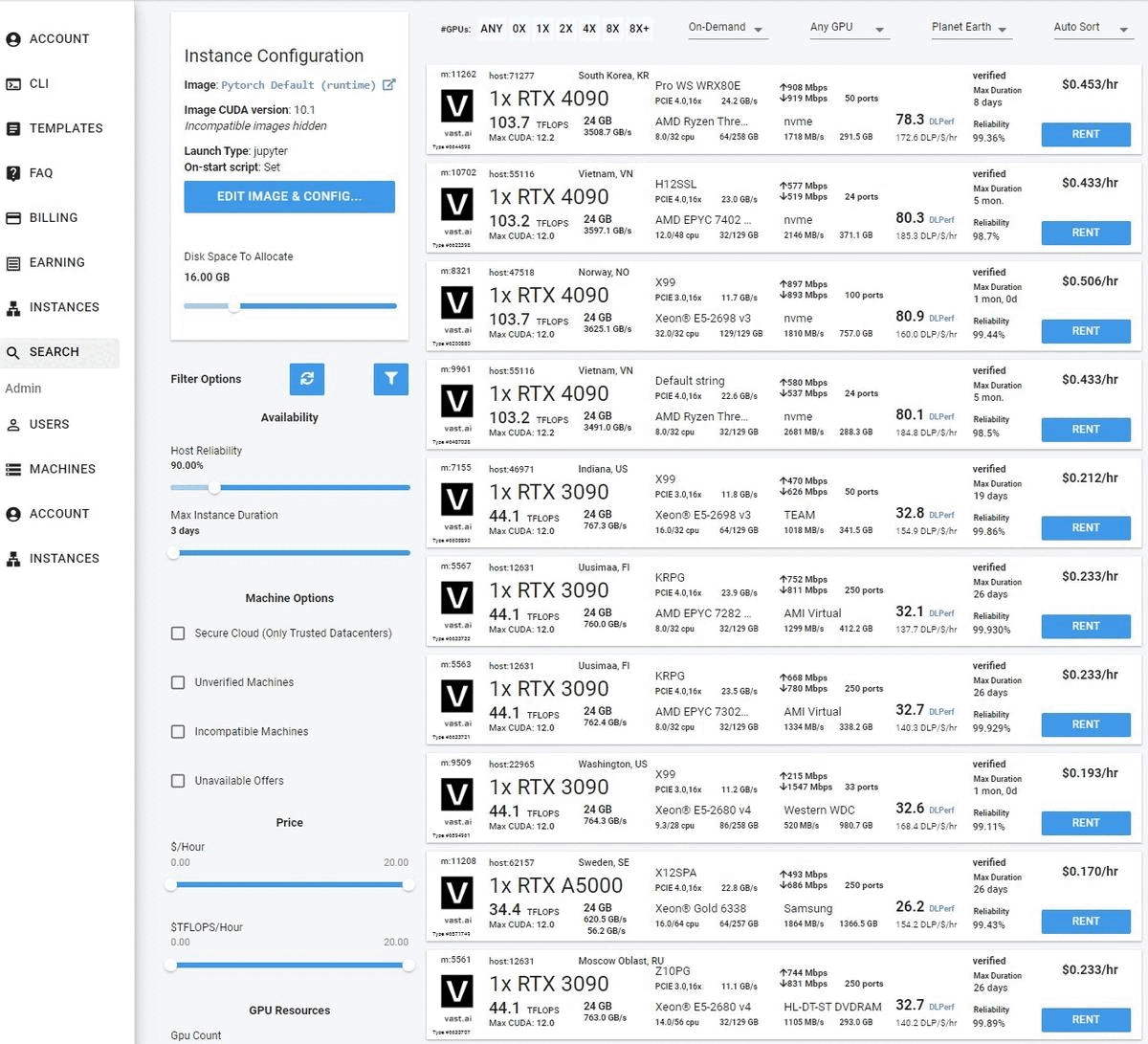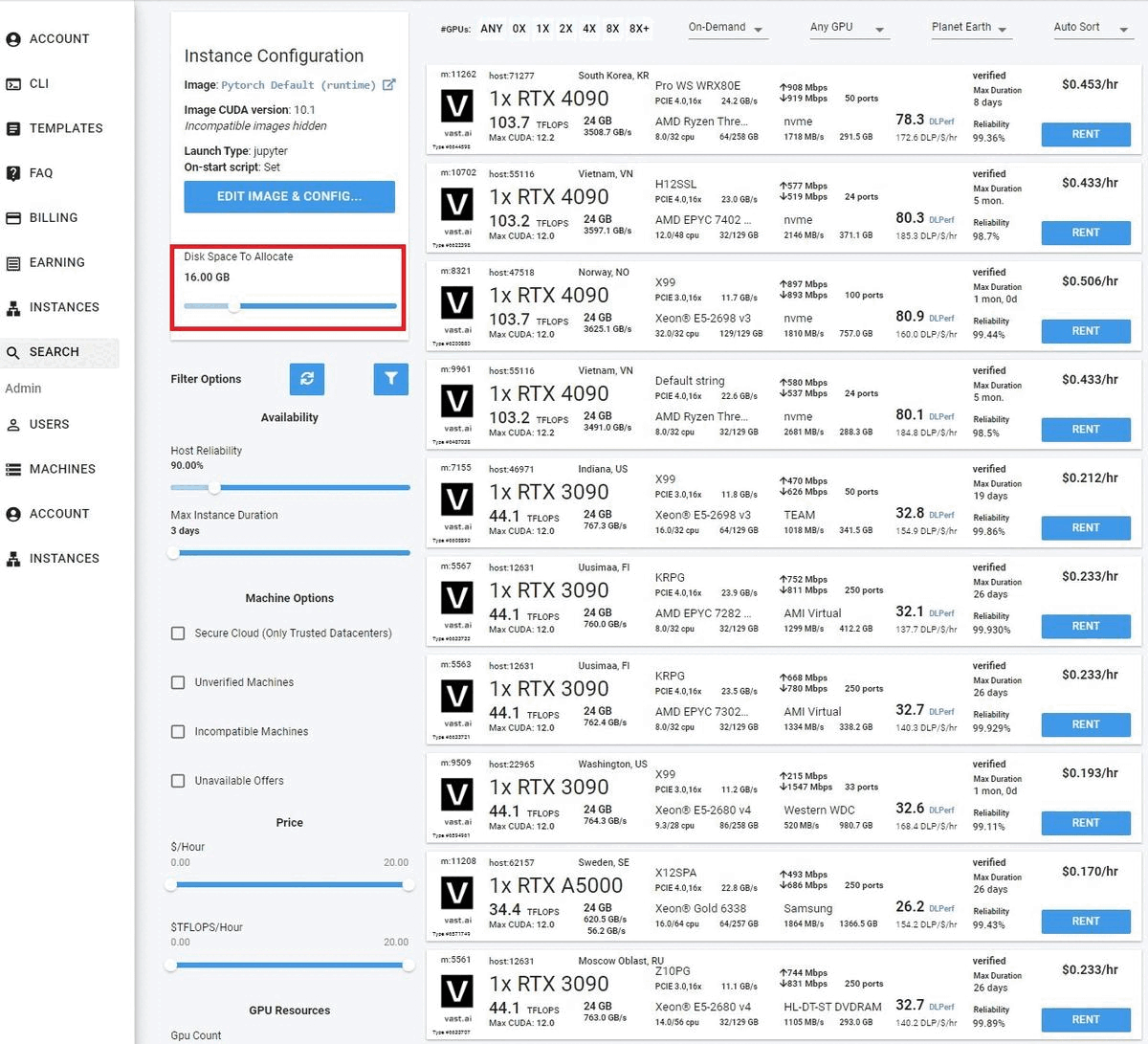
Vast.ai is a GPU rental marketplace where crypto miners, gamers, and random people with expensive graphics cards rent them out to make money. Instead of AWS owning all their hardware, you're renting some dude's RTX 4090 in his basement - which is why it's dirt cheap and occasionally unreliable as hell.
The Marketplace Reality
Here's how it actually works: People install Vast's host software on their machines, set whatever prices they want, and hope someone rents their GPU. You browse their listings like Craigslist, except for compute power instead of used furniture. When you find a machine that looks decent, you pray it actually works and launch a Docker container.
The whole thing runs on supply and demand. When everyone wants H100s for training, prices spike. When crypto crashes and miners need to pay rent, prices plummet. I've seen A100s go from $0.80/hour to $3.00/hour in the same day depending on who's trying to train what.
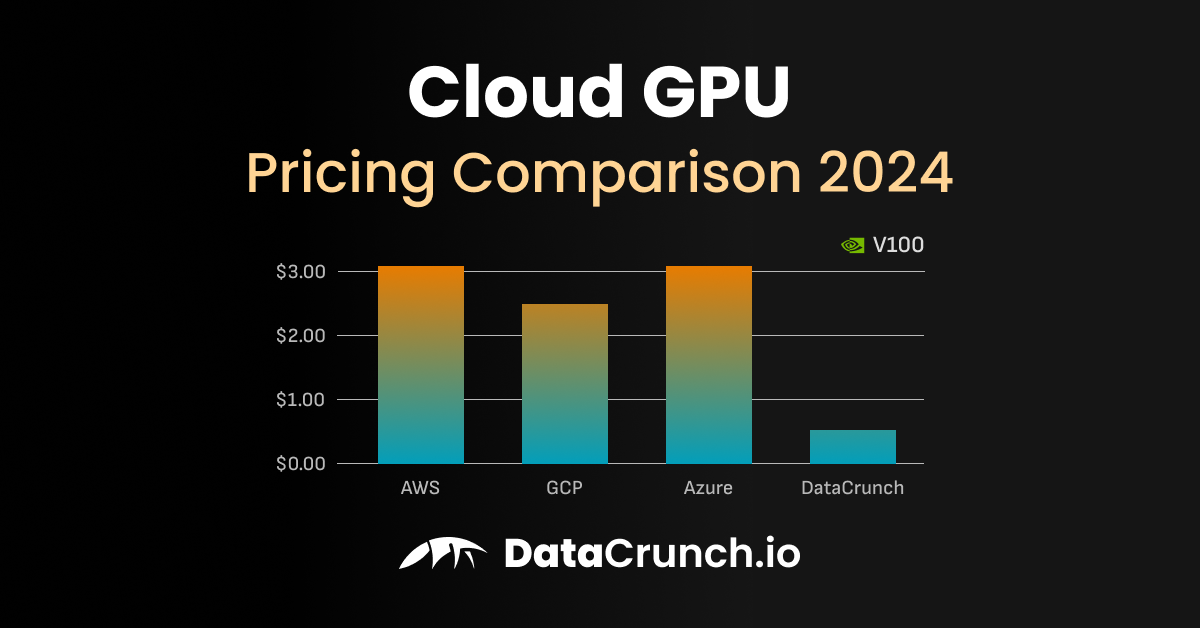
Pro tip: Set price alerts because GPU prices fluctuate like cryptocurrency.
Three Ways to Get Screwed by Pricing
On-Demand Instances are supposed to be "guaranteed" but cost the most. They won't get interrupted by higher bidders, but the host can still randomly reboot their machine or lose internet connection. It's the most reliable option on a platform where reliability is relative.
Interruptible Instances are where you bid against other users like some dystopian GPU auction. Bid too low and your training job gets paused every 10 minutes. Bid too high and you're paying on-demand prices anyway. The sweet spot changes hourly and nobody tells you what it is.
Reserved Instances lock you into paying for hardware that might die tomorrow. Great discount if the host keeps their machine online for months. Terrible deal when their mining rig catches fire after week 2.
Security (or Lack Thereof)
You're literally running code on stranger's computers, so yeah, security is interesting. Vast.ai tries to verify hosts and track reliability, but "verified" just means the machine responded to a ping test, not that it won't suddenly disappear.
The Docker isolation is solid - you can't access the host's files or other users' containers. But if you're training on sensitive data, remember that your models are sitting on some random person's SSD. Enterprise customers get dedicated clusters that are basically fancy ways of avoiding the guy mining Dogecoin between your training runs.