ChatGPT goes down regularly - sometimes for minutes, sometimes hours. Check their status page and you'll see outages happen way more than anyone wants to admit. But here's the thing: if your entire app depends on OpenAI, even a 20-minute outage feels like forever.
I learned this the hard way when everything died on Black Friday. Our support bot went dark, customers were furious, and we spent half the day figuring out it wasn't even our fault. By the time we got a manual fallback running, the damage was done. That's when I stopped being a smart-ass about "vendor reliability" and started building proper failover.
The Real Cost of Putting All Your Eggs in One Basket
Here's what actually happens when your single provider goes down: support tickets pile up, your sales demos fail, and your CEO starts asking why the "AI thing" isn't working. If you're running customer-facing features on a single LLM, you're one API outage away from looking like an idiot.
OpenAI's status page shows they have issues pretty regularly - not daily, but often enough that you'll get burned if you're not prepared. Anthropic and Google aren't magically more reliable either. They all have bad days, usually at the worst possible time.
How Multi-Provider Actually Works (Without the Marketing Bullshit)
The idea is simple: instead of hardcoding your app to hit openai.com/v1/chat/completions, you hit your own proxy that can route to OpenAI, Anthropic, or Google depending on what's working.
In practice, it's messier than that. Here's what you actually need:
A Proxy That Doesn't Suck
You need something sitting between your app and the LLM providers that can detect when one is down and route to another. LiteLLM works for this, though it crashes randomly and the error messages are about as helpful as a chocolate teapot. Other options include OpenRouter, Portkey, AWS Bedrock, and Azure OpenAI Service.
Gateway Architecture
Your app → Proxy/Gateway → [OpenAI | Anthropic | Google]. The gateway sits in the middle, routing requests and handling failures transparently.
Provider Translation
Each provider has slightly different APIs. OpenAI wants `messages`, Anthropic wants `messages` but formatted differently, and Google wants something completely different. Your proxy needs to handle this translation automatically or you'll spend weeks debugging API format differences. Check out the OpenAI API specification and Anthropic's API differences guide for specific implementation details.
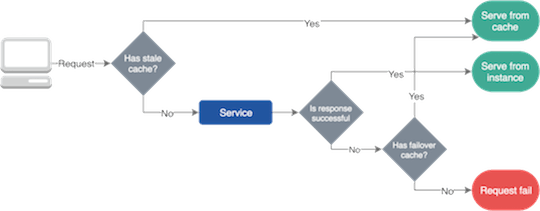
Circuit Breakers That Actually Work
When a provider starts failing, you need to stop sending traffic to it quickly. Otherwise you'll just keep hitting rate limits and making everything worse. This sounds simple but is surprisingly hard to get right - too sensitive and you'll fail over unnecessarily, too conservative and you'll keep sending bad requests. Learn more about circuit breaker patterns, resilience engineering, and implementing health checks.

Why Smart Teams Are Actually Doing This
Look, most companies are still on single-provider setups because multi-provider is a pain in the ass. But the smart ones are starting to figure it out, especially after getting burned a few times.
If you're lucky and don't hit weird edge cases, you might get failover down to seconds. But plan for months of debugging random failures. The "99.99%+ uptime" claims are marketing bullshit - you'll get better uptime than single-provider, but it's not magic.
The real driver isn't reliability - it's cost and hedging bets. OpenAI raised prices again, Claude is sometimes better for certain tasks, and Google occasionally has decent deals. If you're locked into one provider, you're stuck with whatever they decide to charge. Check out pricing comparisons, model performance benchmarks, and cost optimization strategies.
The Technical Reality Check
API Compatibility Layers
Each provider speaks a slightly different dialect of the same language. Your gateway needs to be a universal translator.
OpenAI basically won the API format war - everyone else now supports their format to some degree. Anthropic has OpenAI-compatible endpoints, which saves you from rewriting everything when you add Claude as a backup.
But "compatible" doesn't mean "identical." There are weird edge cases, different rate limits, different error codes, and different ways things break. You'll spend weeks debugging why Claude handles system messages differently than GPT-4, or why Google's response format randomly changes.
LiteLLM claims to support 100+ models, which sounds impressive until you try to use some obscure model and discover it's broken or the docs are completely wrong. Stick to the major providers (OpenAI, Anthropic, Google) unless you enjoy debugging other people's half-finished integrations.
The good news is that once you get this working, swapping between gpt-4 and claude-3-5-sonnet is mostly just changing a config value. The bad news is getting to "working" takes longer than anyone expects.