First migration: We dumped 5,000 resources into one massive workspace because "it's easier to manage." Fucking stupid. Plans took 45 minutes. Some developer changed a security group and brought down our entire e-commerce platform at 2 PM on Black Friday. Try explaining that to the board.
The dependency cascades are real. Touch one thing, break everything downstream. We lost two senior engineers that quarter because they got tired of 3 AM calls fixing shit we broke during the day.
How Discover Financial Doesn't Burn Down Production
Discover Financial manages 2,000+ workspaces without constant fires because they figured out the hierarchy that actually works. HashiCorp's workspace organization patterns make sense when you stop trying to put everything in one bucket:
Foundation Layer: 15 workspaces max. Network, IAM, DNS, monitoring. Changes here require VP approval, which means nothing breaks silently at midnight.
Platform Layer: Database clusters, Kubernetes, load balancers. Around 80 workspaces. These can break without killing everything, but you'll get woken up.
App Layer: 300+ workspaces. Each service gets its own workspace per environment. Prod-payments-api-database, dev-auth-service-cache, that kind of naming. Break these all you want during business hours.
Business Unit Hell: 1000+ workspaces when legal makes you isolate everything because of compliance. Each department gets its own sandbox so they can't blame each other when costs spike.
The trick isn't the number of tiers - it's the blast radius. Foundation fucks up, everyone's down. App workspace fucks up, one team has a bad day.
The April 2026 Clusterfuck
HashiCorp killed Terraform Enterprise on Replicated. Support dies April 1, 2026 with the final release in March 2025. They shipped the tf-migrate tool but it's not magic - you're still fucked if you wait until November 2025 to start.
The Migration Tool That Mostly Works:
The tf-migrate tool shipped in March 2025. It's slow as hell for big state files but beats doing it by hand:
## This will take forever and half your workspaces will fail
tf-migrate -target=hcp-terraform \
-organization=my-enterprise \
-workspace-prefix=prod- \
-source-dir=/terraform/workspaces/
## Common error you'll see:
## Error: workspace \"prod-payments-db\" failed: state file too large (>100MB)
## Fix: Split your massive workspaces before migrating
Humana's 12-Month Hell:
Humana wrote about their migration disaster because misery loves company:
- Month 1: "How many workspaces do we have?" "Uh..."
- Month 2: Found 300+ workspaces across 42 teams nobody talked to
- Month 4: Pilot with 5 volunteer teams went smooth (should've been suspicious)
- Month 6: Real teams started bitching about workflow changes
- Month 9: Production migration broke everything twice
- Month 12: Finally stopped getting emergency calls every weekend
What kept them from getting fired: Dynamic credentials stopped the weekly "who rotated the AWS keys?" incident reports. Policy automation caught two teams about to spin up $50K monthly bills. Templates prevented the usual "let's create 47 different ways to deploy a simple API" chaos.
When Your Bill Triples Overnight
RUM pricing (Resources Under Management) is HashiCorp's way of charging per resource instead of per user. Sounds reasonable until your first bill arrives. Our bill tripled overnight because we found a shitload of resources nobody knew about. ControlMonkey's analysis shows 60% of companies blow their budgets in year one.
Current HCP Terraform rates hit $0.10-$0.99 per resource monthly depending on tier. That 10,000-resource deployment? $1,000-$9,900 monthly. Plus the $39-$199 per user base fees. Plus overages when you miscounted. HashiCorp killed the free tier in March 2025, so there's no testing the waters anymore.
What Actually Works to Cut Costs:
Stop Duplicating Shit: Create shared resources once, reference everywhere else. Every duplicate security group costs you monthly.
## Bad: Creates a resource in every workspace (costs multiply)
resource \"aws_security_group\" \"web\" {
name = \"web-sg-${workspace.name}\" # Now you have 50 identical security groups
}
## Good: Reference shared resources (no RUM hit)
data \"aws_security_group\" \"web\" {
name = \"shared-web-sg\" # One security group, referenced everywhere
}
Module Everything: Terraform Registry modules can cut your resource count in half. We went from 300 individual resources to 80 module instances for the same functionality. AWS VPC module replaces 15 individual resources with one module call. Gruntwork's enterprise patterns saved us $40K monthly by consolidating common patterns.
Kill Dev Environments on Weekends: Nobody works weekends anyway. We destroy all non-prod stuff Friday evening, recreate Monday morning. Cut our dev/staging costs by 40%. Until someone forgets to run the Monday script and devs can't work until noon.
## Friday teardown script (runs in CI/CD)
terraform destroy -target=aws_instance.dev_instances -auto-approve
terraform destroy -target=aws_rds_instance.staging_db -auto-approve
## Monday recreation
terraform apply -auto-approve
AWS Lambda scheduled actions can automate this. GitHub Actions cron jobs work too if you're not scared of YAML hell.
Stop Developers from Bankrupting You
Without policies, someone will deploy a p4d.24xlarge instance in production "for testing" and forget about it. AWS bill spiked over a weekend when some data science team forgot about a massive GPU cluster they spun up. Sentinel policies prevent this shit from happening.
The Policies That Actually Save Money:
No GPU Instances Unless You're Rich:
## Block p4d.24xlarge instances that cost $58K monthly
forbidden_instances = [\"p4d.24xlarge\", \"p3dn.24xlarge\", \"x1e.32xlarge\"]
main = rule {
all aws_instance as instance {
instance.instance_type not in forbidden_instances
}
}
S3 Buckets Must Be Encrypted (because auditors):
## Unencrypted buckets fail SOC2 audits
main = rule {
all aws_s3_bucket as bucket {
bucket.server_side_encryption_configuration is not empty
}
}
Tag Everything or Finance Gets Mad:
required_tags = [\"CostCenter\", \"Environment\", \"Owner\"]
main = rule {
all aws_instance as instance {
all required_tags as tag {
instance.tags contains tag
}
}
}
Without these tags, you can't do chargeback accounting and every department blames platform engineering for the cloud bill.
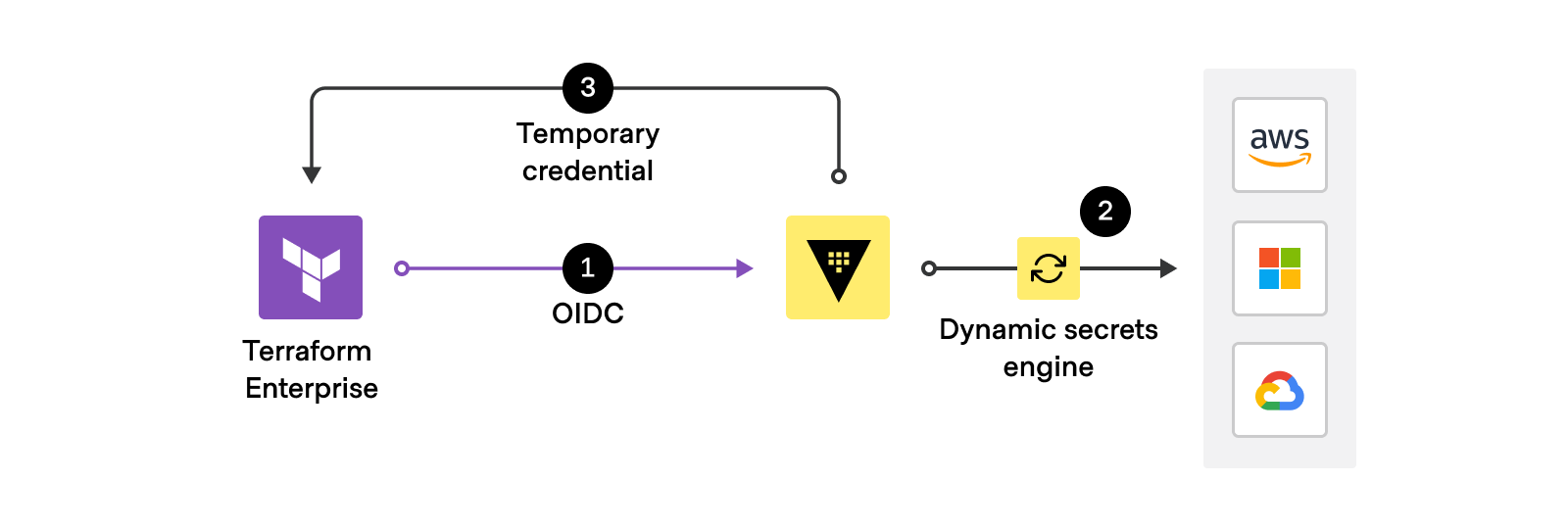
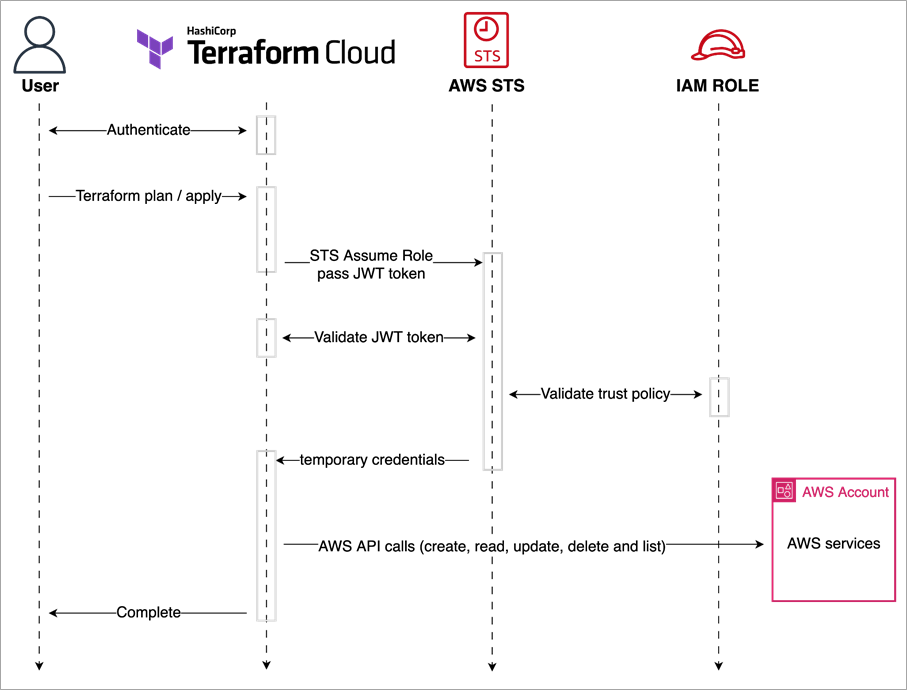
Dynamic Credentials Finally Work
OIDC-based dynamic credentials solve the "who the fuck rotated the AWS keys again?" problem. Instead of quarterly key rotations that break everything, dynamic provider credentials generate short-lived tokens for each Terraform run.
Before dynamic credentials: Every three months, someone rotates service account keys. Half the workspaces break because they're still using the old keys. Platform engineering spends a week fixing deployments that worked last Friday.
After: Tokens last 15 minutes, generated automatically per run. No more key rotation incidents. No more "InvalidAccessKeyId" errors in the middle of deployments.
## OIDC setup that actually works
resource \"aws_iam_role\" \"hcp_terraform\" {
name = \"hcp-terraform-dynamic-role\"
assume_role_policy = jsonencode({
Version = \"2012-10-17\"
Statement = [{
Effect = \"Allow\"
Principal = {
Federated = aws_iam_openid_connect_provider.hcp_terraform.arn
}
Action = \"sts:AssumeRoleWithWebIdentity\"
Condition = {
StringEquals = {
\"app.terraform.io:aud\" = \"aws.workload.identity\"
}
StringLike = {
\"app.terraform.io:sub\" = \"organization:my-org:workspace:prod-*:*\"
}
}
}]
})
}
We went from 12 credential rotation incidents per quarter to zero. AWS dynamic credentials implementation walks through the AWS setup. AWS IAM security best practices covers the OIDC trust relationships. The HCP Terraform tutorials explain multi-cloud setups.
Alternative platforms like Spacelift and Env0 also support dynamic credentials, often with better multi-cloud coverage than HashiCorp's implementation. Platform comparison analysis covers real-world experiences across platforms.