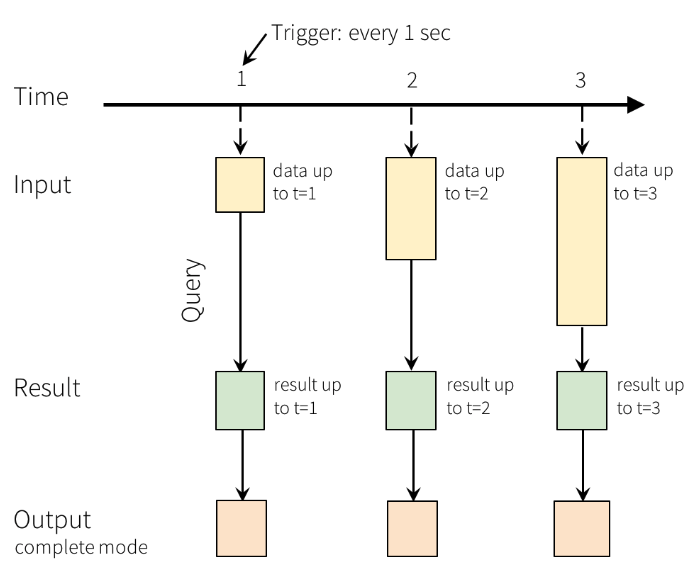
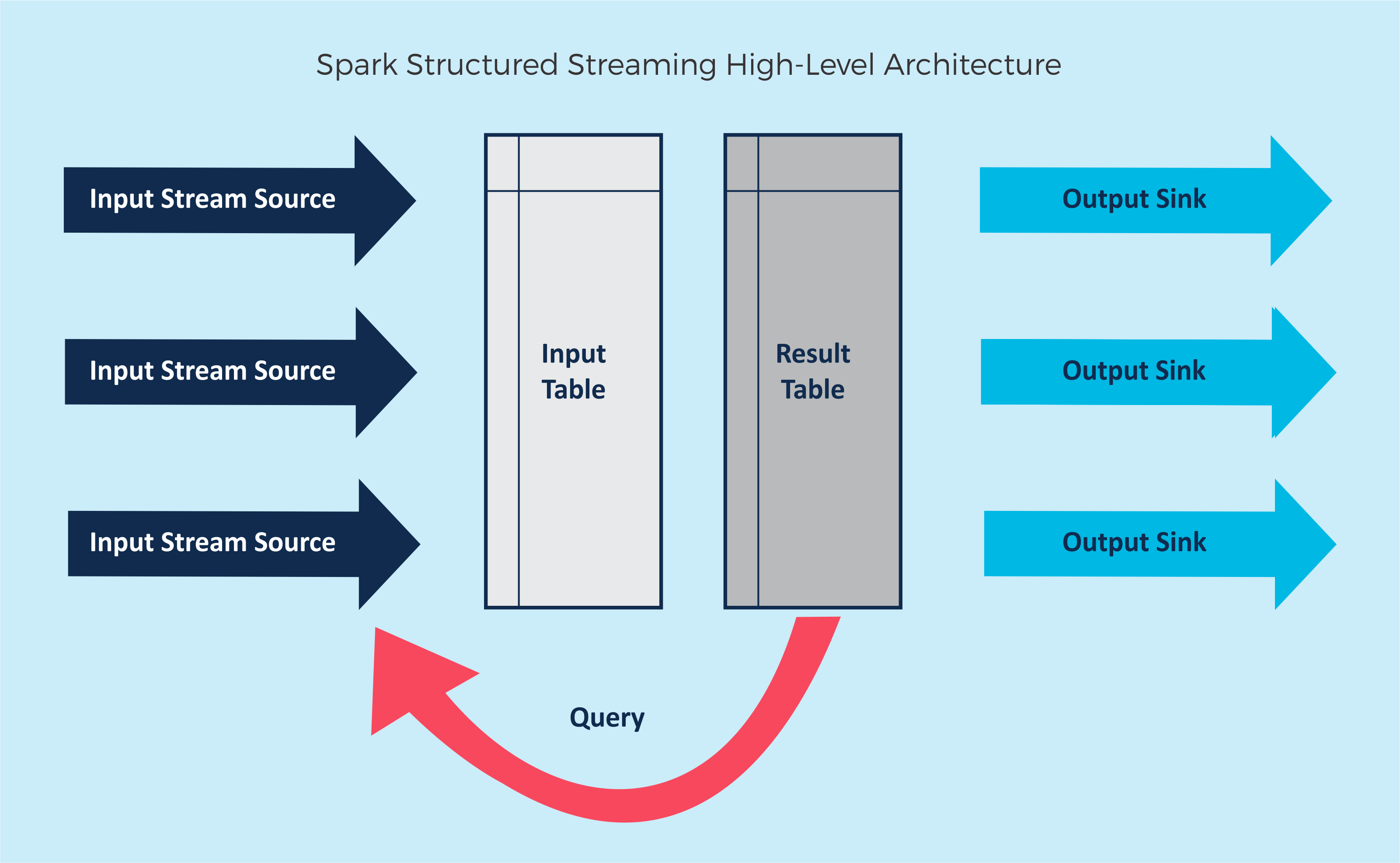
So you're considering Spark Streaming. Smart - it's one of the few tools that actually delivers on the "unified batch and streaming" promise. But before you dive in, let's talk about what you're really signing up for.
Spark Streaming is Apache's attempt to make you not choose between batch and stream processing. Write your data logic once, run it on both. Sounds great on paper - reality is more complex.
Nobody mentions: it'll eat more memory than you expect, throw OutOfMemoryErrors when you least expect it, and you'll spend your first month figuring out why your "real-time" job takes 30 seconds to process 1 second of data.
DStreams: The Legacy Disaster
DStreams was Spark's first attempt at streaming. It worked, sort of, but had fundamental issues. Apache basically said "fuck it, we're not fixing this anymore" and moved to Structured Streaming. If you're still using DStreams in 2025, you're doing it wrong.
The main problem: DStreams pretended streaming was just tiny batch jobs. This worked until your data arrived out of order, duplicated, or faster than you could process it. Then you'd get memory leaks, inconsistent results, and a lot of 3am debugging sessions.
Structured Streaming: The Do-Over That Works
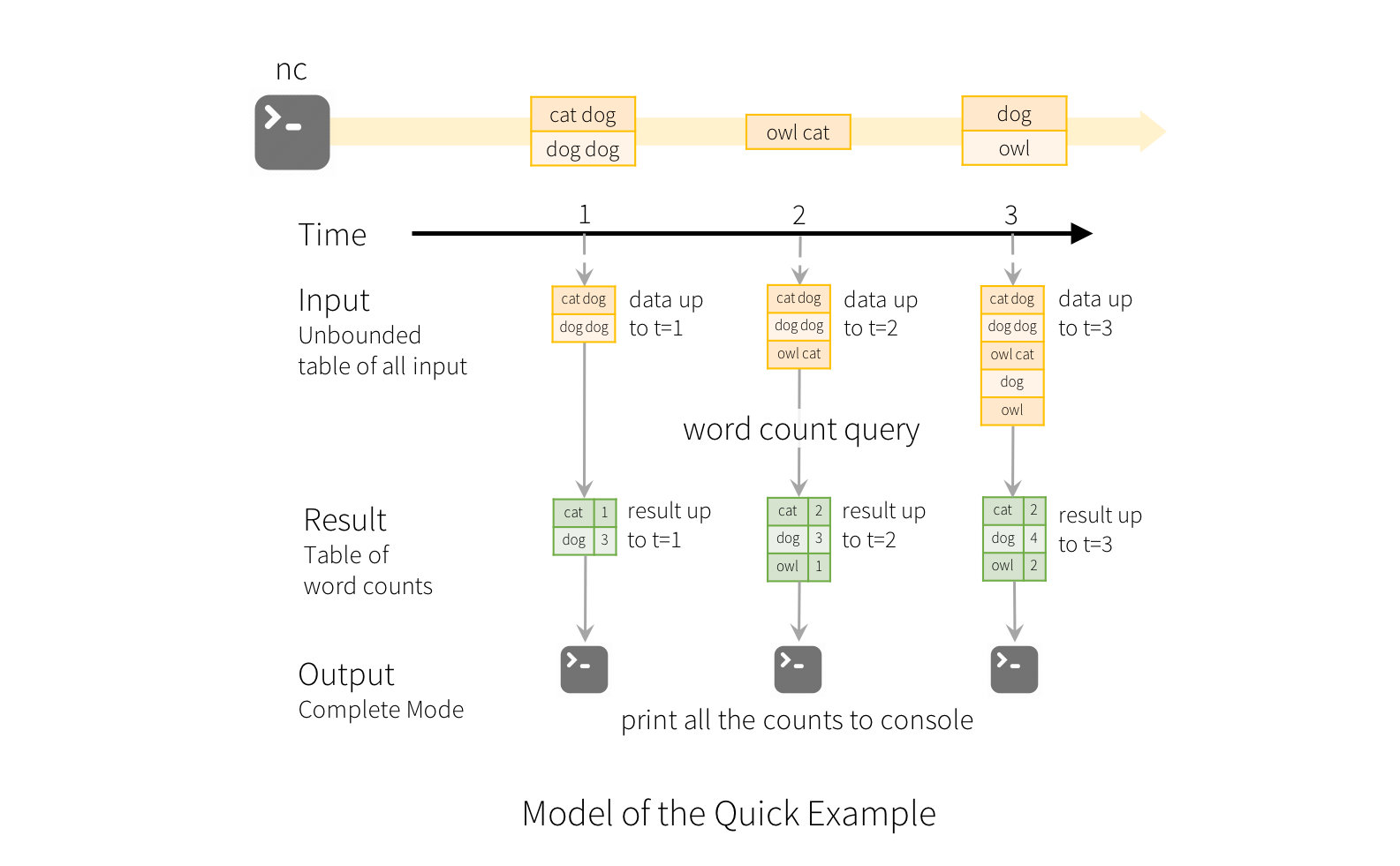
Structured Streaming is Apache's second attempt, and it's actually pretty good. Built on Spark SQL (which is solid), it treats streams as "unbounded tables" - fancy words for "SQL queries on moving data."
Key improvements over DStreams:
- Exactly-once processing that actually works (most of the time)
- Schema evolution so you don't break everything when someone adds a field
- Watermarking to handle late data without filling up all your RAM
- Better error messages that occasionally help you fix things
But here's the catch: migrating from DStreams to Structured Streaming isn't just changing APIs. The mental model is completely different. Plan for a full rewrite.
Real-Time Mode: Marketing vs Reality
Databricks launched Real-Time Mode in August 2025, claiming "single-digit millisecond latencies." Their demo videos look great. Production reality will be different.
In production? You'll get 10-100ms latency if you're lucky. Still pretty good, but not the marketing numbers. Reality check: if you need actual sub-millisecond latency, use something else.
Memory: The Hidden Cost
Here's what the docs don't emphasize enough: Spark Streaming is hungry. Really hungry. Budget for 3-5x your data size in memory, plus overhead for Spark's internal structures.
Common memory killers:
- State that grows forever because you forgot watermarking
- Small files problem writing thousands of tiny Parquet files
- GC pauses that make your streaming job stutter like a 1990s video
- Driver memory issues when collecting too much data
Spark 4.0: Actually Good Improvements
Apache Spark 4.0 dropped in May 2025 with some solid streaming improvements. The Arbitrary State API v2 is genuinely useful - better state debugging and schema evolution.
Performance improvements are real too - I've seen noticeable latency reductions in production workloads with proper tuning. Your mileage will vary based on your specific use case, but the optimizations actually help.
Production Reality Check
Companies like Netflix use Spark Streaming successfully, but they have teams of engineers tuning it. For the rest of us:
- Expect 2-3 months of tuning before production-ready
- Production considerations are extensive
- Memory issues will bite you repeatedly
- Best practices exist but learning them takes time
Bottom line: Spark Streaming works well when you accept its complexity and resource requirements. It's not the easiest streaming engine, but it handles scale better than most alternatives and integrates with the broader Spark ecosystem. Just don't expect it to be simple.
The dirty truth? Most teams underestimate the operational overhead by 3-5x. You'll need dedicated engineers who understand distributed systems, JVM tuning, and can debug Catalyst query plans. But if you have that expertise and the infrastructure budget, Spark Streaming can handle production workloads that would break simpler tools.
But wait - should you even use Spark Streaming? That depends entirely on your alternatives and specific use case. Here's how it actually stacks up against other streaming platforms.