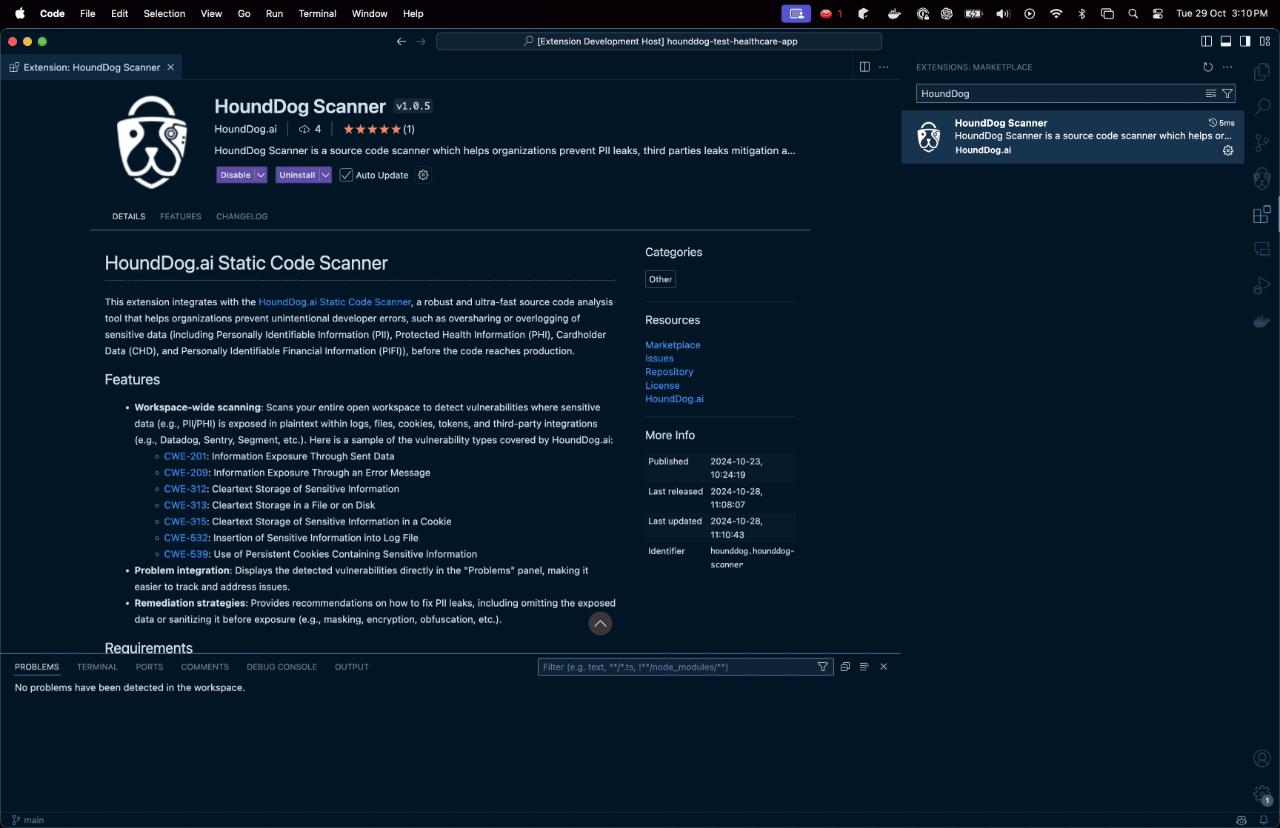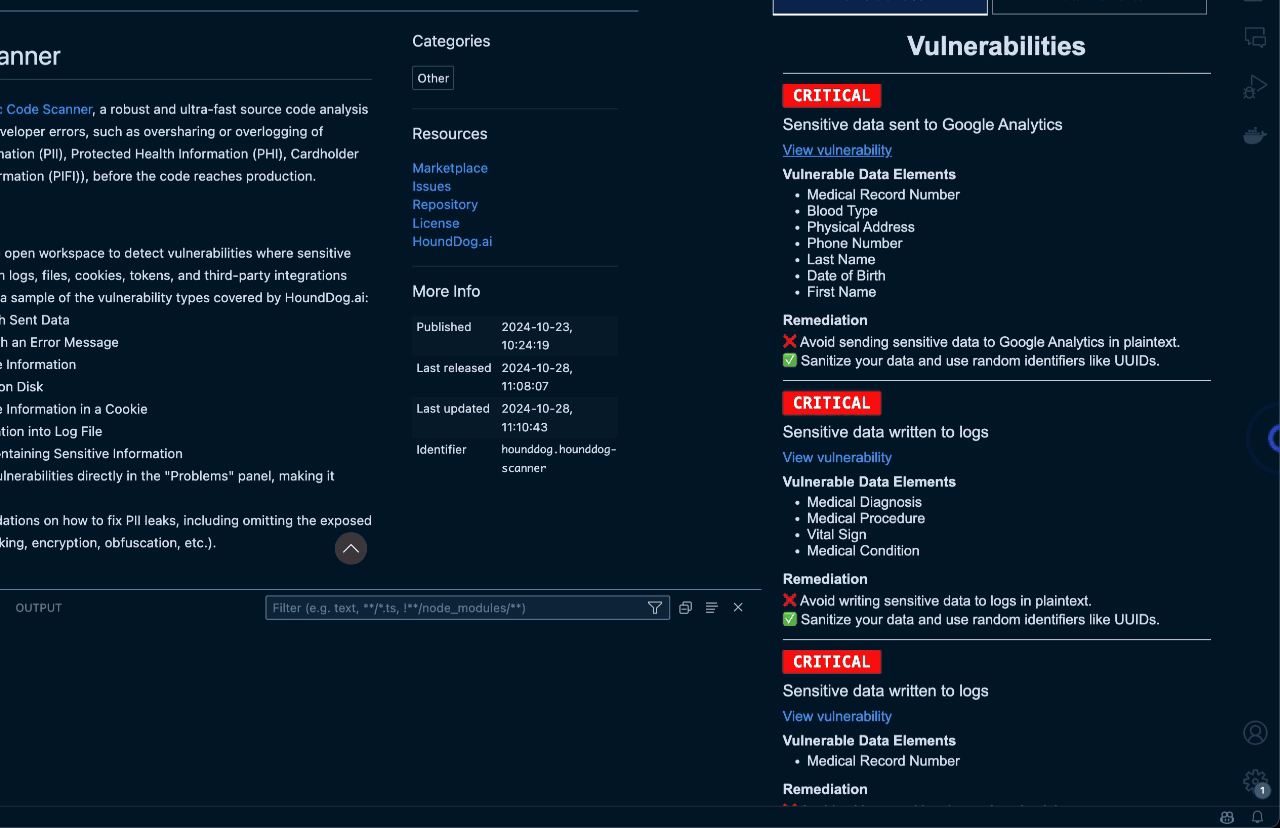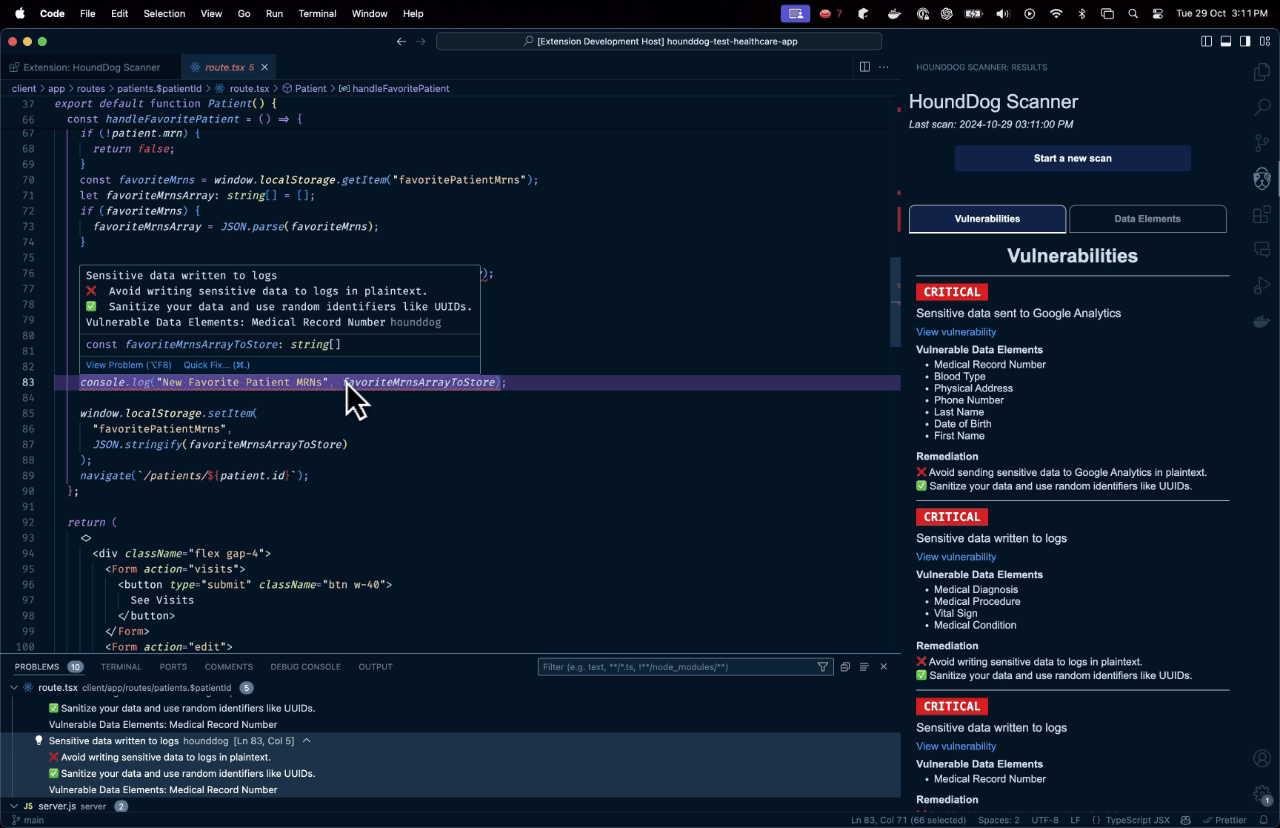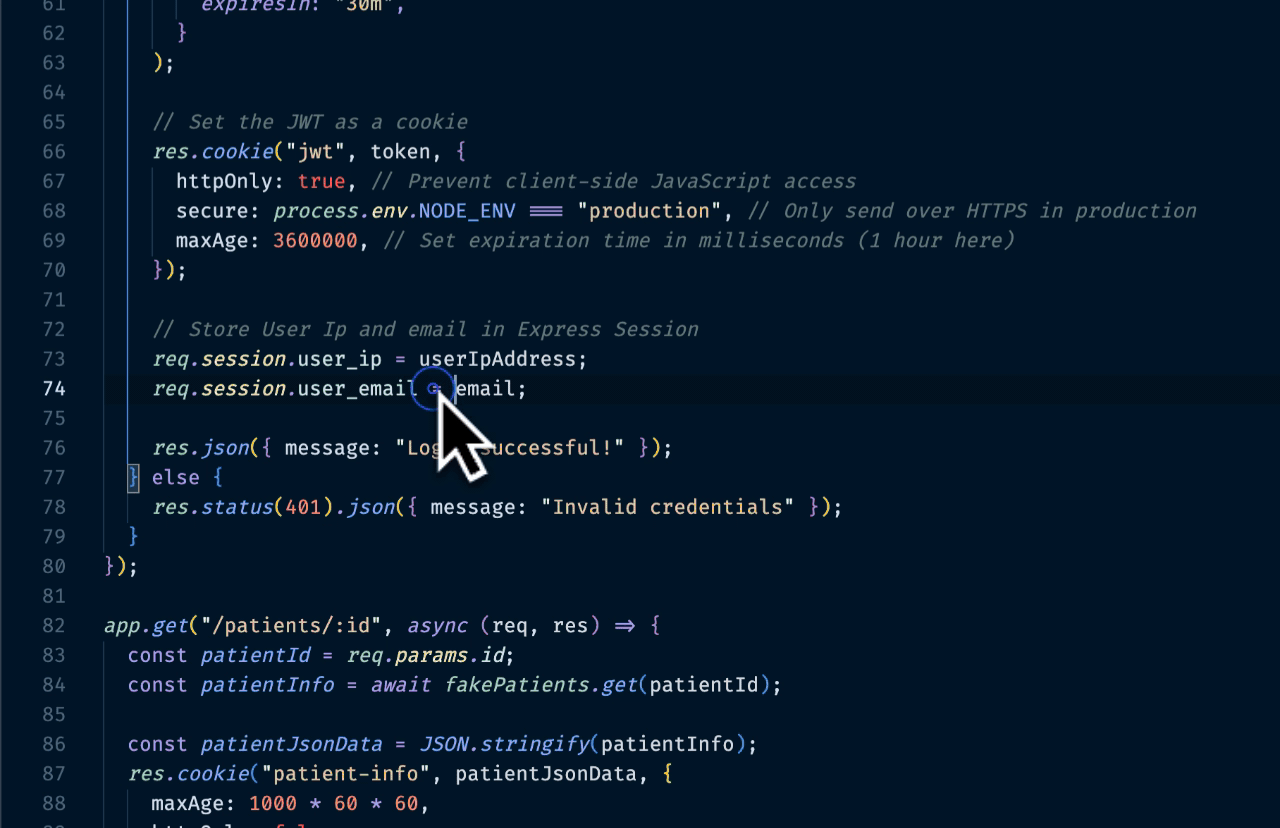
I tested it on a typical Node.js API and it caught actual issues within minutes: logging user objects with PII, accidentally exposing email addresses in error messages, and auth tokens being written to temp files. No false positives on the obvious stuff. This aligns with the CWE-532 and CWE-209 categories for information exposure.
The scanner respects .gitignore and lets you create .hounddogignore files, which is smart because you'll definitely need to exclude test data and mock files that intentionally contain fake PII.
Where the Demo Falls Apart
False Positive Hell
The marketing says "100+ sensitive data elements" like it's a good thing. In reality, it means the scanner flags variable names like user_id, customer_phone, and billing_address even when they're just field names in a GraphQL schema. This is similar to issues with other SAST tools that generate too many false positives.
Spent two days configuring allowlists just to scan our user management service without drowning in noise. The paid version supposedly has better tuning, but the free version requires manual tweaking of what constitutes "sensitive data" for your specific codebase.
Language Support Reality
Free version: Python, JavaScript, TypeScript only. Paid version adds Java, C#, Go, SQL, GraphQL, and OpenAPI.
If you're running microservices in multiple languages, the free tier is basically useless unless your entire stack is Node.js. Found this out the hard way when it completely missed PII exposure in our Java backend services.
CI/CD Integration Pain Points

The CI/CD docs make integration look trivial: "just add the scanner to your pipeline." What they don't mention:
- Exit codes aren't configurable, so any finding breaks your build
- No built-in way to fail only on high-severity issues
- The scanner can take 5-10 minutes on large codebases, adding significant build time
- Docker image pulls add another 30 seconds per build
Had to write custom wrapper scripts to make it actually usable in production pipelines. Similar to issues with SonarQube and other CI integration challenges. The paid platform supposedly handles this better with managed scans and PR blocking, but that's $100/developer/year minimum.
The AI Detection Claims
HoundDog.ai heavily markets their "AI-specific" scanning for LLM prompts and AI-generated code. This is actually pretty useful if you're using OpenAI APIs or similar LLM integrations.
The scanner caught several cases where our ChatGPT integration was accidentally including user email addresses in prompts. It also flagged instances where AI-generated code was logging sensitive variables that human developers might have sanitized.
But there's a catch: it only detects hardcoded prompts and obvious LLM API calls. Dynamic prompt construction and indirect AI usage (like through LangChain or custom frameworks) mostly get missed.
Enterprise vs DIY Decision
When DIY Makes Sense
If you have a small team (5-10 developers) working primarily in Python/JS/TS, the free version can work with enough configuration. Budget 2-3 days for initial setup and tuning.
You'll need someone to:
- Configure allowlists for your specific data patterns
- Write CI wrapper scripts for proper exit handling
- Set up regular scanning schedules
- Triage and fix findings
When You Need the Paid Platform
Teams with multiple languages, complex CI/CD, or strict compliance requirements should seriously consider the paid tier at $100/dev/year.
The managed scanning and PR integration alone saves weeks of engineering time. Plus you get actual support instead of filing GitHub issues and hoping.
The data flow visualization and automated compliance reporting are genuinely useful for audits and privacy impact assessments. Much better than manually tracking data flows through spreadsheets.
What They Don't Tell You About Deployment
Memory Requirements
The docs say "2GB+ memory" but that's optimistic. We hit OOM issues scanning repos with 100k+ lines of code until we bumped CI runners to 8GB.
Docker version needs 4GB allocated to Docker, which means your local dev environment better have 16GB+ total RAM or you'll be swapping constantly.
Performance Reality
"Blazingly fast" is marketing speak. Scanning a 50k line monorepo takes 3-5 minutes depending on the complexity. Not terrible, but not exactly "blazing."
IDE plugins are actually pretty responsive though. VS Code and IntelliJ integrations highlight issues in real-time without noticeable lag.
The Learning Curve
Junior developers struggle with understanding what constitutes PII exposure vs. legitimate data handling. Expect a lot of "why is logging user.id considered a security issue?" questions.
Senior developers get annoyed by false positives and start adding .hounddogignore entries for everything. You need clear guidelines on what's acceptable to ignore vs. what needs fixing.
The scanner is a tool, not a replacement for understanding privacy and security principles. If your team doesn't already have those fundamentals, HoundDog.ai won't magically make your code secure.
That said, it's one of the better static analysis tools for privacy-specific issues. Just don't expect it to work perfectly out of the box without some investment in configuration and developer education.