Look, CockroachDB is basically PostgreSQL that got stretched across multiple machines and regions. As of September 2025, the latest available version is v25.3. But here's what nobody mentions upfront: they killed the open source version on November 18, 2024. Now it's all proprietary with a "free tier" that disappears when your company hits $10M revenue and requires sending them telemetry about everything you're doing. So factor that vendor lock-in into your decisions.
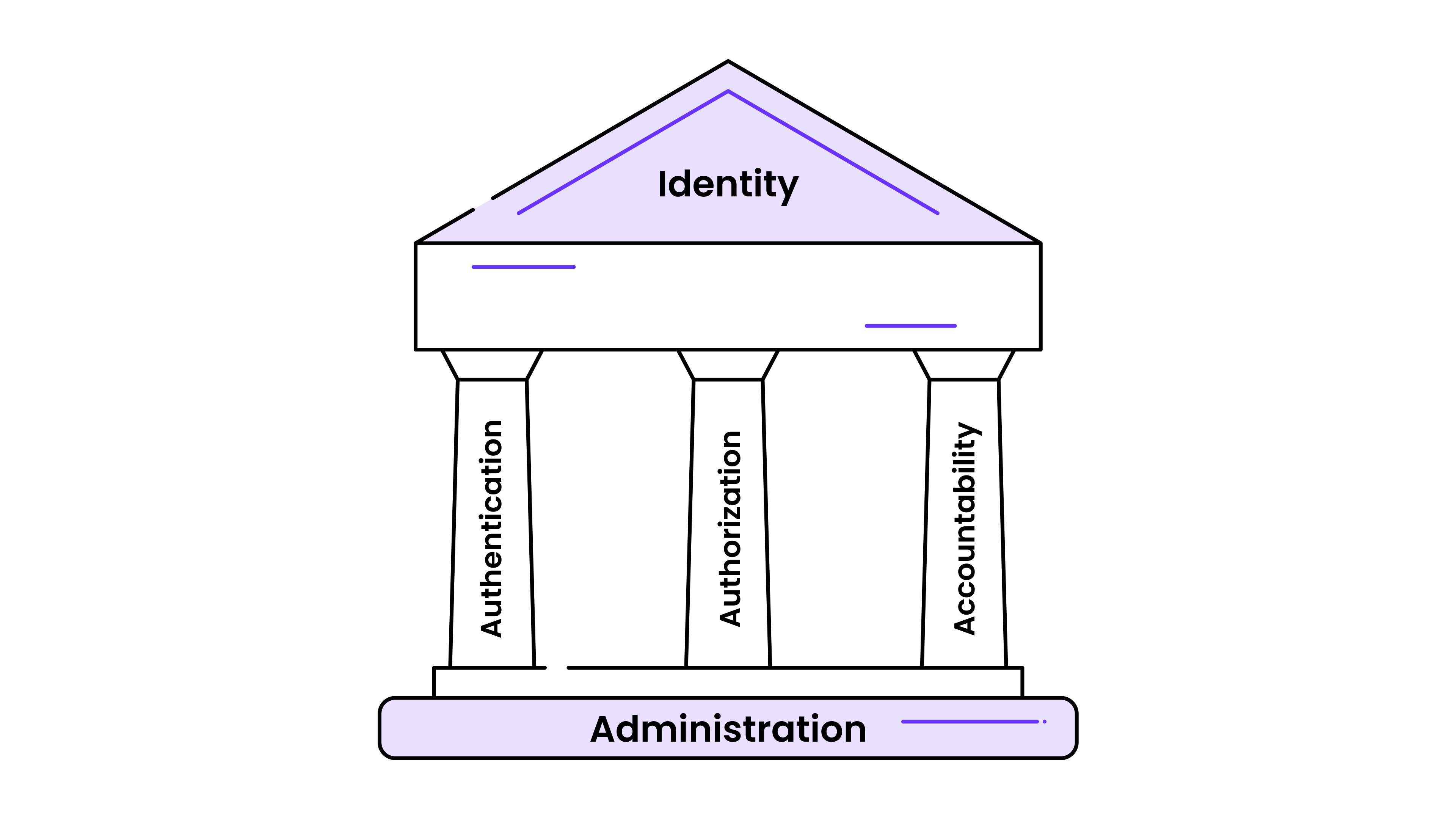
How the Distributed Thing Actually Works

CockroachDB splits into five layers that handle different parts of the database:
SQL Layer: Takes your PostgreSQL queries and breaks them down into smaller pieces that can be distributed. About 80% of your existing app will probably work without changes, but expect to hit some edge cases with the PostgreSQL features they don't support yet.
Transaction Layer: Uses timestamps and distributed consensus to make sure your transactions work across multiple machines in different regions. Slower than single-node PostgreSQL (2-10ms writes vs sub-millisecond), but it actually works reliably across continents.
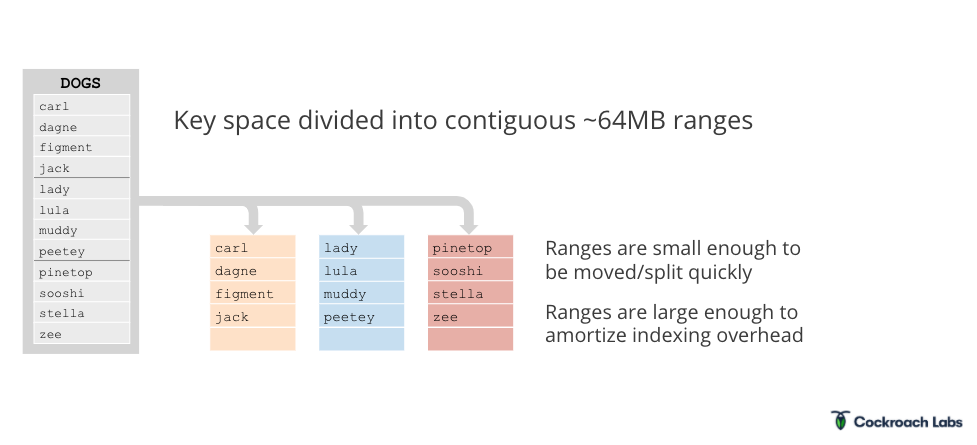
Distribution Layer: Automatically splits your data into ranges and tries to keep related data together. Sometimes it gets this wrong and you'll spend a weekend figuring out why your queries are slow because related data ended up on different continents.
Replication Layer: Uses Raft consensus to keep 3+ copies of everything. When nodes die (and they will), the remaining nodes vote on who's in charge. Pretty solid, though you'll get paged when nodes go down.
Storage Layer: Pebble storage engine underneath handles the actual disk I/O. It's optimized for writes, which is good because distributed systems do a lot of writing to maintain consistency.
What Actually Makes This Worth the Complexity
Strong Consistency
CockroachDB gives you serializable isolation - your transactions either happen or they don't, no weird edge cases where data appears and disappears. The ACID guarantees documentation explains how this works across regions. This is why you'd consider this over just running PostgreSQL read replicas.
Horizontal Scaling That Actually Works
Adding nodes to the cluster actually makes things faster and more reliable. Production clusters can scale to hundreds of nodes across continents. The auto-rebalancing system redistributes data when you add nodes, though "automatically" still means you'll spend time tuning and monitoring. Netflix's case study shows how they scaled to massive workloads.
Multi-Region Without the Headache
The multi-region features are where CockroachDB beats rolling your own solution:
- Regional Tables: Pin tables to specific regions for compliance or latency
- Global Tables: Put read-heavy reference data everywhere for fast local reads
- Regional by Row: Automatically place rows based on content (like user location)
This saves you from building your own sharding logic and dealing with cross-region consistency problems. The multi-region deployment patterns guide shows configurations that work in production.
Self-Healing (Mostly)
When things break, CockroachDB usually fixes itself:
- Node failures: Other nodes take over automatically
- Load rebalancing: Moves data around to optimize performance
- Maintenance tasks: Handles compaction and cleanup without downtime
- Rolling upgrades: Can upgrade without taking the cluster down
That said, "self-healing" doesn't mean zero-ops. You'll still get alerts when nodes die and need to understand what's happening.
PostgreSQL Compatibility (Pretty Good, Not Perfect)
CockroachDB wire protocol compatibility means your existing PostgreSQL tools and drivers work. Most common features are supported:
- Standard SQL (the important stuff from ANSI SQL 2016)
- Common data types (JSON, arrays, UUIDs)
- Indexes (B-tree, partial, expression-based)
- Basic stored procedures and functions
- Foreign keys and constraints
- Views and materialized views
The compatibility is good enough that you can often point your app at CockroachDB and it'll work. But you'll find PostgreSQL features that aren't supported, especially the more exotic ones.
Performance Reality Check
CockroachDB is built for OLTP workloads, not analytics. Here's what you actually get:
- Local reads: Sub-millisecond if data is nearby
- Cross-region transactions: 50-100ms if you're lucky, can be higher
- Write latency: 2-10ms because of consensus overhead
- Throughput: Scales linearly as you add nodes (if you design your schema right)
It works best with normalized schemas where related data stays together. If you need heavy analytics, just use something else or stream the data out to a data warehouse.
Licensing and Pricing (The Expensive Part)
Here's the licensing situation as of November 2024:
CockroachDB Enterprise Free: "Free" for companies under $10M revenue, but they get telemetry on everything you do and you need annual renewal. They'll literally know more about your database usage than you do.
CockroachDB Enterprise: The paid version for actual companies. Pricing is "contact sales" which translates to "we'll charge what we think you can afford" based on how desperate you look during negotiations.
CockroachDB Cloud: Fully managed on AWS, Google Cloud, and Azure. Convenient but prepare for sticker shock - you're paying for their ops team plus markup on cloud resources.
The free tier disappears the moment you hit $10M revenue, so plan your business growth carefully. Once you're locked into their ecosystem, they control the pricing and there's no open source escape hatch anymore.