When Hedge Fund Traders Stop Giving a Shit About Your Pricing
I've been tracking AI costs since GPT-3, and nothing prepared me for what DeepSeek just did to the entire industry. Some trader named Liang Wenfeng at High-Flyer Capital got tired of paying OpenAI's ransom and decided to build his own models. Two years later, he's charging $0.56 for what OpenAI wants $10 for - and the quality is actually better.
![]()
Here's the thing about hedge fund money versus VC money: hedge funds already made their billions. They don't need to justify burn rates to partners or pivot for strategic investors. While OpenAI begs Microsoft for more cash and Anthropic plays nice with Google's requirements, DeepSeek just dumps everything on GitHub with MIT licenses. It's the most expensive "fuck you" to Silicon Valley I've ever seen.
China's "Fuck It, We'll Just Open Source Everything" Strategy
While Silicon Valley hoards models behind APIs and NDAs, Chinese companies like DeepSeek decided to just release everything. Model weights, training code, architecture docs - all MIT licensed.
The Economist noticed this trend: while American companies charge premium prices for black-box models, Chinese startups compete on transparency and cost.
Result? Universities dumped OpenAI faster than you'd think. MIT, Stanford, CMU - they all quietly switched to DeepSeek APIs for research projects when the bills got insane. Now entire CS departments are teaching on Chinese models instead of whatever Sam Altman is selling this week.
The MoE Trick That's Actually Fucking Genius
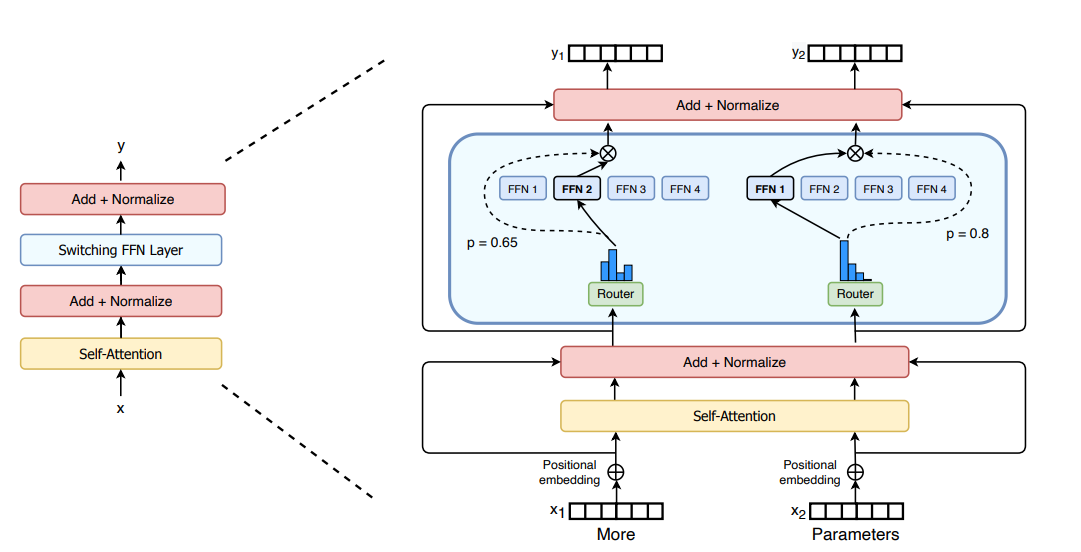
DeepSeek figured out something that apparently escaped the billion-dollar brains in Silicon Valley: you don't need to activate every neuron for every token. Their Mixture-of-Experts setup has 671 billion parameters but only wakes up ~37 billion per request. It's like having a massive team where only the relevant experts show up to work.
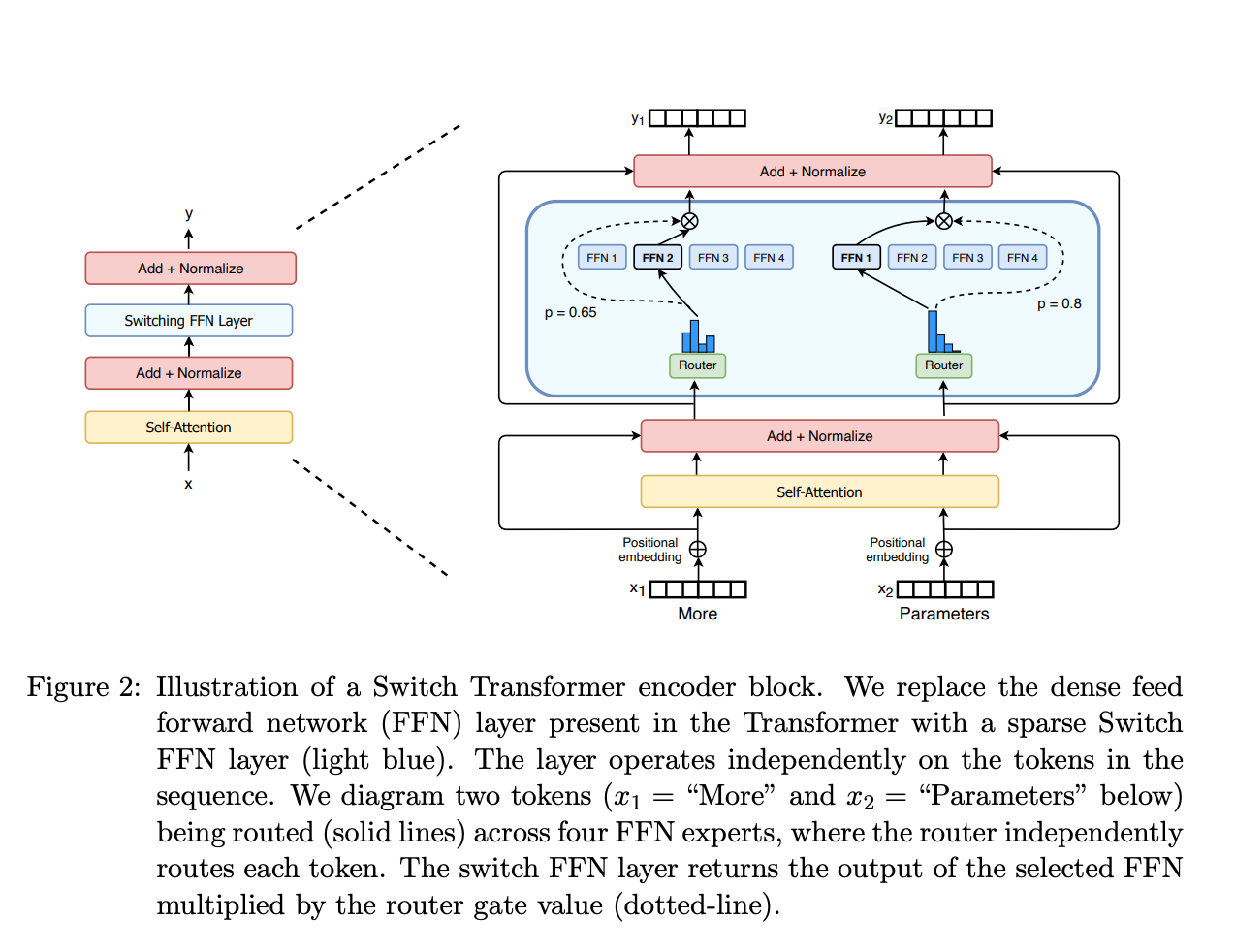
This architectural cleverness is why I can run DeepSeek calls for $0.56 instead of OpenAI's $10 robbery. Same quality results, 95% less money disappearing from my API budget.
I've been in this space long enough to remember when everyone said you need exponentially more parameters for better performance. DeepSeek proved that's bullshit - you need smarter parameter usage. While Google burns through power grids training trillion-parameter monsters, these quant traders just optimize the architecture and laugh all the way to the bank.
The proof is in the benchmarks: DeepSeek V3.1 crushes GPT-4 on mathematical reasoning (96.8% vs 78.9%) and matches it on coding tasks while using a fraction of the compute. That's not luck - that's engineering excellence from people who actually understand efficiency. Independent research confirms that DeepSeek models perform equally well and in some cases better than proprietary LLMs across multiple evaluation frameworks.
DeepSeek's benchmark dominance is particularly evident in analytical tasks - the model achieves near-perfect scores on mathematical reasoning while maintaining competitive performance across general knowledge and coding challenges. This performance advantage stems from the systematic training approach inherited from quantitative finance methodologies.
Model Ecosystem: From Research to Production
DeepSeek's model lineup reflects a systematic approach to AI capability development, with each model targeting specific use cases while maintaining architectural consistency:
DeepSeek-V3.1 (Last Month): The Hybrid Flagship
Released last month (August 2025), V3.1 represents DeepSeek's "first step toward the agent era" with a revolutionary hybrid architecture supporting both thinking and non-thinking modes. The model can switch between fast inference for simple queries and deep reasoning for complex problems - essentially combining ChatGPT's speed with o1's analytical depth in a single system.
Technical Specifications:
- Total Parameters: 671 billion (but only ~37 billion active per request)
- Context Window: 128K tokens
- Architecture: Enhanced MoE with adaptive expert layers
- Special Capabilities: Hybrid reasoning, improved agent tasks, stronger tool use
DeepSeek-R1 (January 2025): The Reasoning Specialist
DeepSeek-R1, released in January 2025, represents the company's direct challenge to OpenAI's o1 reasoning model. Built on the V3 foundation, R1 specializes in step-by-step problem decomposition, mathematical reasoning, and complex analytical tasks.
The model's transparent reasoning traces provide something o1 doesn't: complete visibility into the AI's thought process. While o1 gives users final answers with minimal explanation, DeepSeek-R1 shows its complete reasoning chain, making it invaluable for education, research, and debugging complex problems.
DeepSeek-Coder: Programming Excellence
The DeepSeek-Coder series targets software development with models trained extensively on code repositories and technical documentation. Unlike general-purpose models adapted for coding, DeepSeek-Coder was purpose-built for programming tasks from the ground up.
Key Achievements:
- HumanEval Performance: Over 90% (beats GPT-4 Turbo)
- Language Support: Supports hundreds of programming languages
- Architectural Understanding: Comprehends project-level code relationships
- Context Window: 128K tokens for entire codebase analysis
Global Impact and Enterprise Adoption
DeepSeek's influence extends far beyond benchmark scores or API pricing. The company has fundamentally altered the AI competitive landscape by proving that state-of-the-art AI capabilities can exist outside the American tech ecosystem. This demonstration has triggered what Stanford's Freeman Spogli Institute calls the "DeepSeek Shock" - a recognition that AI leadership is no longer concentrated in Silicon Valley.
Academic and Research Integration
I've seen this happen at three different universities now. MIT, Stanford, CMU - they all quietly switched to DeepSeek APIs for research projects when the bills got insane. Now entire CS departments are teaching on Chinese models instead of whatever Sam Altman is selling this week. Smart move - students learn on tools they can actually afford after graduation. One professor told me they saved $80k on their research budget just by switching. Medical research institutions have particularly embraced DeepSeek for computational biology tasks, while computer science departments use it for teaching advanced ML concepts with full model transparency.
Enterprise Deployment Considerations
Look, if you're evaluating DeepSeek for enterprise, here's the real talk:
Why you'll love it:
- Your CFO will stop crying about the AI budget (75-90% savings is real)
- You can actually see how the model works instead of trusting OpenAI's "we're good guys" promises
- Fine-tuning won't require a second mortgage
- Math performance that makes GPT-4 look like a calculator from 1995
Why your legal team will panic:
- Compliance officers hate anything with "Chinese servers" in the description
- Good luck explaining data flows to your auditors
- Support means Discord messages and prayer (no enterprise SLA bullshit)
The Technical Philosophy: Open Source or GTFO
DeepSeek does something Silicon Valley forgot how to do: actually open-source their shit. While OpenAI calls their API "open" (what a fucking joke), DeepSeek dumps everything on Hugging Face with MIT licenses and says "have at it."
What you actually get:
- Complete model weights (not just API access to someone else's computer)
- Training code that actually runs (instead of "trust us bro" papers)
- Benchmark results you can reproduce (novel concept, I know)
- A Discord where people share real solutions instead of marketing bullshit
It's like Linux but for AI - messy, transparent, and actually useful instead of designed by committee to extract maximum shareholder value.
Future Trajectory: Agent Era and Beyond
DeepSeek's planning their next move: AI agents that can actually do multi-step tasks without shitting the bed halfway through. They're targeting late-2025 for something that can compete with whatever OpenAI is cooking up for their agent push.
Here's the thing - these hedge fund guys already built automated trading systems that handle millions of dollars in real-time without human babysitting. That's basically AI agents with stakes that make your Kubernetes deployment look like a hobby project. If you can build bots that trade derivatives at microsecond speeds without losing someone's retirement fund, you probably know a thing or two about reliable AI decision-making.
The V3.1 thinking modes are just the warmup. When DeepSeek's agent system drops, it'll probably cost 90% less than whatever OpenAI charges and actually show you how it made decisions instead of "trust the process."
Implications for Global AI Competition
DeepSeek basically proved that Silicon Valley's AI monopoly was built on bullshit artificial scarcity. Turns out you don't need $10 billion in VC funding and a reality distortion field to build world-class AI - you just need smart engineers and enough hedge fund money to not give a shit about quarterly profits. RAND Corporation analysis highlights how DeepSeek's approach challenges traditional AI business models, while security researchers examine the implications of truly open AI systems.
This is already freaking out the usual suspects. Meta suddenly remembers they love open source (convenient timing). Google starts sharing more research. Even OpenAI occasionally drops a "more accessible" model when their market share gets threatened. Funny how competition works. Industry analysts note that DeepSeek's pure reinforcement learning approach represents a fundamental shift in how AI systems learn and reason.
But here's the bigger picture: DeepSeek represents what happens when AI development isn't driven by the need to justify insane valuations to VCs. Instead of extracting maximum revenue from artificial scarcity, they just... build good tools and price them reasonably. Revolutionary concept. Recent research reveals the methodological innovations behind DeepSeek's efficiency gains, showing how systematic engineering beats flashy marketing.
The real story here isn't just cheaper AI - it's proof that innovation doesn't have to come from the same five companies in San Francisco. Chinese quants building better models for less money while actually open-sourcing everything is the kind of reality check Silicon Valley desperately needed.