The Model Context Protocol is trying to be the USB-C of AI - whether it actually works is another story. MCP solves the "M×N explosion problem" where every AI tool needs custom integration with every data source. Instead of building 47 different connectors, you set up one MCP server that (theoretically) works with all compatible tools. Microsoft's MCP curriculum provides a structured learning path with real-world examples across multiple programming languages.
The Real Problem: AI Tools Forget Everything
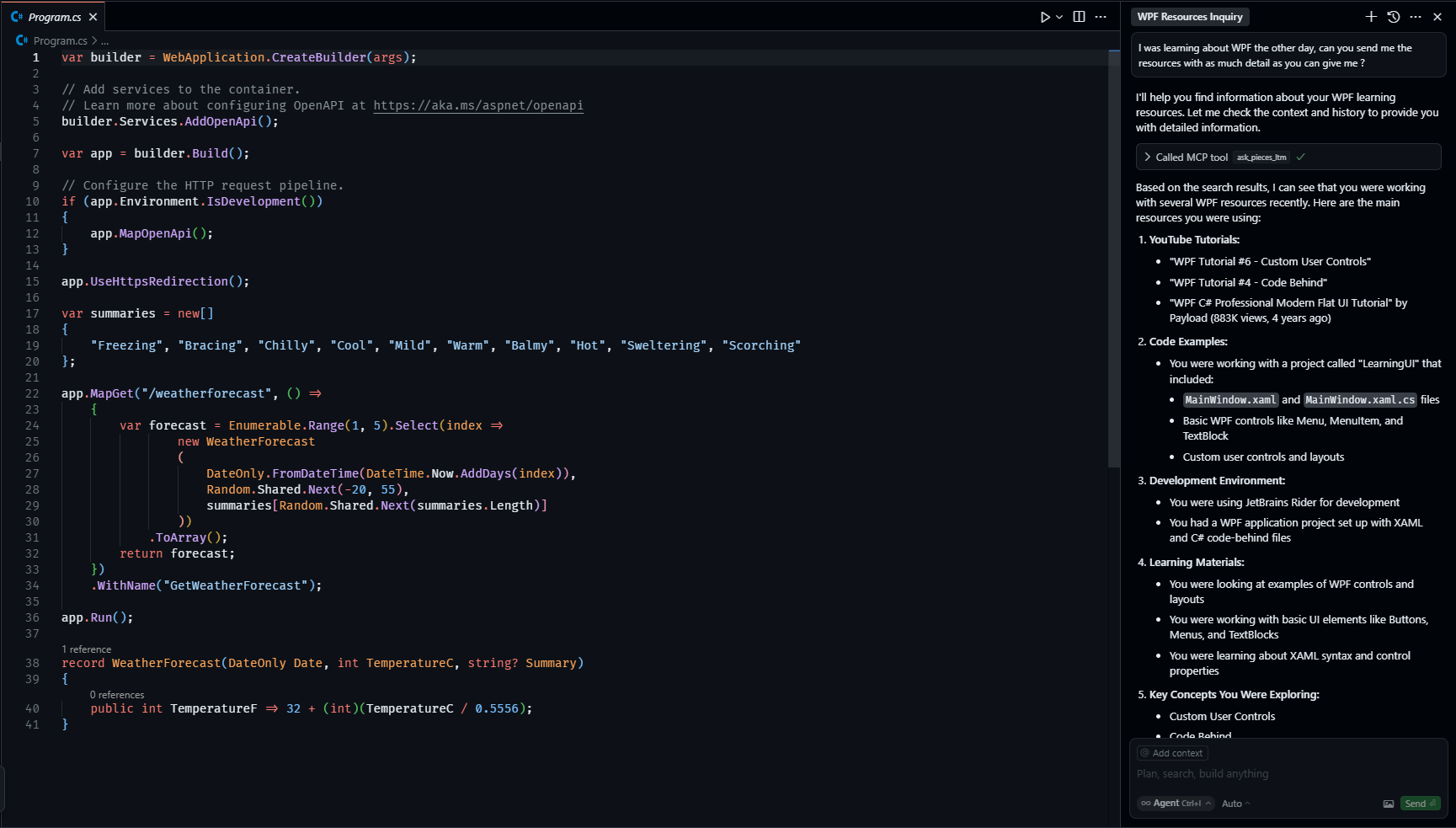
Every developer knows this pain: You open GitHub Copilot, explain your entire project architecture, get decent suggestions, then close the tab. Next day? Blank slate. You're explaining the same auth patterns, database schemas, and architectural decisions like it's Groundhog Day but for code. Comprehensive analysis of AI coding assistants shows this context loss is a universal problem across all major platforms.
Pieces MCP tries to fix this by making AI tools remember your actual work:
- "That JWT implementation from last month's auth refactor" - It remembers which approach you used and why
- "Use the error handling pattern from the user service" - References your actual patterns, not generic examples
- "The database schema we finalized in that 3-hour meeting" - Pulls from actual team discussions
How This Actually Works (When It Works)
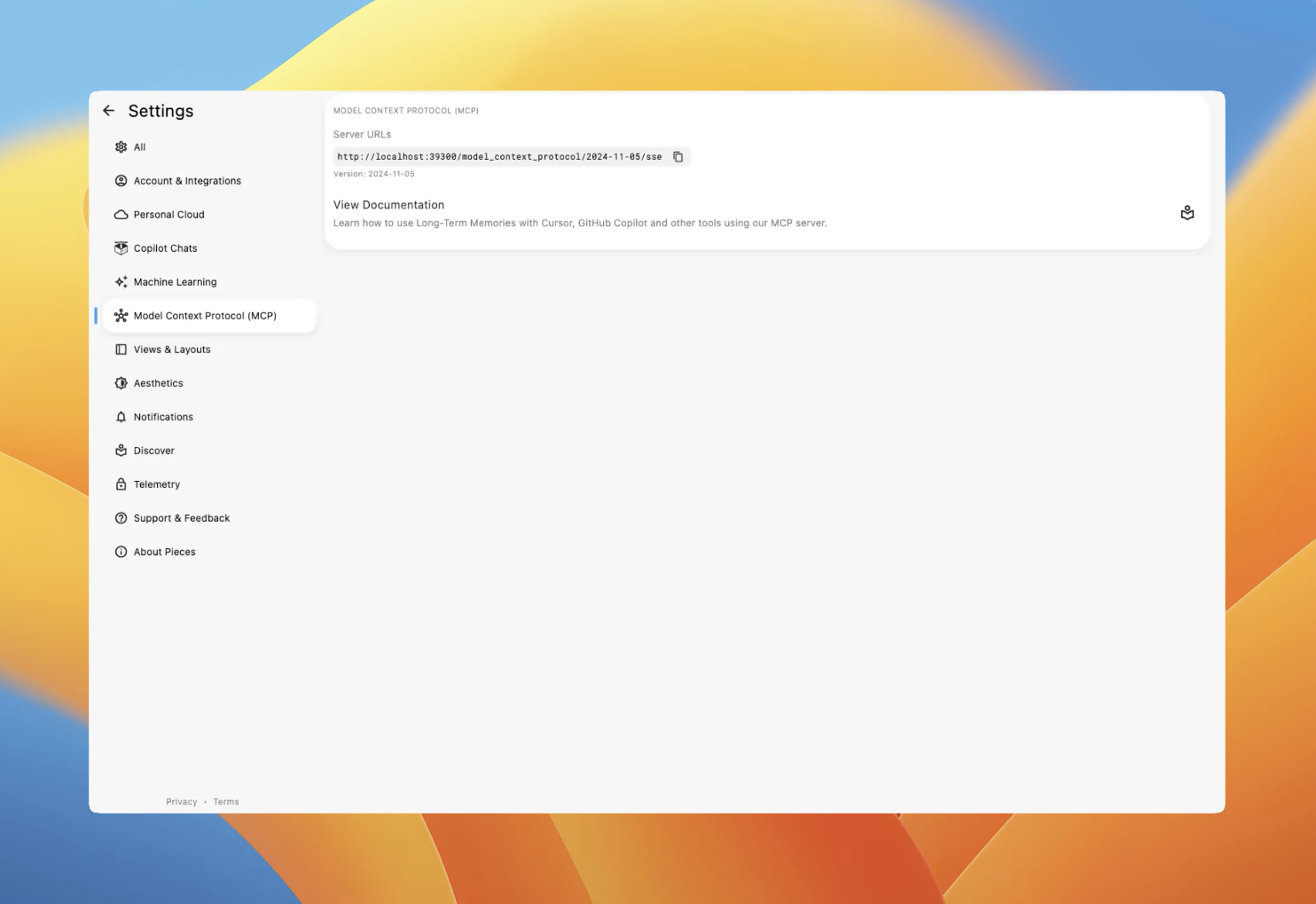
Under the hood, it uses Server-Sent Events (SSE) instead of normal REST APIs. Your AI tool talks to the local Pieces server through MCP and gets context back in ~100-200ms when the stars align properly. MCP tutorial guides dive into the technical details if you're into that sort of masochism.
SSE sounds fancy but half the tools don't support it properly. You'll spend time debugging endpoint URLs that change randomly and nobody tells you. The connection breaks for mysterious reasons and you'll be restarting things more than you'd like. Comprehensive MCP examples showcase various server implementations and their transport method trade-offs.
Long-Term Memory: Your Code Packrat
Pieces' Long-Term Memory engine hoards 9 months of your coding history like a digital pack rat. The LTM-2 system represents a new approach to persistent AI memory in development workflows:
- Code snippets with actual source attribution (not just "from the internet")
- Browser history from all that documentation you actually read
- Meeting notes where you made architectural decisions
- Git commits and their context
- Stack Overflow answers that actually worked
Sometimes it finds exactly what you need. Sometimes it gives you irrelevant garbage from last year's project. The semantic understanding works about 70% of the time - when it works, it's pretty useful. When it doesn't, you're back to manual searching. Developer experiences with Pieces highlight both the potential and limitations of AI memory systems.
Local Processing: Your Laptop Becomes a Space Heater
Pieces MCP runs locally which sounds great until you realize what that actually means. Local vs cloud AI assistant comparison shows the performance trade-offs involved:
- Your laptop fans sound like a Boeing 747 during context analysis
- 16GB RAM minimum or your machine will hate you
- Works offline which is actually pretty nice
- Your code stays put unless you turn on cloud sync
- No network latency for context queries
The tradeoff is fucking brutal. Local AI processing turns your laptop into a space heater and you'll be waiting around for context indexing like it's 2005 again. Initial repo scanning? Plan for 2-6 hours on large codebases. I hope you like the sound of jet engines. Performance comparisons show this is the price you pay for keeping your code local.
What Actually Changes (If You Get It Working)
Old workflow:
- Open AI tool
- Explain your entire project again
- Get generic suggestions
- Curse when it suggests React patterns for your Python app
- Repeat tomorrow
MCP workflow:
- Open AI tool
- Reference specific past work by name
- Get suggestions that match your actual coding style
- AI remembers this conversation for next time
- Still occasionally suggests irrelevant crap, but less often
The difference is noticeable when it works. One developer mentioned "no longer googling the same Stack Overflow answer for the 47th time" - the AI tools actually remember solutions and why you chose them. Practical MCP implementation guides show real-world usage patterns and productivity improvements.
Team Features: Shared Memory or Shared Confusion
Team plans let you share context, which sounds great until you realize the AI can now reference Steve's awful code from 3 months ago. New devs get answers about "why we built it this way" without bugging everyone, but they'll also get suggestions based on whoever wrote that nightmare function nobody wants to touch. Enterprise security guides help you figure out who should see what.
The auth system gives you control over who sees what, but getting it right takes actual effort. Security teams love the local-first approach, then spend weeks figuring out the access controls. Privacy frameworks help you evaluate what matters for your specific paranoia level.
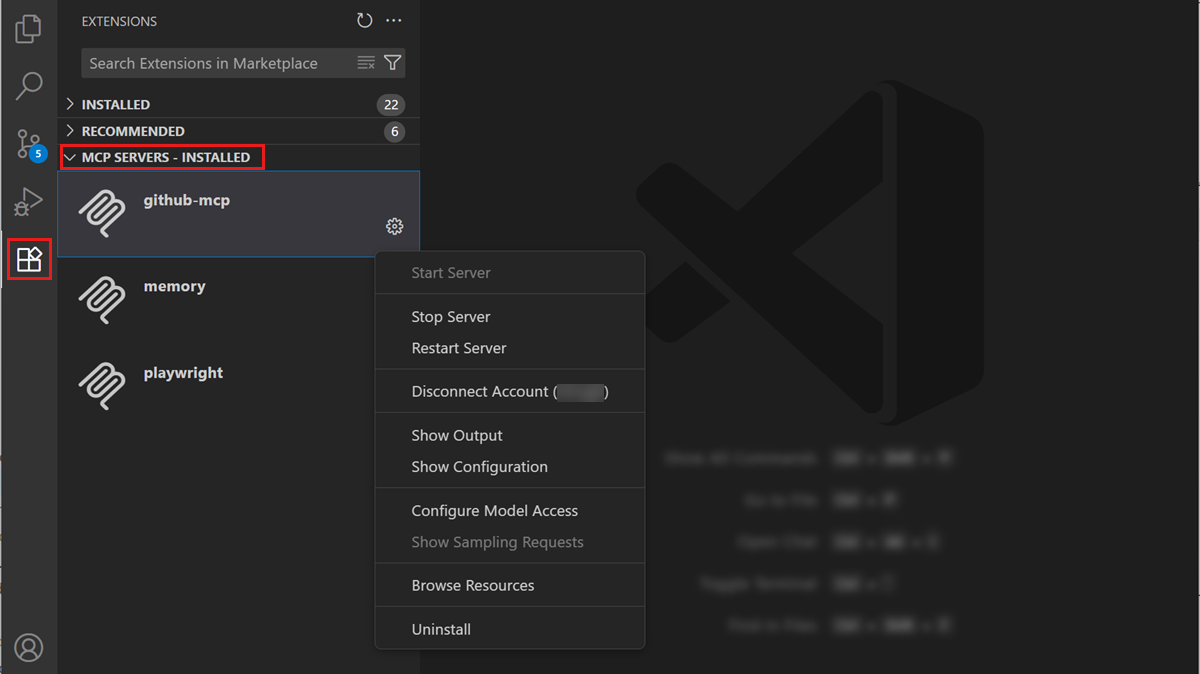
 You're probably in Ask mode instead of Agent mode.
You're probably in Ask mode instead of Agent mode.