The Problem Every AI Team Hits
You know the drill: build a massive GPU cluster, everything's working great, then you max out the power grid. Or run out of rack space. Or both. Happened to us at a previous job - 3 months debugging why our LLM training kept timing out, only to realize we'd hit the facility's 20MW limit.
Building another data center seems obvious until you try running distributed training across facilities. The latency between sites turns your A100s into expensive paperweights. We tried connecting our Virginia and Texas data centers for a GPT model - training time went from 3 days to 3 weeks.
Scale-Across: The Fix Nobody Saw Coming
NVIDIA announced Spectrum-XGS Ethernet at Hot Chips 2025, calling it "scale-across" - the third way to handle compute after scale-up (bigger boxes) and scale-out (more boxes). Now you can scale-across: distant boxes that act local.
This isn't marketing bullshit. The core innovation is auto-adjusted distance congestion control that dynamically optimizes traffic flow based on how far apart your data centers are. Instead of treating all network connections the same, Spectrum-XGS recognizes "oh shit, these GPUs are 2000 miles apart" and adjusts algorithms accordingly.
The Technical Shit That Actually Matters
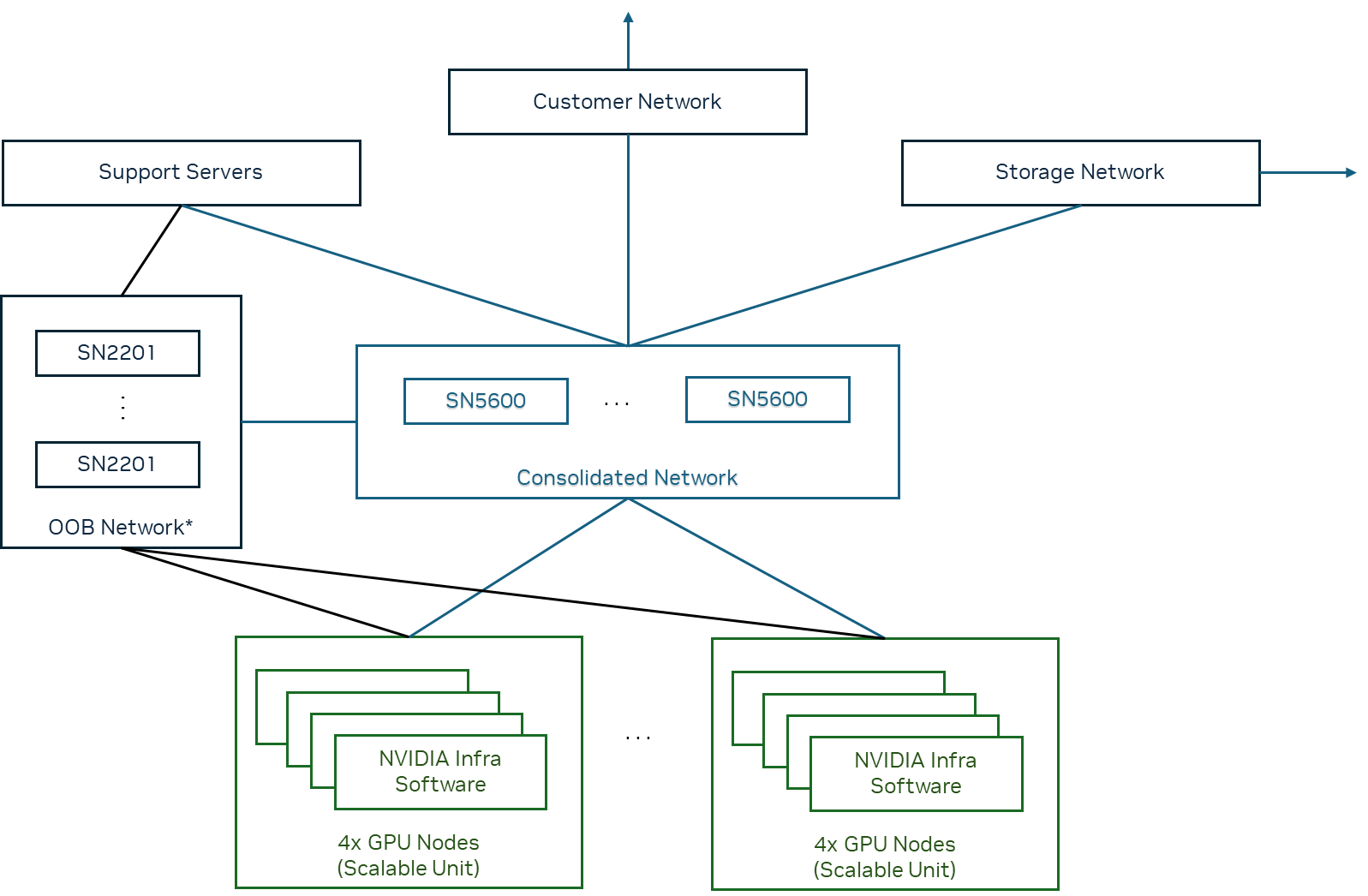
Here's what Spectrum-XGS actually does differently:
- Auto-adjusted distance congestion control - It knows when GPUs are 50ms apart vs 500ms apart and adjusts packet flows accordingly
- Precision latency management - Keeps timing consistent even when some nodes are in Tokyo and others in Frankfurt
- End-to-end telemetry - Actually useful monitoring that shows you which link is fucking up your gradient sync
- 2x better NCCL performance - Those collective operations that crawl over WAN? They actually work now
This isn't just throwing more bandwidth at the problem. Standard NCCL assumes low-latency connections between nodes. When you stretch that across continents, AllReduce operations turn into a shitshow. Spectrum-XGS rewrites the networking stack specifically for AI workloads that need to sync gradients across geographic distances.
The core breakthrough lies in how NVIDIA's networking algorithms handle distributed collective communications. Unlike traditional Ethernet which treats all packets equally, Spectrum-XGS implements topology-aware routing that understands geographical network topology and adjusts bandwidth allocation dynamically.
Real example: our colleague tried distributed training across AWS regions last year. 8 V100s in us-east-1, 8 more in eu-west-1. Standard setup maxed out at 15% GPU utilization because the nodes spent 85% of their time waiting for gradient synchronization. Spectrum-XGS would've made that actually work.
The technical specifications reveal impressive network performance benchmarks with 400G Ethernet capability and support for RDMA over Converged Ethernet (RoCE). Integration with existing MLflow and Kubeflow pipelines ensures seamless deployment in current AI/ML infrastructure stacks.
Who's Actually Using This Shit
CoreWeave jumped on this immediately. Their CTO Peter Salanki basically said "fuck regional limitations" - they're treating their entire global infrastructure as one massive supercomputer. Smart move, considering they've been competing with AWS and Google on raw GPU access.
Makes sense for CoreWeave specifically. They've been building out data centers fast but hitting power limits in prime locations like Northern Virginia. Now they can put the overflow capacity in cheaper locations (hello, Iowa) and still make it perform like it's all in the same rack.
What This Means for Your Infrastructure
The Big Fucking Deal
Every company running serious AI workloads hits the same wall: power and space limits at their primary data center. Until now, your options sucked:
- Build a massive new facility - 2 year lead time, $500M minimum, good luck finding 50MW of power
- Split workloads manually - works for inference, useless for training
- Accept the limitation - watch competitors with deeper pockets eat your lunch
Spectrum-XGS changes the game. You can buy cheap land in Montana, stuff it full of GPUs, and make them perform like they're sitting in your Silicon Valley facility.
This is especially huge for smaller AI companies. Anthropic paid $4B to Amazon partly because they couldn't get enough concentrated compute. Now they could potentially build distributed infrastructure at 1/10th the cost.
Similar challenges face companies like OpenAI with their Microsoft partnership, Cohere's cloud infrastructure needs, and Stability AI's distributed training requirements. The AI Infrastructure Alliance estimates that 70% of AI companies are infrastructure-constrained rather than talent-constrained.
Bottom Line
If you're running AI infrastructure and hitting facility limits, Spectrum-XGS just removed your biggest constraint. The question isn't whether this will become standard - it's how fast you can get it deployed before your competitors do.
The technology is available now as part of NVIDIA's Spectrum-X platform. No waiting for beta programs or future releases - you can order it today.