![]()
I've been through the AWS SageMaker hellscape, suffered through Azure ML's YAML nightmares, and landed on GCP Vertex AI. SageMaker broke our production inference three fucking times in six months - like just randomly stopped responding during peak traffic. Azure ML had worse uptime than my college WiFi. So yeah, I use Vertex AI now, and here's why you might want to consider it - though Google's quota system will test your patience and their error messages are still garbage.
Gemini Models Don't Suck (Unlike Claude on Bedrock)
Real Talk on Model Performance: I tested Gemini 2.5 Pro against Claude 3.5 on Bedrock for our customer support classifier. Gemini was noticeably better at understanding context, especially when customers uploaded screenshots of error messages. Claude kept hallucinating database error codes that didn't exist. Check the Vertex AI Model Garden for all available models.
The AutoML Reality Check: Used Vertex AI's AutoML for sentiment analysis on support tickets. It actually worked better than expected - got decent results in a couple hours instead of the weeks I'd normally spend tuning BERT models. Hit 91.3% accuracy on our dataset vs 87% from my hand-tuned BERT after 3 weeks of hyperparameter hell. AWS Comprehend gave us garbage results on the same dataset.
Performance That Actually Matters: Gemini inference is around 100ms for our use case, fast enough that users don't notice. More importantly, it doesn't just randomly shit the bed like AWS Bedrock did during some holiday weekend - I think it was Black Friday but might have been cyber Monday, anyway we were down for a couple hours and everyone was freaking out. See Vertex AI performance benchmarks for metrics.
Embeddings That Don't Break the Bank: The embedding models are actually pretty good and way cheaper than OpenAI's embeddings. I can batch 250 texts in one API call instead of making individual requests like some kind of savage. Performance is solid for semantic search - not groundbreaking, but it works and doesn't cost a fortune. Compare Vertex AI pricing with other providers.
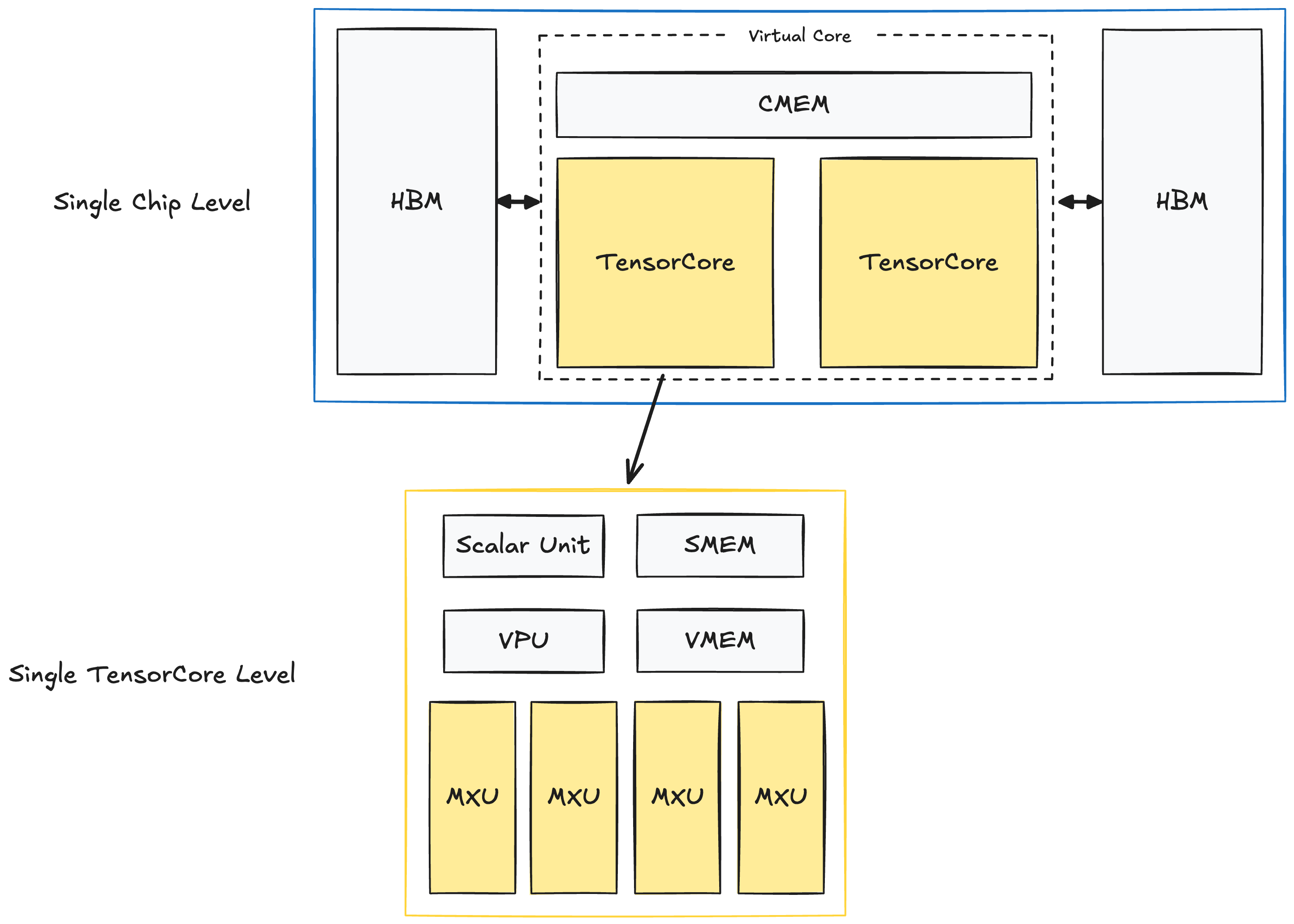
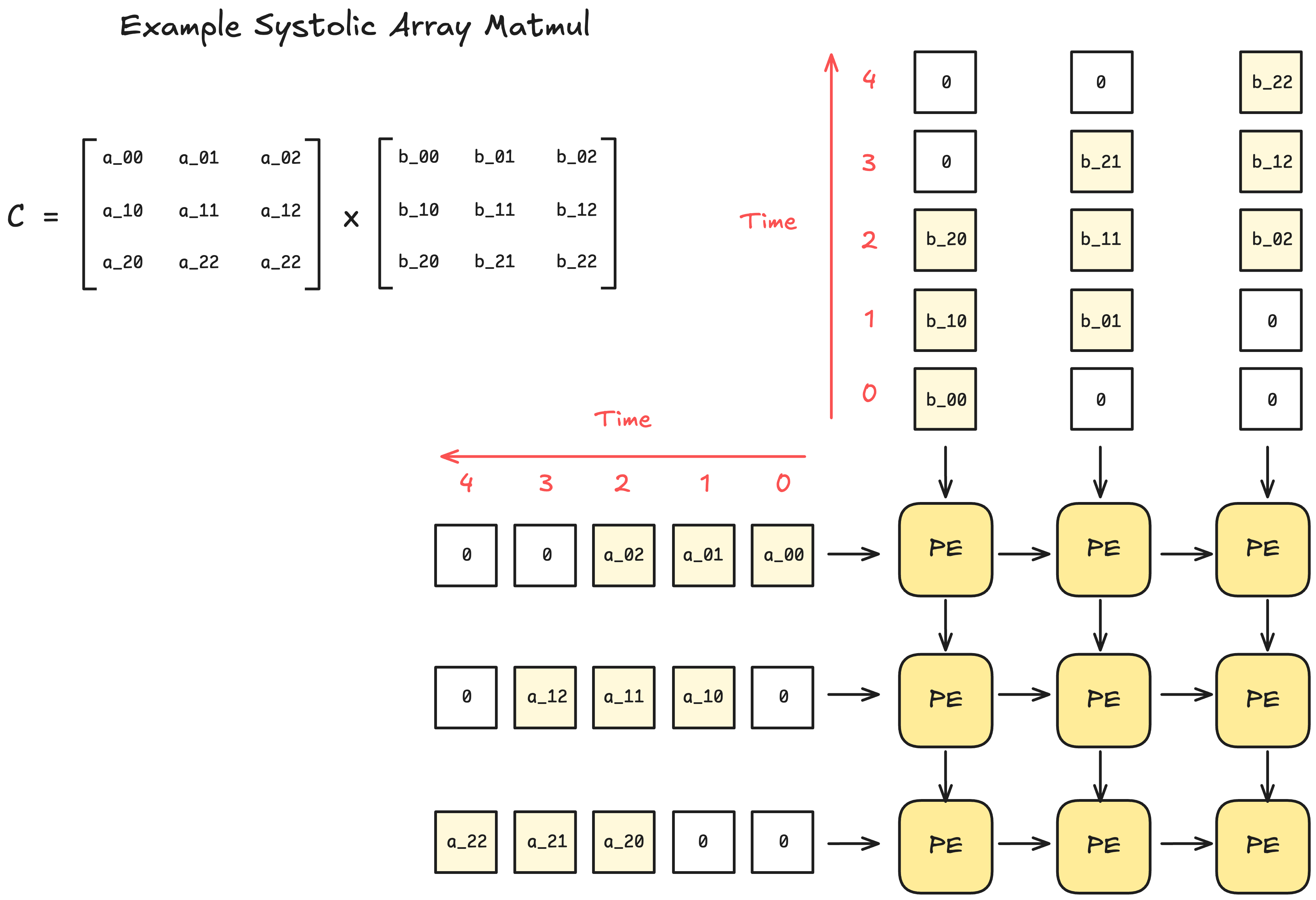
TPUs Are Fast But Good Luck Getting Quota
TPU Quota Hell: I requested TPU v6e quota in like March or April for a BERT training job. Got approved in fucking August after three follow-up emails and some VP escalation bullshit. Meanwhile, I could spin up AWS Trainium instances in 5 minutes. Google's TPU allocation process is a bureaucratic nightmare that makes getting a mortgage look simple. Their quota documentation won't prepare you for the pain.
When TPUs Actually Work: TPU training was way faster - maybe 4-5 hours instead of the usual all-day torture session on AWS Trainium. Yeah, it's faster, but you pay for the privilege and pray the job doesn't get preempted. Preemptible instances save money but can randomly kill your 7-hour training run at 99% completion. Learned this the hard way when I lost an entire weekend's worth of work. Check the pricing before you get sticker shock.
The Ironwood Mirage: Google keeps talking about their new Ironwood TPU for inference. Sounds great in theory, but try actually getting access to it. I'm still on the waitlist 6 months later. At this point I'd rather just use GPU instances that I can actually provision. See TPU system architecture if you want the technical details.
At Least Everything's In One Place (Mostly)
Why I Don't Miss AWS's Cluster of Services: Remember trying to connect SageMaker to S3 to Lambda to CloudWatch? Vertex AI actually puts most ML stuff in one console. The BigQuery integration means I can just write fucking SQL instead of babysitting Spark clusters that die every Tuesday for mysterious reasons.

MLOps That Sort Of Works: Vertex AI Pipelines uses Kubeflow under the hood, which is both good and bad. Good because it's standardized. Bad because debugging pipeline failures still makes me want to switch careers. But it's better than Azure ML's YAML hell or SageMaker's "guess which service broke this time" approach. Check the pipeline samples if you're masochistic.
Model Deployment Isn't Completely Terrible: Vertex AI Endpoints scale automatically and don't randomly fail during traffic spikes like AWS used to do. Latency is decent - around 100ms for most inference calls. The auto-scaling actually works, unlike the early SageMaker days when endpoints would just... stop responding. Read endpoint best practices to avoid basic mistakes.
Pricing Is Less Bullshit Than AWS (Low Bar)
At Least You Can Predict The Bill: GCP pricing actually makes sense, unlike AWS where you get mystery charges for shit you didn't even know existed. Gemini tokens cost around $2.50 for input, $15 for output per million tokens. Not cheap, but no random network transfer fees or mysterious NAT Gateway bills that AWS loves to hit you with.
AutoML Isn't Highway Robbery: Yeah, AutoML costs money, but consider the alternative: paying me to spend 3 weeks tuning hyperparameters just to get worse results. AutoML gave us a working sentiment classifier in 2 hours. Time is money, and my sanity is priceless.
TPU Minimum Commitment Gotcha: Here's something they don't advertise: TPU jobs have minimum 8-hour billing. Some intern ran what should have been like a 30-minute experiment and we got billed for the full 8 hours - I think it ended up being around $400 instead of maybe $40. Now I make everyone use preemptible instances for testing or finance will have our asses. Learn from my pain.
If You're Already On Google, It Makes Sense
Google Workspace Integration: If you're using Gmail and Google Docs already, the SSO integration is actually smooth. No fighting with SAML configs or mysterious permission errors. Data flows between BigQuery and Vertex AI without the usual cross-service authentication nightmares.
Security Compliance Checkbox: Got all the compliance certifications your security team needs - SOC 2, HIPAA, FedRAMP. VPC Service Controls actually work for keeping data in your VPC, unlike some other cloud providers I could mention.
When You Should Probably Use AWS Instead: If you need to integrate with a bunch of third-party ML tools, AWS has better ecosystem support. If you're already invested in AWS infrastructure, the migration headache probably isn't worth it unless SageMaker is actively ruining your life (like it was mine).
When to Skip Vertex AI Entirely
Don't Bother If:
- You need to ship something in the next 2 weeks (learning curve exists)
- Your workflow depends on specific ML tools that only support AWS
- You can't wait 3+ months for TPU quota (if you need TPUs)
- Your AWS setup is working fine and you're not getting massive surprise bills
Bottom Line: Vertex AI works better than I expected, especially after AWS burned me multiple times. Google's quota system is still bureaucratic hell and some features are rough around the edges. But if you're starting fresh or SageMaker is actively making your life miserable, it's worth the learning curve.
The real test is whether it'll scale with your team's needs without surprise failures. So far, so good - but I'm keeping my AWS fallback plan just in case Google decides to randomly change something important.