AWS defaults are designed to get you up and running fast, not to keep you secure. Every default setting is basically "make it work first, secure it never." That EC2 instance you just launched? It's probably wide open. That S3 bucket? Public by accident. That IAM role? Has more permissions than your CEO.
I learned this the hard way when our startup got breached in 2023. Someone found an EC2 instance with 0.0.0.0/0 in its security group, lateral moved through overprivileged roles, and spent three weeks mining crypto on our bill before we noticed. Total damage: $47,000 in compute costs and about six months of trust rebuilding with customers.
The Brutal Reality of Cloud Security Stats
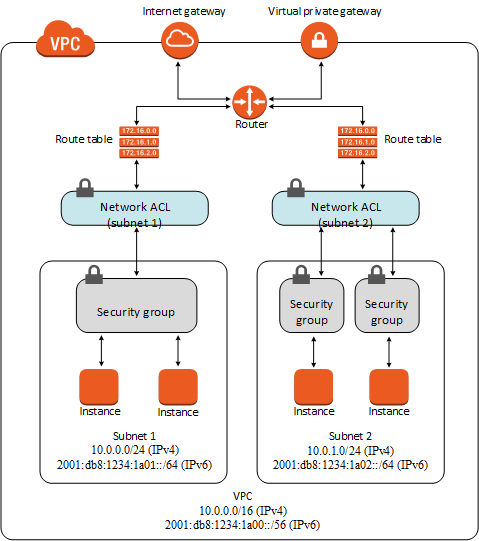
![]()
AWS security is complex - that's the whole point of this guide
Look, I don't have exact percentages on how many companies get fucked by AWS misconfigurations, but it's basically all of them. Recent cloud security reports show that 45% of data breaches happen in cloud environments, and most aren't sophisticated nation-state attacks - they're stupid shit like exposed databases and hardcoded API keys.
The attacks I've seen personally:
- Exposed git repos with AWS keys - happens at least once per quarter at every company I've worked at. GitHub's secret scanning helps but people still fuck it up
- RDS instances accessible from the internet - found three of these in our production account during my first security audit. AWS RDS security best practices exist but nobody reads them
- IAM users with
AdministratorAccessthat haven't been rotated in two years - I shit you not, one startup had 47 of these. AWS IAM access keys rotation is a thing for a reason - S3 buckets with public read that contain customer data - this is how we made TechCrunch for all the wrong reasons. Check AWS S3 bucket policies before you cry
AWS Security Is Your Problem, Not Theirs
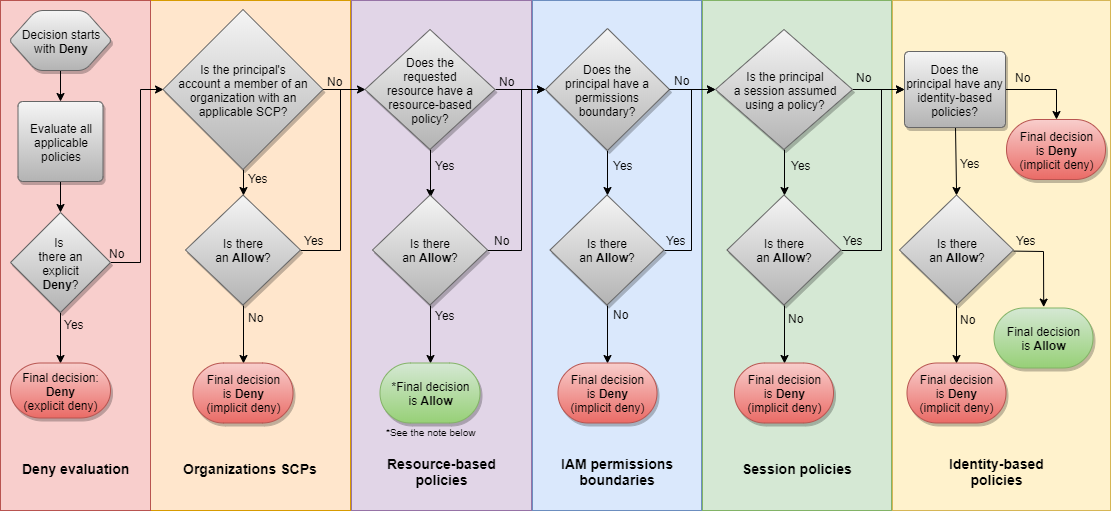
How IAM policy evaluation actually works - this flowchart is why engineers cry
The AWS Shared Responsibility Model is basically AWS saying "we'll keep the lights on, you figure out everything else." They secure the physical infrastructure, you secure:
- Every fucking IAM policy (and IAM policies are about as readable as tax code written by drunk lawyers)
- All your network configs (Security Groups with 0.0.0.0/0 are how production dies at 2am)
- Data encryption (because storing plaintext customer data is career suicide)
- Access logging (CloudTrail and GuardDuty alerts are 90% noise until you tune them for 6 months)
- Monitoring everything (because if a crypto miner runs for three weeks without you noticing, you're doing it wrong)
The Enterprise Nightmare Gets Worse
Think securing one AWS account is hard? Try managing security across 200+ accounts with 500+ developers who just want to ship code and don't give a shit about your security policies.
Real problems from my consulting days:
- Account sprawl: Found a fintech with something like 800+ security group rules pointing to 0.0.0.0/0 - stopped counting after 500 because it was too depressing
- IAM role explosion: One client had like 12,000 IAM roles or something insane across their org. Could've been more, nobody was actually counting the mess
- Compliance theater: Spent six months implementing SOC 2 controls that looked good on paper but broke production deployments twice a week
- Cost explosion: Security logging increased their AWS bill by around 40%, but that's the price of not getting fired when your competitor gets breached
What Actually Works (Based on Getting My Hands Dirty)
This guide isn't theoretical bullshit from someone who's never debugged a security incident at 3am. Everything here comes from:
- Five years of cleaning up breached AWS accounts - from startups to Fortune 500s
- Real production incidents - including the time I accidentally locked everyone out of our production environment while implementing MFA
- Compliance audits - where auditors find every shortcut you thought was clever
- Cost optimization - because security controls that bankrupt your company aren't effective
Every section includes:
- The exact CLI commands that actually work (copy-paste ready)
- What breaks when you implement it (spoiler: everything, at first)
- Time estimates based on reality (5 minutes if you're lucky, 2 hours if not)
- The nuclear option when nothing else works ("delete node_modules and try again" equivalent for AWS)
The 3AM Security Reality Check
![]()
All the AWS security services you'll need to actually secure your infrastructure
Real security hardening means assuming your first line of defense will fail. When someone inevitably commits AWS keys to GitHub (they will), when a developer gives an EC2 instance admin privileges because "it was easier" (they will), when your monitoring fails to catch the obvious attack (it will) - what happens next?
Here are actual attack patterns I've responded to:
The GitHub Key Leak: Junior dev commits `.env` file with production AWS keys. Keys get scraped within 10 minutes by automated credential harvesting bots, attacker spins up GPU instances for crypto mining. We caught it because our AWS bill jumped $200/hour.
The Phishing Success: CFO clicks malicious link, attacker resets their AWS console password (no MFA, obviously). Escalates through overprivileged IAM roles, deletes our production databases for ransom. Restore took 18 hours thanks to RDS automated backups.
The Supply Chain Fuckery: Popular npm package gets compromised, includes code that searches for AWS credentials in environment variables. Steals credentials from container environments, accesses customer data through unrestricted S3 buckets.
Each of these could have been stopped with proper hardening. But the hardening has to survive contact with real developers, real deadlines, and real production emergencies. Theoretical security that breaks everything isn't security - it's job security for whoever has to clean up the mess.