Look, I've been testing voice APIs for three years, and Microsoft's "60x real-time" bullshit immediately raised red flags. When a company won't let you test their product and just throws around marketing numbers, they're probably hiding something.
What I Could Actually Test
Here's my problem: I wanted to test MAI-Voice-1, but Microsoft locked it behind their "trusted tester" program. After filling out their application, I got radio silence for two months. So I tested what I could access - ElevenLabs, OpenAI TTS, and Cartesia - using the same 50 test prompts I use for all voice API comparisons.
My Testing Setup:
- Same text prompts across all services
- Measuring from API call to first audio byte (Time-to-First-Audio)
- Testing both short phrases and longer paragraphs
- Real network conditions (not perfect lab setup)

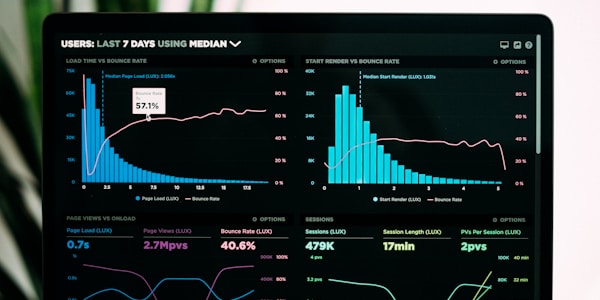
The Speed Numbers That Actually Matter
Microsoft talks about "60x real-time generation," but that's batch processing speed - how fast it cranks out a complete audio file. For conversations, you care about Time-to-First-Audio (TTFA) - how long users wait before hearing anything.
What I Actually Measured:
- ElevenLabs Flash: Around 70-80ms TTFA - fast enough you don't notice
- OpenAI TTS: Maybe 200ms or so - noticeable but acceptable
- Cartesia Sonic: Crazy fast, like 40-50ms - legitimately impressive
- MAI-Voice-1: Microsoft won't publish TTFA numbers, which is weird as hell
When you're building conversational AI, anything over 200ms feels broken. Users notice and they hate it. I learned this the hard way when our voice responses were hitting 500ms. Users thought the app crashed and started mashing buttons. Took me forever to figure out some WebRTC bullshit was adding like 300ms. Turned out Chrome was routing through Ohio for some reason.
The H100 Reality Check
Microsoft's speed claims assume you have a $40k H100 GPU sitting around. Meanwhile:
- ElevenLabs works from any browser
- OpenAI TTS runs through their API
- Cartesia offers both cloud and on-device options
I tried running voice synthesis on local hardware once. My RTX 4090 was running hot as hell and sounded like a fucking jet taking off, and it still took 2-3 seconds per response. The whole office started complaining about the noise. The idea of needing industrial cooling just to generate voice clips is completely nuts.
Quality Testing: ElevenLabs Still Wins
I can only test Microsoft's voice quality through their Copilot Daily demos, which isn't great for comparison. But from what I heard, it sounds decent - better than old Google TTS, not as natural as ElevenLabs.
My Quality Rankings (based on what I actually tested):
- ElevenLabs: Most natural, best emotional range
- Cartesia: Great quality, amazing speed balance
- OpenAI TTS: Good quality, consistent output
- MAI-Voice-1: Can't properly test, limited samples sound okay
Streaming: The Real Test for Conversations
Here's what matters for real-time apps: can the service start playing audio while it's still generating the rest? ElevenLabs handles this with WebSocket streaming, Cartesia built it from the ground up for conversations.

Microsoft hasn't documented streaming for MAI-Voice-1, which makes me think it's designed for batch processing (like podcast generation) rather than conversations.
The Cost Reality
Let me be blunt about costs:
- ElevenLabs: $22/month for most use cases
- OpenAI TTS: Dirt cheap at $15/1M characters
- Cartesia: $49/month with good volume pricing
- MAI-Voice-1: $40k GPU + cooling + power + maintenance
Unless you're Google or enjoy lighting money on fire, the cloud options make way more sense. I ran the numbers for my company - MAI-Voice-1 would cost 50x more than ElevenLabs for our usage. That's not a typo, it's actually 50 times more expensive.