Been running Claude 3.5 Haiku in production since early 2024. Here's what breaks, when it breaks, and what we learned the hard way.
Rate Limits: The Silent Killer
How Token Bucket Works: Think of it like a bucket with holes. Tokens (requests) fill the bucket continuously. When you make requests, tokens drain out. If the bucket empties (burst requests), you wait until more tokens accumulate.
The official docs say you get 50 requests per minute on Tier 1. What they don't tell you is how this actually works. Hit 10 requests in the first 10 seconds? You're probably fine. Hit 50 requests in the first 10 seconds? You're rate limited for the next 50 seconds.
The reality: It's a token bucket algorithm, not a simple counter. Your capacity refills continuously, but burst requests will exhaust it fast. This comprehensive guide covers the technical details better than Anthropic's docs.
Production lesson: We implemented a request queue that spreads requests evenly across each minute. Went from constant 429s to zero rate limit issues:
import asyncio
from datetime import datetime, timedelta
class RequestPacer:
def __init__(self, requests_per_minute=45): # Leave some headroom - learned this the hard way
self.rpm = requests_per_minute
self.last_requests = []
async def wait_if_needed(self):
now = datetime.now()
# Remove requests older than 1 minute
# TODO: this is probably inefficient but it works
self.last_requests = [r for r in self.last_requests
if now - r < timedelta(minutes=1)]
if len(self.last_requests) >= self.rpm:
wait_time = 60 - (now - self.last_requests[0]).total_seconds()
await asyncio.sleep(max(0, wait_time))
self.last_requests.append(now)
The Thinking Bug: Most Annoying Edge Case
Found this the hard way. If you use Claude Code (the CLI tool), certain words trigger automatic routing to Sonnet, which then fails because you configured Haiku.
Words that break everything: "think", "thinking", "thoughts"
Words that work fine: "consider", "believe", "assume", "figure"
This is Claude Code specific, not the API. But if you're building dev tools that integrate with Claude Code, you'll hit this.
Our workaround: Text preprocessing that replaces trigger words before sending to Claude Code:
TRIGGER_REPLACEMENTS = {
"think": "consider",
"thinking": "considering",
"thoughts": "ideas",
"I think": "I believe"
}
def sanitize_for_claude_code(text):
for trigger, replacement in TRIGGER_REPLACEMENTS.items():
text = text.replace(trigger, replacement)
return text
Quality Degradation: The Silent Production Killer
Between August 26 - September 5, 2024, Anthropic confirmed two separate bugs that degraded Haiku output quality. Users reported it for weeks before official acknowledgment. Check the historical incident data to see that outages happen 2-3 times per month averaging 15 minutes to 4 hours each.
What degraded:
- Code suggestions became significantly worse
- Tool use started failing more often
- Responses became more generic and less helpful
How we caught it: Started logging response quality metrics in August:
def log_response_quality(prompt, response):
# This is ugly but it caught the August quality issue
metrics = {
"response_length": len(response),
"has_code_block": "```" in response,
"has_specific_examples": count_specific_examples(response), # TODO: make this smarter
"follows_instructions": rate_instruction_following(prompt, response)
}
# Log to your monitoring system (we use DataDog)
log_metrics("claude_quality", metrics)
When we graphed this data, we saw a clear drop starting around late August. Having historical data made the difference between "feels wrong" and "definitely broken".
Network Issues: The 1-Second Lie
The benchmarks show 0.52 seconds average response time. In production from AWS us-east-1, we see significantly different results. Production monitoring best practices recommend tracking P99 latency instead of averages:
- Best case: around 700-900ms (including TLS handshake)
- Typical: somewhere between 1-2 seconds
- Bad days: 3+ seconds before we give up
Critical for UX: Don't promise sub-second responses to users. Budget 2 seconds for user-facing features and show loading states immediately.
Our monitoring shows latency spikes correlate with:
- Anthropic deploying new models (usually 15-30 minute windows)
- High usage periods (US business hours)
- General AWS networking issues in us-east-1
Error Handling: Beyond the Obvious
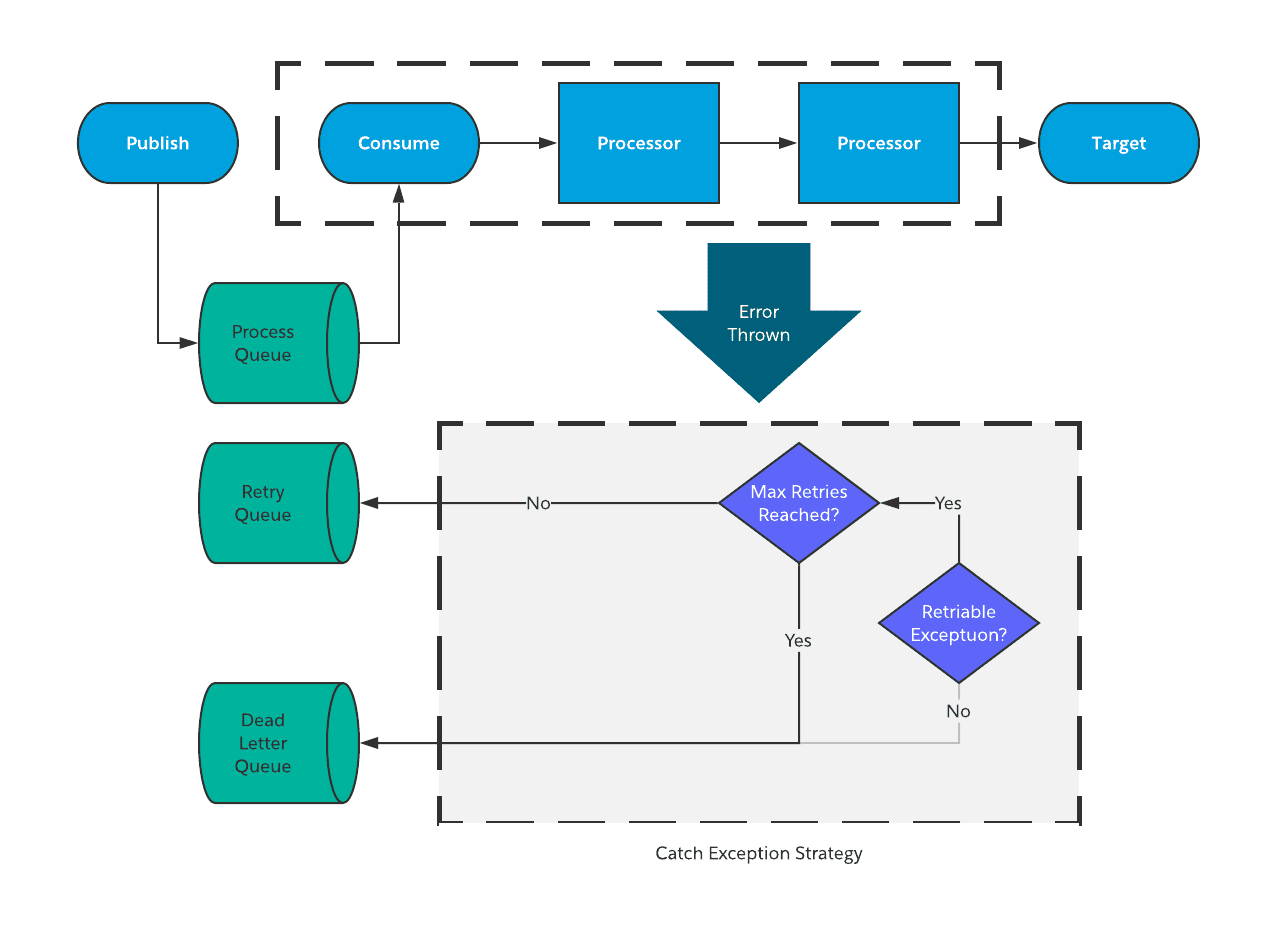
Most guides tell you to catch 429s and 500s. Comprehensive error handling guides cover the basics, but we've seen these production edge cases that aren't documented anywhere:
Empty responses with 200 status: Happens during Anthropic outages. Response body is literally "" but HTTP status is 200. Always check response length.
Malformed JSON in error responses: During some outages, error responses aren't valid JSON. Wrap your JSON parsing:
try:
error_data = json.loads(response.text)
except json.JSONDecodeError:
# Anthropic is having a bad day
error_data = {"error": {"message": response.text}}
Intermittent SSL errors: Happens maybe once per 10,000 requests. Retry once with a fresh connection usually fixes it.
Monitoring That Actually Helps
We track these metrics in production:
- Token usage per hour - catch runaway usage before billing surprises
- Response latency P99 - catch degraded performance early
- Error rate by type - distinguish between our bugs and Anthropic's
- Quality scores - catch degradation like the August incident
- Fallback activation rate - how often we switch to backup models
The metric that saved us: Response similarity to expected outputs. When this drops significantly, something's wrong with the model, not our code. DownDetector is often faster than the official status page for detecting issues. For detailed monitoring strategies, check out API monitoring best practices and production deployment guides.