
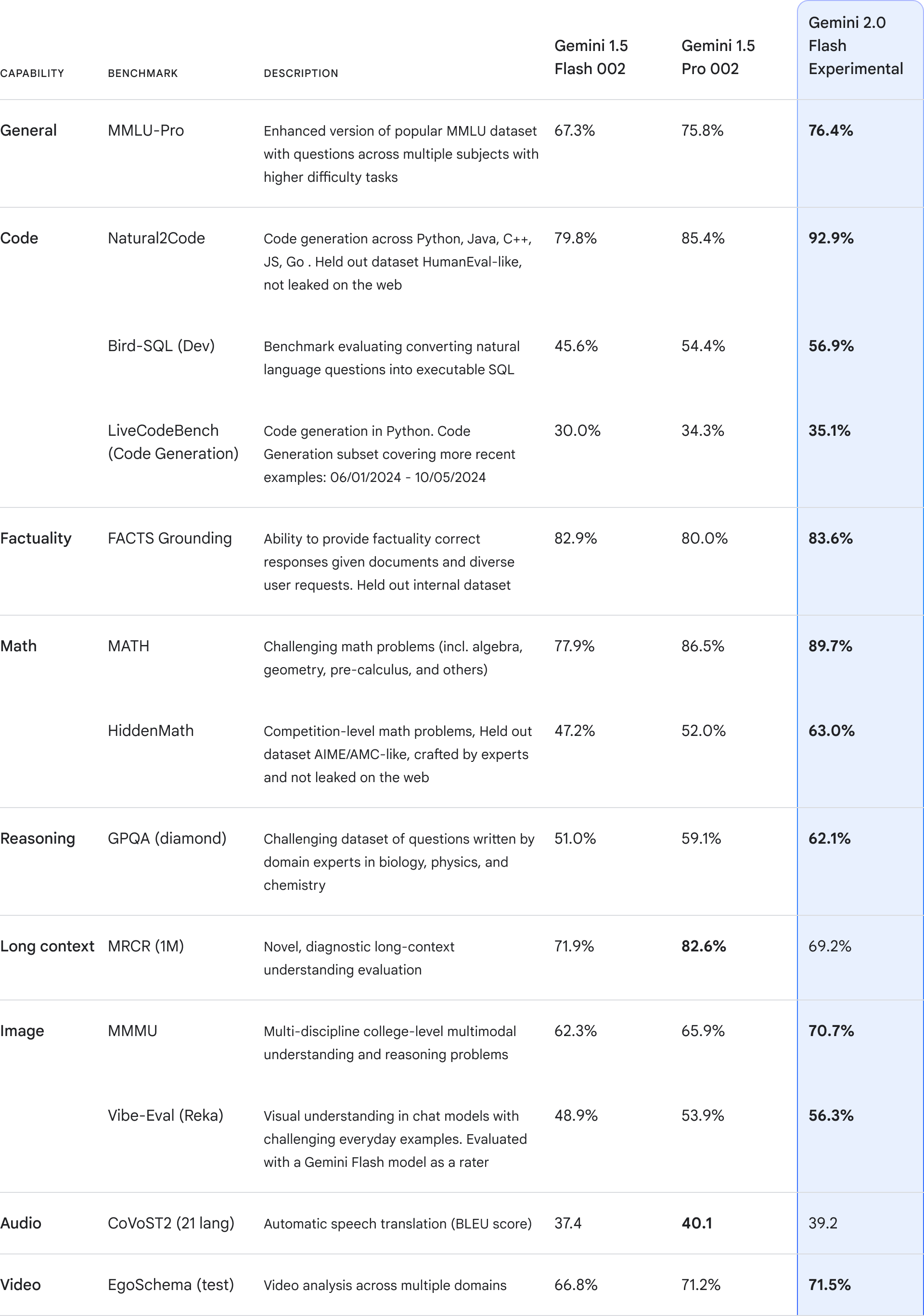
Gemini 2.0 Flash dropped in December 2024 with Google claiming it's "purpose-built for the agentic era" - which translates to "we built tool calling so you can waste hours debugging why it randomly stops working."
The pitch sounds great: native function calls without external frameworks. Reality check: it calls functions with malformed parameters, ignores function calls entirely, or hallucinates functions that don't exist. When it breaks (and it will), you're debugging Google's black box with error messages like "The model is overloaded. Please try again later."
Been there, done that, bought the t-shirt. Spent 6 hours last month debugging why gemini-2.0-flash-001 kept outputting endless streams of dashes instead of analysis results. Turns out feeding it anything larger than a medium-sized document triggers some internal loop that just burns tokens until you hit limits.
What Actually Works (When It Feels Like It)
Native tool calling works about 80% of the time. When it doesn't, you get function calls with parameters like {"query": null} or it just ignores your function definitions entirely. Google Search integration is legitimately useful - no more "I don't have access to current information" responses.
Multimodal outputs are hit-or-miss. The text-to-speech has 500ms-2s latency that makes "real-time" applications feel like dial-up internet. Image generation works for basic graphics but produces weird artifacts - we got pictures of cats with six legs and text that looked like it was written by someone having a stroke. The official API documentation glosses over these edge cases, but GitHub issues tell the real story.
The 1 million token context works until it doesn't. Processing large documents gets exponentially slower and more expensive. Fed our 800K-token codebase into it once - took 45 seconds to respond and cost $320 for a single analysis. Context caching helps if configured right, but get it wrong and you'll double your costs instead of reducing them. The pricing calculator doesn't account for these real-world gotchas.
What Actually Works in Production
Google uses Gemini 2.0 in Search and Deep Research, which gives me some confidence. If it's good enough for billion-user products, it won't completely shit the bed in your app. Just don't expect the same reliability you get from their mature services.
The experimental stuff like Project Astra is pure demo magic. Project Mariner and Jules are vaporware until proven otherwise. Focus on what's actually available in the Vertex AI API or Google AI Studio.
Performance Reality Check (With Actual Numbers)
Google claims 2x speed improvement, but that's cherry-picked benchmarks. Real-world experience: simple text completions are fast (~2 seconds), multimodal processing takes 5-15 seconds, and anything requiring the Live API might hang forever.
The pricing is genuinely competitive at $0.10/$0.40 per million tokens, but watch out for hidden costs. Video processing eats tokens like crazy, context windows scale linearly with cost, and free tier rate limits hit faster than a drunk driver on black ice.
When this breaks (and it will), the Google DeepMind research papers have the technical details, Hugging Face model cards show implementation specifics, ArXiv papers provide research context, and Reddit discussions show you what's actually broken in production. The Google AI Blog puts a positive spin on everything, while Hacker News threads provide unfiltered developer opinions.



