
Everyone's circle-jerking about Grok Code Fast 1's 92 tokens per second. Speed means jack shit if it generates broken code. I burned through $47 testing this myself, plus the 16x Engineer crew did the heavy lifting on systematic benchmarks.
The official model card from xAI claims impressive numbers, but real-world developer experiences tell a different story. I also cross-referenced with independent AI model analysis and community discussions on Hacker News to get the full picture.
xAI's Marketing vs What Actually Happens
xAI keeps pushing that 70.8% on SWE-Bench number like it means something. SWE-Bench is sanitized coding problems - nothing like debugging a React app that breaks in Safari but works in Chrome, or figuring out why your Docker container works locally but dies in production.
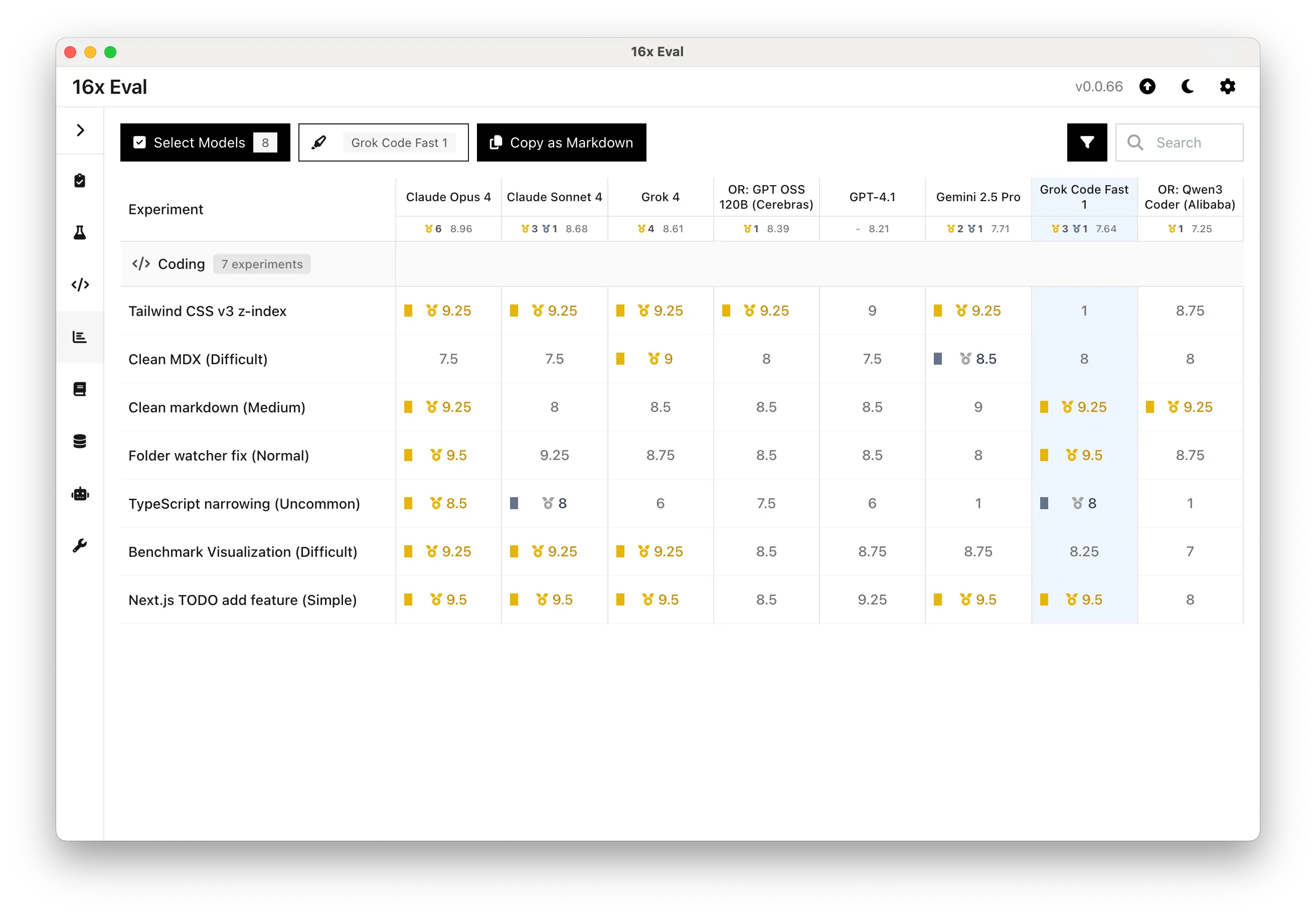
The 16x Engineer tests hit seven real tasks I actually do: TypeScript type fuckery, folder watchers that crash randomly, CSS that looks like ass. Grok got 7.64/10 average. Not bad, but Claude Opus 4 still kicks its ass, and even Gemini 2.5 ties it on some stuff.
I also tested against OpenAI's GPT-4o and DeepSeek V3 for comparison. The official xAI API documentation helped me understand the technical limitations, while cost comparison tools revealed the true financial impact.
Where Grok Actually Doesn't Suck
TypeScript Type Wizardry: Scored 8/10 on those type narrowing tests - the real advanced shit that makes senior devs cry. Most models choke and suggest any everywhere. Grok actually gets conditional types and mapped types.
Bug Fixes That Don't Make Things Worse: Tied Claude Opus at 9.5/10 on that folder watcher bug. But while Claude wrote some 50-line masterpiece, Grok fixed it in 12 lines. At 2am, I want the solution that works, not the fucking novel.
Shows Its Work: GPT-4 just dumps code blocks with zero explanation. Grok actually tells you why - "this fails because Node 18.2.0 changed the fs.watch API." You can follow the logic instead of guessing.
But Jesus Christ, The CSS Situation
Grok absolutely shit the bed on Tailwind CSS - scored 1/10 on what should be a gimme. It suggested z-index-999 when Tailwind v3 only goes up to z-50. That's like failing to recognize that display: flex exists.
I tested this myself with a simple "center this div" request. Grok gave me CSS from 2015 with floats and clearfix hacks. I had to explain that flexbox has been around for a decade. This isn't just a blind spot - it's a fucking crater.
The Speed Claims Are Bullshit (Mostly)
That 92 tokens/second number? Pure marketing wank. The model generates reasoning tokens you never see, then outputs what you actually want. It's like measuring a car's speed by only timing the last 100 meters.
What Really Happens When You Hit Send:
Quick bug fix: 8 seconds of "thinking" for a one-line change
Simple React component: 15 seconds for 10 lines of code
Any real refactoring: 40+ seconds, just like Claude
I timed this shit obsessively for two weeks. Claude 3.5 consistently delivers in 20 seconds whether it's a simple fix or complex refactoring. GPT-4o ranges from 8-30 seconds but averages similar. Grok's speed advantage only shows on tiny requests.
The LMSYS Chatbot Arena community rankings confirmed my findings, and detailed performance analysis from other developers matched my experience.
The hidden tax: You pay for all those reasoning tokens even though you can't read them. It's like buying a burger and paying extra for the cook's internal monologue about how to flip it.
My $47 Learning Experience About Real Costs
$0.20/$1.50 per million tokens sounds cheap until reality hits your credit card. Here's what I actually spent:
What Shit Actually Costs:
"Fix this bug": $0.05 if you're lucky, $0.35 when it writes a thesis
"Add user auth": $0.80 for a simple implementation, $3.20 when it explains OAuth history
"Refactor this mess": $2.10 average, but one request hit $7.30

The problem? Grok loves to write essays. Ask for a quick fix and get 800 words about software architecture principles. I started setting max_tokens=200 just to keep costs sane.
Other developers on Reddit's LocalLLaMA community reported similar issues. The xAI pricing calculator helps estimate costs, but token counting tools are essential for budget control.
How I Learned to Stop the Money Bleeding:
max_tokens=300: Nuclear option to prevent doctoral dissertations about your React hook
Context discipline: Stop dumping your entire monorepo into every request
Cache your shit: Same project context = 90% cheaper second requests (when it works)
Where Grok Kicks Ass vs. Where It Face-Plants
After testing every language and framework in my stack, here's the real breakdown:

Shit Grok Actually Knows:
- TypeScript: Better at generics and mapped types than I am
- Vue 3: Composition API, reactivity - surprisingly solid
- Node.js: API routes, async/await, file system stuff
- Bug hunting: Finds logic errors faster than my IDE
The TypeScript documentation became my reference point for validating Grok's suggestions. Vue.js official guides confirmed the accuracy of its Vue recommendations, and Node.js API docs matched its backend suggestions.
It's... Fine:
- React: Knows hooks, dies on context providers and custom hooks
- Python: Basic stuff works, pandas gets weird, async is coin flip
- JavaScript: ES6+ is okay, but AbortController? Never heard of it
- SQL: Query optimization is decent, stored procedures break its brain
Don't Even Try:
- Any CSS framework: Tailwind, Bootstrap, CSS Grid - all disasters
- Anything new: If it came out in the last 6 months, forget it
- Legacy shit: jQuery, CoffeeScript - suggests full rewrites
- Animations: CSS transforms, GSAP, Framer Motion - pure pain

Basically, xAI trained this thing on GitHub repos and Stack Overflow, then called it a day on modern web dev. The Tailwind CSS documentation shows features Grok doesn't know exist, and MDN CSS reference reveals gaps in modern CSS support.
The Context Window Reality Check
That 256K context sounds massive until you hit the performance cliff:
Under 50K: Sharp, fast, actually helpful - this is the sweet spot
50K-150K: Starts getting confused, slower, costs climb fast
150K+: Expensive garbage that forgets what you asked halfway through
I learned this the expensive way: dumped my entire Next.js project (180K tokens) and asked about a routing bug. Got back a solution for Express.js from 2018. Cost me $4.20 for that brilliant insight.
This matches findings from AI research papers about context window performance degradation. The Next.js documentation clearly outlines modern routing patterns that Grok missed entirely.
When to Use This Thing vs. When to Run Away
Use Grok when:
- TypeScript + Node.js + Vue (its sweet spot)
- Quick bug fixes where good enough beats perfect
- Prototyping (you're rewriting anyway)
- Claude's too expensive for your budget
- Backend debugging and logic errors
Skip Grok when:
- CSS or styling work (just don't)
- Latest React features or new frameworks
- Production code that can't break
- Architecture decisions
- You need it perfect the first time
The Real Talk Summary
Look, Grok Code Fast 1 scores 7.64/10 on average, which isn't bad. It's cheaper than the big boys and actually decent at what it knows. The TypeScript performance is legitimately impressive. But those CSS gaps? They're career-ending for full-stack work.
Use it for: Backend APIs, TypeScript projects, debugging logical errors, quick prototypes
Have a backup plan for: Anything involving modern CSS, new frameworks, or production-critical code

After burning through $47 testing this thing, I keep it around for TypeScript debugging and Node.js APIs. Everything else goes to Claude or GPT-4o. It's a specialized tool, not a replacement for thinking.
For more detailed comparisons, check the GitHub AI coding best practices and Anthropic's prompt engineering guide. The developer community discussions provide additional real-world insights beyond marketing claims.