You know how building AI apps is basically trial and error until something works? Console is Anthropic's attempt to make that less painful. Got a major redesign in February 2025 that actually fixed some shit. The API docs show how teams can move from prototype to production faster.
The Three Things That Don't Break
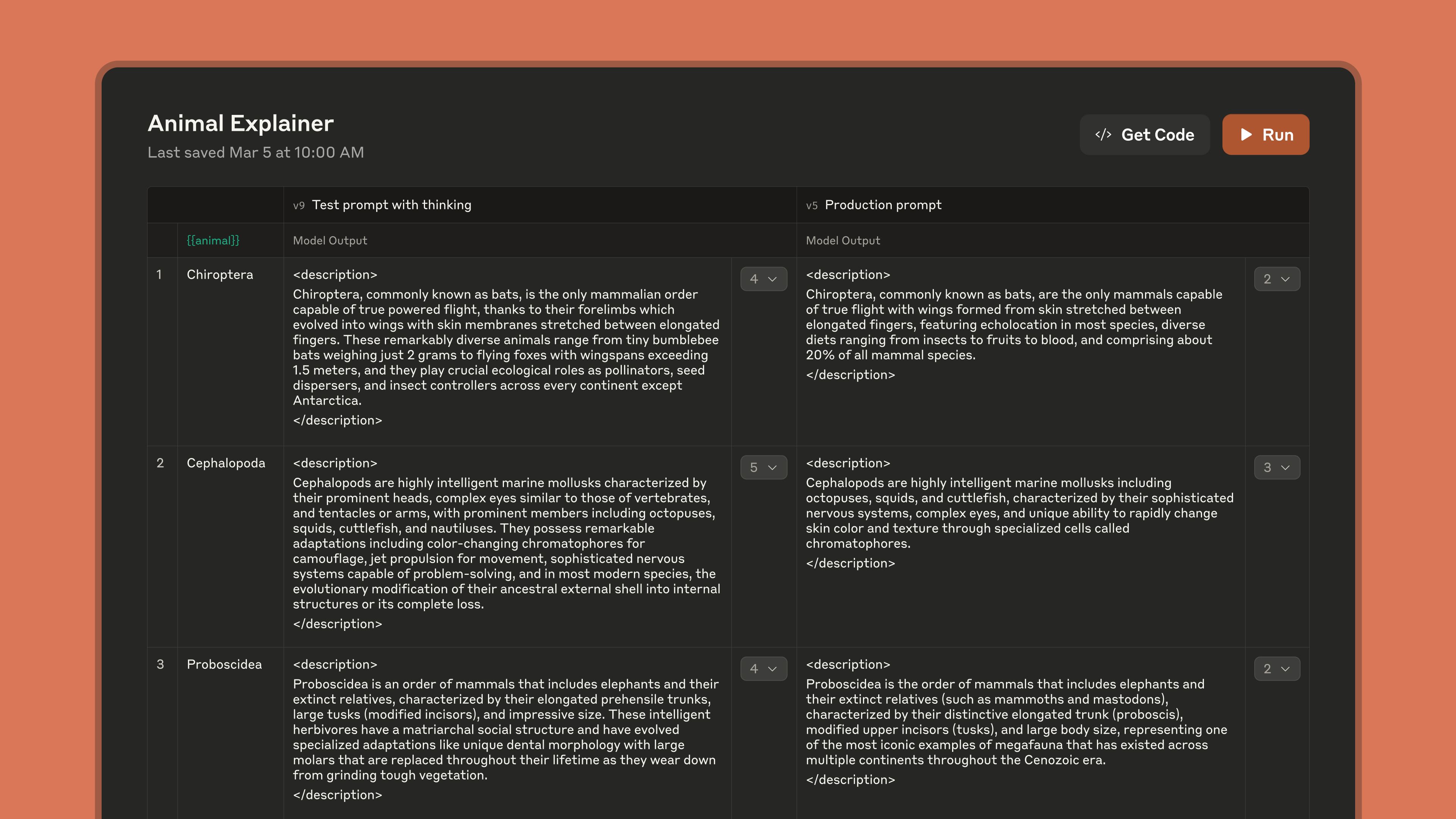
Workbench - This is where you write prompts and test them without setting up API calls. Copy-paste your prompt, hit test, see if Claude gives you garbage. Rinse and repeat until it works.
Shared prompts - Finally, you can stop sending prompts through Slack. Your team can edit the same prompt without accidentally breaking the version that actually works. Version history exists so you can roll back when someone inevitably fucks it up.
Evaluation tools - Test your prompts against multiple inputs at once. Because the prompt that works great on your three test cases will definitely fail on real user data.
Team Collaboration That Doesn't Suck
Before February 2025, sharing prompts meant copying text into Google Docs or hoping your Slack message didn't get buried. Now you can actually collaborate without wanting to throw your laptop out the window.
Your product manager can edit prompts directly instead of writing novels in Jira tickets explaining what they want. Your QA team can test variations without pestering you for API keys. Domain experts can contribute without learning Python.
I've seen teams cut their prompt iteration time from weeks to days just by having everyone work in the same place instead of playing telephone with requirements. Turns out when your PM can actually edit prompts directly instead of writing novels in Jira, shit gets done faster.
Extended Thinking: When Claude Actually Thinks
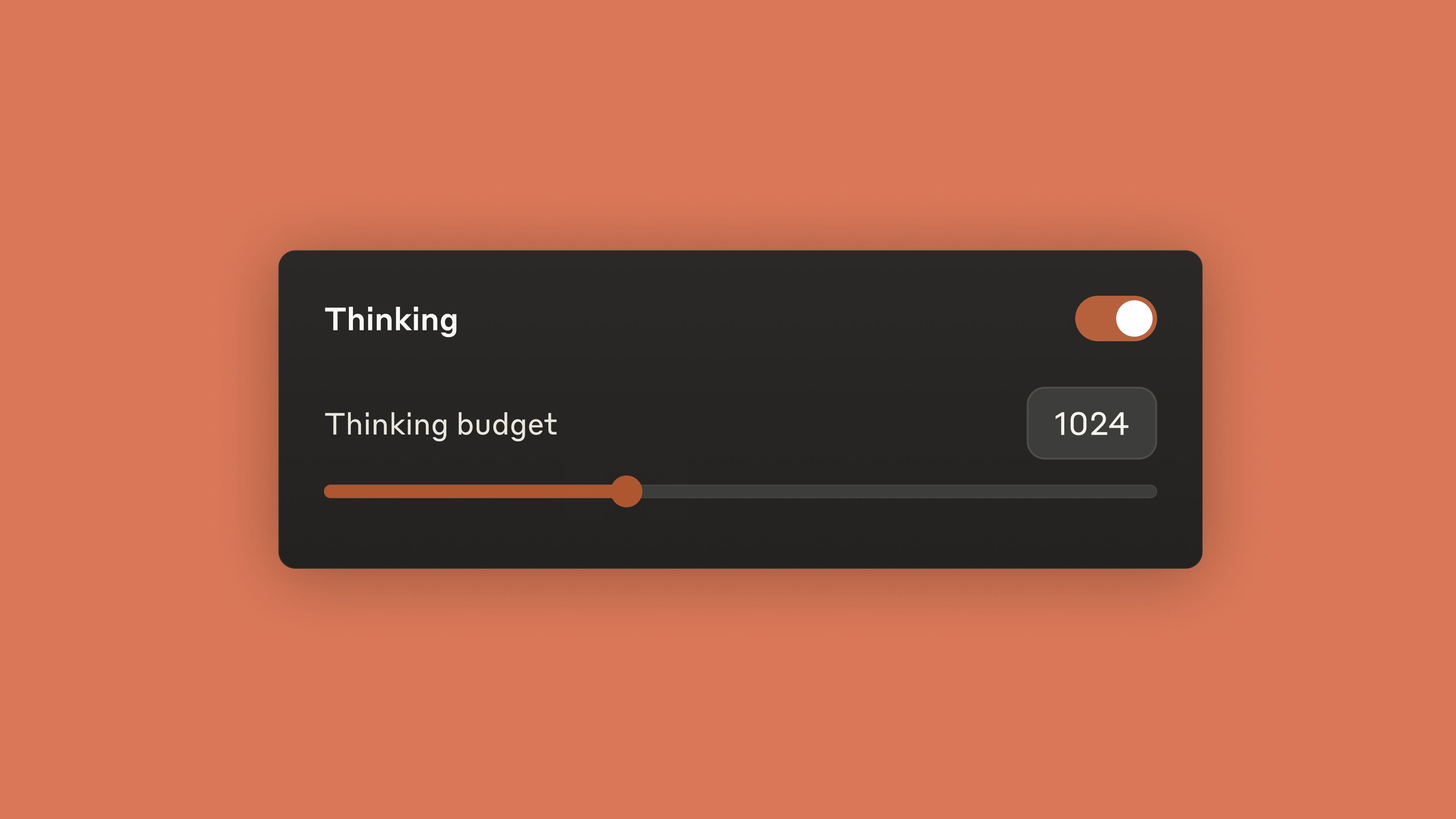
Claude Sonnet 4 (released May 2025) has this "extended thinking" feature where it shows its work. Like when you told teachers to show your math, except the AI actually does it.
You can set a "thinking budget" - basically how many tokens Claude can use to think before responding. More tokens = deeper thinking = higher cost. The Console lets you experiment with this so you don't accidentally blow your API budget on one complex prompt.
For real-time chat? Keep thinking budget low. For analyzing legal documents? Crank it up and wait for the better answer. Console helps you figure out the right balance without guessing. Set it too low and you get shallow answers. Set it too high and your $50 test prompt becomes a $500 test prompt.
The "Get Code" Button Actually Works
Here's the thing that convinced me this isn't just another AI tool playground: when your prompt finally works, you click "Get Code" and it gives you production-ready API calls. Not pseudocode. Not "implement this yourself." Actual working code.
The generated code includes error handling, proper authentication, and parameter validation. I've shipped API integrations using code straight from Console with minimal modifications.
This eliminates the usual gap between "it works in the demo" and "it works in production." No more re-implementing everything from scratch because your prototype used a different API structure.