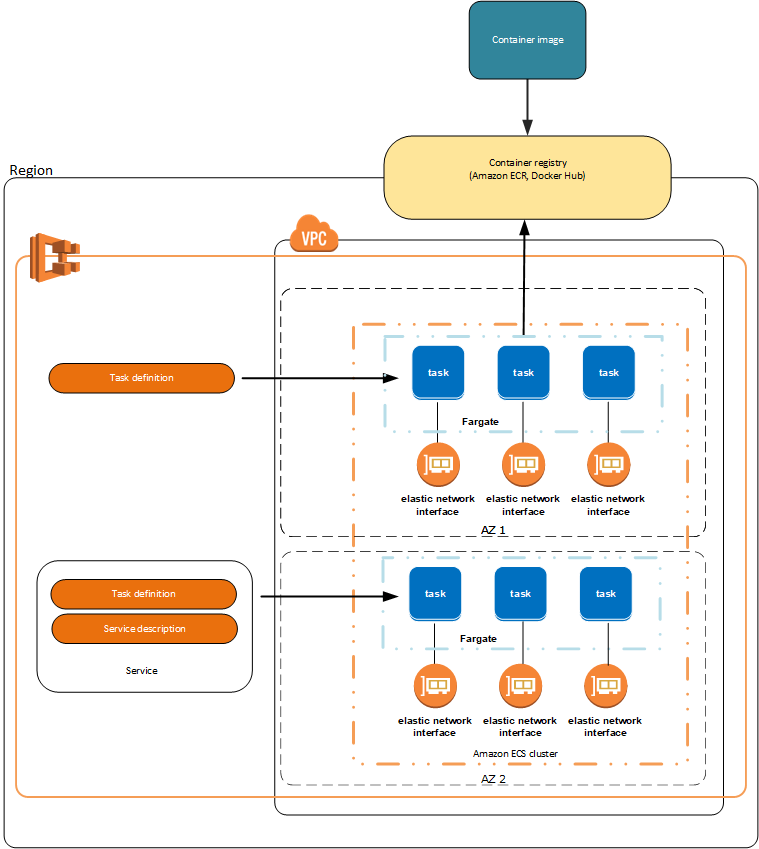
Amazon ECS is AWS's attempt to make running Docker containers less of a pain in the ass. Instead of manually provisioning EC2 instances, installing Docker, configuring clustering, and then crying when everything breaks at 3 AM, ECS handles the infrastructure bits while you deal with your actual application.
Here's what Amazon won't tell you: ECS is for teams who want to ship code, not become infrastructure experts. You're already paying AWS for RDS and S3, so why not let them handle container orchestration too? It's Docker management for people with deadlines.
How ECS Actually Works (The Good and Bad)
ECS has three main pieces that you need to understand:
Control Plane: AWS runs the brain that decides where your containers go and monitors if they're still alive. This is actually pretty nice because you don't have to maintain master nodes or deal with etcd corruption. The downside? You're locked into AWS's way of doing things, so good luck if you ever want to migrate.
Data Plane: Where your containers actually run. You've got three options: EC2 instances (you manage the servers), Fargate (AWS manages everything), or ECS Managed Instances (hybrid approach that launched September 2025). Each has its own special way of making your life difficult.
Task Definitions: JSON files that describe your containers. Think Docker Compose but more verbose and with AWS-specific nonsense sprinkled in. You'll spend hours tweaking CPU and memory limits when your container dies with exit code 137. Task definition docs have all the gory details.
Launch Types (Pick Your Poison)
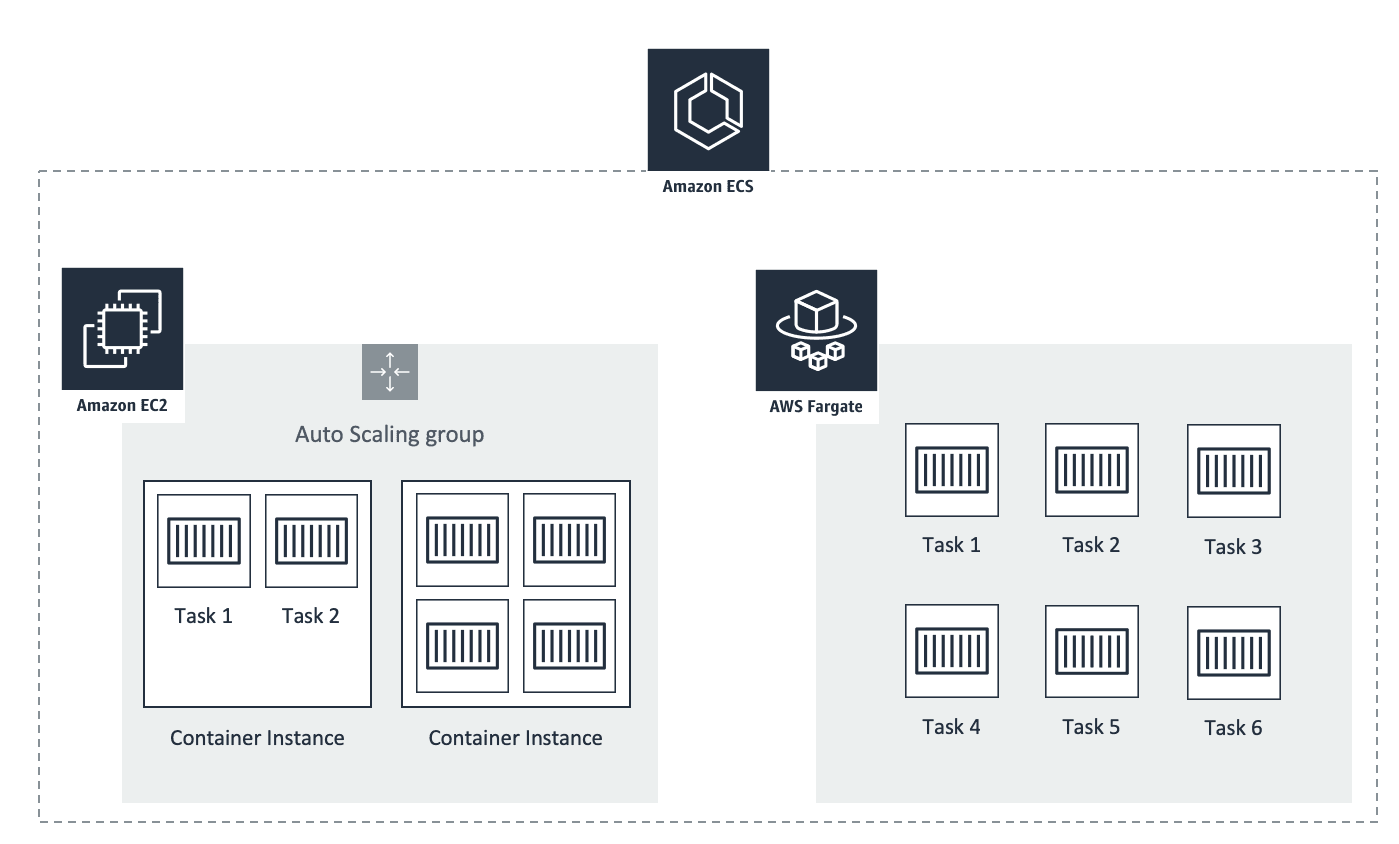
You get three ways to run containers in ECS, each with its own unique way to fuck up your day:
Fargate: AWS handles everything, you just pay through the nose. At around 4 cents per vCPU-hour, it's expensive but eliminates the "why did my EC2 instance randomly die" conversations. Fargate tasks take 1-3 minutes to start, which feels like forever when you're watching ResourcesNotReady errors during a production incident. Also, if you need anything that requires host-level access, you're fucked.
EC2 Launch Type: You manage the EC2 instances, ECS just schedules containers on them. Cheaper if you're smart about Reserved Instances and Spot, but now you're back to babysitting servers. Fun fact: when an EC2 instance dies, all containers on it die too. Hope your app handles that gracefully.
ECS Managed Instances: The new kid on the block (launched September 30, 2025). AWS promises to handle patching and scaling while giving you EC2 flexibility. Sounds great in theory, but it's so new that you'll be the beta tester. Pricing isn't public yet, but expect it to cost more than plain EC2.
The AWS Lock-in (Blessing and Curse)

ECS plays really nice with other AWS services, which is great until you want to leave:
Security: IAM integration means you can lock down containers without learning a new auth system. Each task can have its own IAM role, which is genuinely useful. Just don't give every container Administrator access because you got tired of debugging permissions. GuardDuty will yell at you if something fishy happens, though it's another monthly charge.
Networking: Each Fargate task gets its own ENI, so you can apply security groups directly to containers. This is nice until you hit ENI limits and your deployments fail with ENI provisioning failed errors. I learned this when trying to deploy 200 containers and wondering why only 50 started. Service Connect is AWS's attempt at service mesh without the complexity tax.
Monitoring: CloudWatch integration is decent for basic stuff, but you'll probably want to ship logs somewhere else for serious analysis. Container Insights costs extra but gives you container-level metrics that actually help debug why your API is slow.
When ECS Makes Sense
ECS is perfect if you're already married to AWS and want containers without the Kubernetes learning curve. It's less good if you value portability or need advanced scheduling features. For deployments, just use rolling updates unless you have a specific reason not to. Blue/green is overkill for most use cases.
But knowing the basics isn't enough. Let's talk about what happens when you actually try to run this thing in production.